









基本概念
1.结构
首先来看它的继承结构:

再来看看它的结构图,HashTable 是基于哈希表(hash table)实现的map。而哈希表的组成是一个数组,而数组的元素是则单向链表的首节点。

2.特点
线程安全,并且不允许 key 或 value 为 null 。
与 HasMap 的底层结构相同,不同的是:
HashMap 允许 key,value 为 null;
HashMap 的初始容量必须为 2 的倍数,而 HashTable 只要求不为 0 即可;
关于数组索引位置的计算公式不同。
3.初始容量 和加载因子
Hashtable 的实例有两个参数影响其性能:初始容量 和加载因子。
容量,是哈希表中桶(bucket)的数量,初始容量 就是哈希表创建时的容量。在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。
初始容量,主要控制空间消耗与执行 rehash 操作所需要的时间损耗之间的平衡。如果初始容量大于 Hashtable 所包含的最大条目数除以加载因子,则永远 不会发生 rehash 操作。但是,将初始容量设置太高可能会浪费空间。
加载因子,是对哈希表在其容量自动增加之前可以达到多满的一个尺度。
默认加载因子(.75),在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
源码分析
1.节点
HashTable 中存放的元素,也称节点,由 Entry 构成。结构如图所示:
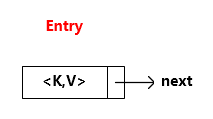
观察它的构造函数,是由 h(哈希值),key(键),value(值),Entry(下一个节点)这几个参数组成。
通过 key-value 构成了 map 的 映射关系
通过 Entry (即 next)连接它的下一节点,构成了单向链表
private static class Entry<K, V> implements Map.Entry<K, V> {
int hash;
K key;
V value;
Entry<K, V> next;
// 构造函数
protected Entry(int hash, K key, V value, Entry<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// 计算哈希码值
public int hashCode() {
return hash ^ (value == null ? 0 : value.hashCode());
}
//....省略剩余方法
}2.构造函数
观察代码构造函数 ①~③ 都调用了构造函数 ④ 。
而该方法主要完成了参数的初始化(loadFactor,threshold)以及数组(table [])的创建工作。
注意:在 HashMap 中,初始化容量(initialCapacity) 必须是 2 的倍数,而 HashTable 只要求不为 0 即可。
// 内部数组
private transient Entry[] table;
// 加载因子
private float loadFactor;
// 临界值
private int threshold;
// 实际存放元素个数
private transient int count;
// 修改次数
private transient int modCount = 0;
// ①
public Hashtable() {
this(11, 0.75f);
}
// ②
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
// ③
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2 * t.size(), 11), 0.75f);
// 添加 map 的所有映射(在添加操作会介绍)
putAll(t);
}
// ④ --> 负责具体实现
public Hashtable(int initialCapacity, float loadFactor) {
// 检查参数的合法性
if (initialCapacity < 0) {
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
}
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("Illegal Load: " + loadFactor);
}
// 在 HashMap 初始化容量必须为 2的倍数
if (initialCapacity == 0) {
initialCapacity = 1;
}
// 初始化参数,并创建数组
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int) (initialCapacity * loadFactor);
}3.添加操作(putAll,put)
这里提供了两种了添加方式, putAll 会去遍历指定 map 的所有 key-value,然后再调用 put 将其逐个添加进哈希表。因此重点来看 put 的工作流程,如下图所示:

判断 value 是否为空,为空抛出。与 HashMap 不同, 在 HashTable 中不允许空值,而 HashMap 则允许。
计算 key-value 在哈希表中的位置。同样,这里的计算公式也与 HashMap 有差别。
找到该位置的节点(table 数组中存放的都是单链表的首节点),遍历操作。
比较 key,存在则替换 key;
不存在,先扩充容量。再添加 key-value 作用新的首节点。
//添加指定的 map
public synchronized void putAll(Map<? extends K, ? extends V> t) {
// 遍历 Map 的映射关系
for (Map.Entry<? extends K, ? extends V> e : t.entrySet()) {
// 添加一个映射关系
put(e.getKey(), e.getValue());
}
}
//添加单个映射关系
public synchronized V put(K key, V value) {
// 与 HashMap 不同,不允许 value 为空
if (value == null) {
throw new NullPointerException();
}
Entry tab[] = table;
// 与 HashMap 计算方式不同,计算得到数组的索引位置
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// 遍历该位置的单链表
for (Entry<K, V> e = tab[index]; e != null; e = e.next) {
// 存在相同的 key,替换 value,并返回旧值
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若不存在相同的 key,扩充完容量,并重新计算索引值
modCount++;
if (count >= threshold) {
// 扩充容量
rehash();
tab = table;
// 重新计算索引位置
index = (hash & 0x7FFFFFFF) % tab.length;
}
// 添加新节点为首节点
Entry<K, V> e = tab[index];
tab[index] = new Entry<K, V>(hash, key, value, e);
count++;
return null;
}
// 调整 HashTable 的容量,=(旧容量*2+1)
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
// 扩充容量
int newCapacity = oldCapacity * 2 + 1;
// 创建新数组
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int) (newCapacity * loadFactor);
table = newMap;
// 复制元素到新数组
for (int i = oldCapacity; i-- > 0;) {
for (Entry<K, V> old = oldMap[i]; old != null;) {
Entry<K, V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}4.删除操作(remove,clear)
同样有两种删除操作。重点来看下 remove 。观察代码,发现与 put 的流程相似。不同的是 put 是添加/修改,而它是删除。
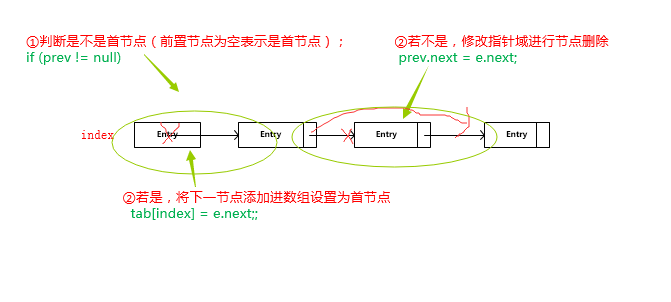
这里来分析删除操作,即从单链表中移除节点的具体流程:
首先要判断是不是首节点
若是首节点的话,则将它的下一节点设为数组元素(因为在数组中存在的都是单链表的首节点)。并将该节点置空,等待 gc 回收。
若不是,则需要修改该节点前置节点的指针,将其指向该节点的下一节点。如下图所示:
// 移除指定的映射关系
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K, V> e = tab[index], prev = null; e != null; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
// 判断该节点是不是首节点
if (prev != null) {
// 若不是,修改指针域
prev.next = e.next;
} else {
// 若是,将下一节点添加进数组设置为首节点
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
// 清空操作
public synchronized void clear() {
Entry tab[] = table;
modCount++;
for (int index = tab.length; --index >= 0;) {
tab[index] = null;
}
count = 0;
}5.查询操作(get,containsKey,contains)
观察 get 与 containsKey 的代码,发现二者的代码基本相同。甚至与 remove,put 也相差不大。
都遵循了[计算哈希值 -> 计算索引位置 -> 遍历单链表 -> 判断 key 是否相同 -> …] 这几个步骤。
因此这里重点来看下 