







一、首先来看一下静态路由协议个动态路由协议的区别:
静态路由:这种路由由网络管理员手动输入路由器命令管理。缺点:需要手工指定,网络过大无法使用。
动态路由:这种路由由网络路由协议根据拓扑或流量改变而自动调整。缺点:容易占用网络带宽。
当路由器数量少的时候建议使用静态路由,当路由器数量多的时候建议使用动态路由。
二、路由协议分为两种也叫做自治系统:
自治系统是通用管理域中的网络的集合
内部网关协议在自治系统中工作
外部网关协议连接不同的自治系统
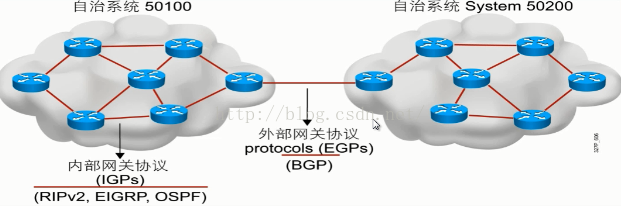
1.内部网关路由协议:RIP\EIGRP\OSPF
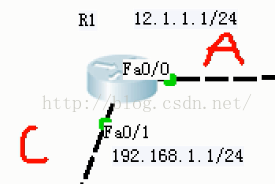
而我们通常所说的AS就是指的一组或者一片由管理员来管理的路由器。(比如上图中的左半个区域)
2.外部网关路由协议:BGP
三、内部动态路由协议的类型
1.距离矢量 RIP、IGRP
2.高级距离矢量EIGRP(cisco私有的)
3.链路状态 OSPF IS.IS
距离矢量:
“距离”表示有多远,经过几台路由器,经过几跳。
“矢量”表示在哪个方向上,从哪个接口转发出去。
距离矢量路由协议会隔一定时间将路由表里的所有路由传给自己的邻居。周期的。
四、RIP的工作原理:
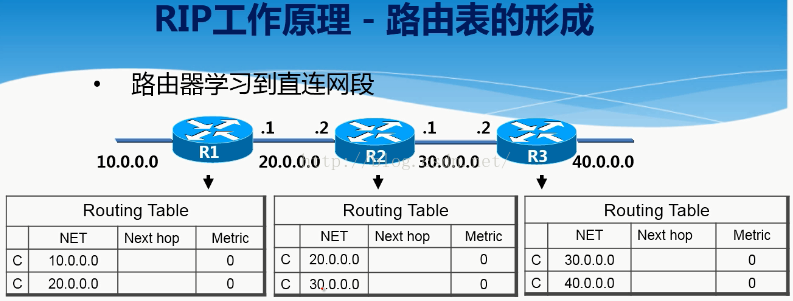
1.首先路由器会先学习到自身所在的直连网段的路由信息。
2.当运行RIP动态路由协议的时候,路由器会每隔30秒向邻居(指的是直接相连的路由器)发送路由表。
但是在发送之前,会把路由信息的Metric值+1之后传给邻居。
For example:net next metric
10.0.0.0 0+1
20.0.0.0 0+1
Metric叫做度量值,是衡量一条路由好坏的一个参数。
如果是相同路由的情况下,必须要传过来的metric值比自己的小才可以学习,否则是不学习的。比如R1传给R2的“20.0.0.0 metric 1”的这条路由,R2自己的路由表里面有一条20.0.0.0的路由,且metric值为0,明显比R1传过来的小,所以是不学习这条路由的。Metric值越小,优先级就越高。而R1同时传过来的10.0.0.0的路由在R2里面是没有的,所以它会学习过来。
那么接下来,轮到R2传给邻居路由了,R1和R3会同时收到R2传过来的路由信息。当然传出之前metric值还是会加1. Net next metric
C 20.0.0.0 0+1
C 30.0.0.0 0+1
R 10.0.0.0 20.0.0.1 1
那么同样的因为R2传给R1的20.0.0.0的metric值是1比R1本身的20.0.0.0的metric值大,所以R1也是不学的。所以只会把自身没有的30.0.0.0 加入到自己的路由表里面。即:“R 30.0.0.0 20.0.0.2 1”
当R2传给R3的时候,同样30.0.0.0的路由不学习,而只学习“R20.0.0.0 30.0.0.0 1”这条路由。
当R3的周期更新时间到了以后,也会把自己的路由信息metric值加1之后传给邻居R2。那么R2就学到了“R 40.0.0.0 30.0.0.0 1”这条路由。
最后到下一个30秒的更新周期的时候,R1又会把自己的路由信息传给邻居R2,而因为三个网段的路由信息R2都有,且三个网段的metric值都大,分别为“1 1 2”所以R2不学,然后R2传给R1的时候,R1就学到了“R 40.0.0.0 20.0.0.2 2”的路由。
R3也同理如此。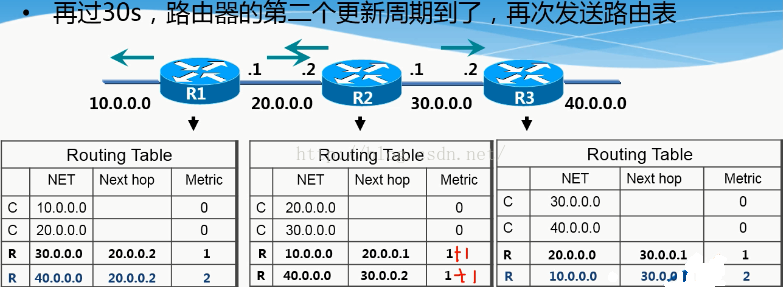
传送路线图:
第一个30秒:R1传到R2
R2传到R1、R2传到R3
R3传到R2
第二个30秒:R1传到R2
R2传到R1、R2传到R3 到这里三台路由器的路由表就一样了。
RIP路由的缺点:
1.计数至无穷大然后出现路由环路。
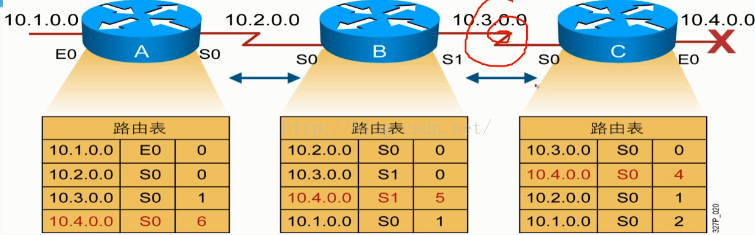
当10.4.0.0的链路down掉的时候,C的路由周期更新时间30秒到了,就会表示为disable。但是这个时候的B的路由周期更新时间还没有到30秒,这个时候,B路由就会发送自己的更新路由给C,而C因为标记了disable,就没有了10.4.0.0的这条路由信息,所以当B传给C的时候,它就会学到这条原本是已经down掉的路由信息。然后当C的路由周期更新时间到的时候,就又会传路由给B,这样就会形成一个环路,B不停的给C传,C又不停的给B传,而它们的metric值因为在每次传之前都会加1,所以会慢慢的越来越大,至无穷大。
为了解决这样的问题:
1.设置路由的最大跳数:为路由跳数作限制。所以RIP的最大跳数是15跳,16跳就不可达了。
所以RIP路由只支持15台路由器,超过15台路由器,就不可用了。
(因为会在第15台路由上的路由表的metric值标记为16,表示后续不可达。这样就不会出现路由环路了。)
2.水平分割:从一个接口学到的路由,不会再把这条路由从这个接口转发出去。
比如,B从C学到的路由10.4.0.0的路由是从S1口接收进来,那么就不会再把这条路由从S1口转发给C。
这样也不会造成路由环路。
3.路由毒化和毒性反转:路由器将已经断开的路由的距离通告为无穷大。当C发现10.4.0.0的路由down了也就是中毒了,就会在自己的路由表里面标记这条路由为infinite(无限大),然后立刻用更新包将这条标记的信息转发给B,B这时候就会在自己的路由表里面也标记为is impossible down,然后会忽视水平分割,转发给C这条标记为is possible down的路由信息。这样也会防止路由环路。
4.抑制计时器:路由器为网络中的“可能有故障”状态保留条目,以便为其他路由器重新计算拓扑更改留出时间。当C发现10.4.0.0这条链路down掉的时候,立刻会向B发送一条不可达的信息,当B收到这跳信息的时候,会开启抑制计时器,也就是180秒,实际上也只是用到60秒,那么在这60秒内,如果收到一条关于10.4.0.0的次优先级的路由,那么B是不学习的。(如果原来自己的路由表里面10.4.0.0的metric值是3跳,而收到的关于10.4.0.0的路由metric值4跳还比自己本身的大,是不学的。如果这条新学到的关于10.4.0.0的路由的metric值是2,比自己原来的这条路由metric值3还小,那么就会学习这条小的,而替换掉自己原来的那条路由。)那么当然,如果在这抑制计时器的60秒,这条10.4.0.0的路由又恢复了,那么继续启用这条路由。
5.触发更新:路由表发生变化时,路由器发送更新。默认的端口S1和S0触发更新是开启的,当发现10.4.0.0的这条链路down掉的时候,是不会等待30秒等周期更新时间的,而会立刻发送一个更新包给B。这样也可以有效的来抑制路由环路。
路由协议的版本:
RIP v1:
-发送路由更新时不携带子网掩码,属于有类路由协议,不支持子网划分。
-发送路由更新时,目标地址为广播地址:255.255.255.255
-在主网边界的自动汇总是无法关闭的。
RIP v2:
-发送路由更新是携带子网掩码,属于无类路由协议,支持子网划分。
-发送路由更新时,目标地址为组播地址:224.0.0.9
-可以关闭主网边界的路由自动汇总。
RIP在主网边界会自动汇总:
所以如果是做过子网划分的网络在学习路由的时候,学的都是主网段路由。
比如:应该学到23.1.1.0/24的路由,到最后查看路由表的时候却是23.0.0.0/8主网段路由。那其实这是
汇总之后的路由。
主网边界:分两种情况
1.比如后边这张图,路由器左边是C类地址,右边是A类地址,那么这个路由器就是主网边界路由。
也就是说两边地址类型不一样的主网边界。
2.两边地址不连续的也是主网边界。如图:R2左边的是12网段,右边的是23网段。
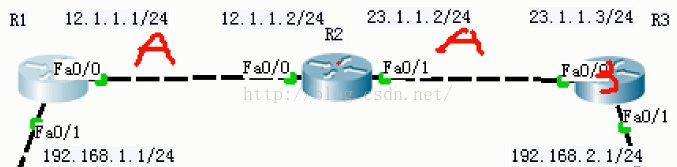
如果4个网段的IP地址都是
连续的话,那么它是不会自动汇总的。

120就是RIP的管理距离值,而静态路由的管理距离值是1。
跳数metric值1就是值到达23.0.0.0的网段只需用经过1跳就可以到达。
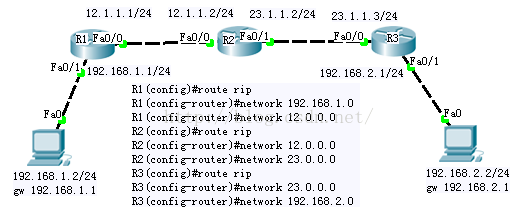
开启动态路由命令:
R1(config)#route rip
进行网段通告命令:
R1(router-router)#network192.168.1.0
R1(config-router)#network 12.0.0.0
查看路由表:
R1#show ip route
清除路由表:
R1#clear ip route * “*”代表所有
Debug看到的结果是动态的。由于会占用路由器资源,所以慎用。
抓取数据包命令:
R1#debug ip rip
关闭抓取数据包命令:
R1#undebug all
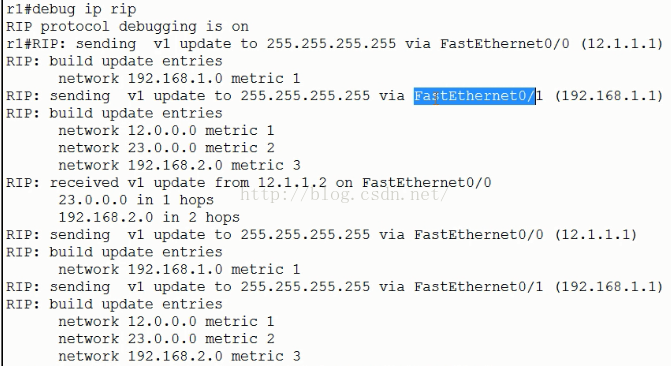
右图就是抓取的实时动态更新包的信息:
Sending v1 update to255.255.255.255 via Fastethernet0/0 (12.1.1.1)
意思是:rip的v1版本发送了一个广播更新包,出接口是f0/0,出接口地址是12.1.1.1。
255.255.255.255 表示广播
RIP:build update entries 构建更新条目
Network 192.168.1.0 metric 1 通告192.168.1.0网段,跳数是1跳。
RIP: reveived v1update from 12.1.1.2 on Fastethernet0/0 从12.1.1.2接收到一个更新包,12.1.1.2的出接口是f0/0.
23.0.0.0 in 1 hops 23网段过来经过1跳,也就是“1 hops”
192.168.2.0 in 2 hops 192.168.2.0网段过来经过2跳,也就是“2 hops” “hops”---啤酒花的意思。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
查看当前路由协议状态:
R1#show ip protocols
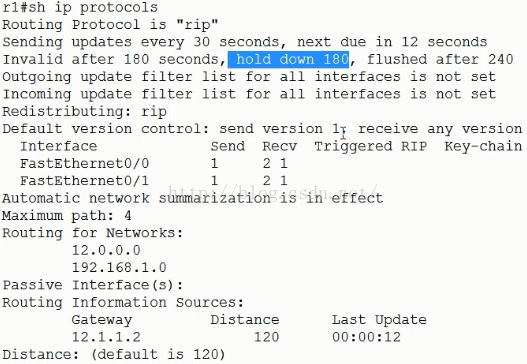
“RIP”当前路由协议
“invalid after 180 seconds”无效计时器180秒
“hold down 180”抑制计时器180秒,
“flushed after 240”刷新计时器240秒,240秒后刷新路由信息。
“Automatic network summarization is in effect”边界路由自动汇总已经起作用
“Maximum”支持4条等价负载均衡(最大可以达到16条)
当发现链路down了,不会立刻丢弃路由信息而会等待180秒,如果到180秒链路还是没有恢复,那么会再等待60秒,如果在这60秒内链路恢复了,那就继续正常使用,如果60秒以后还没有恢复,那么就到了180+60=240秒了,这个时候路由信息就被刷新丢弃了。
基于rip v2版本的路由框架:
如果将两个计算机的ip地址都换成同一主网的ip地址。
那么172.16.1.2是ping不通172.16.2.2的,而且如果在R2上面分别ping172.16.1.2和ping172.16.2.2,开debug就可以看到,实际上R2转发出去的更新包是一左一右的,也就是一个发左边,一个发右边。这样就会造成丢包的现象
“!.!.!”。因为,无论是172.16.1.2还是172.16.2.2它们到主网边界进行路由汇总的时候,都是一条主网路由“172.16.0.0”而这个时候让R2在去转发ping的数据包,会不确定往左边还有右边发,最后为了实现负载均衡,就会左边发一个右边再发一个的重复来完成。
那么如何来让它们完全不丢包呢?
1.首先就需要将现在使用路由协议rip v1版本更换成rip v2版本。
2.然后关闭主网边界的路由自动汇总功能。(rip v1版本无法关闭主网边界的路由自动汇总)
3.最后就可以再去ping,得到的结果就是“!!!!!”也就完全ping通,而不会丢包
因为,当关闭主网边界路由的自动汇总以后,在R1、R2、R3的路由表里面的路由信息,就会出现有掩码的路由条目,这样按地址转发,当然就能准确找到目标地址。

开启动态路由RIP:
R1(config)#router rip
更改RIP版本:
R1(config-router)#version 2 (只有rip v2的版本才可以关闭主网边界自动汇总,而默认开启的rip路由是v1)
关闭自动主网边界自动汇总:
R1(config-router)#noauto-summary
路由通告:
R1(router-router)#network192.168.1.0 (如果是子网划分的路由条目,要通告主类路由“172.16.0.0/12.0.0.0“)
产看当前路由协议信息:
R1#show ip protocols
开启debug: 关闭debug:
R1#debug ip rip R1#undebug all
清除路由表:
R1#clear ip route *















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









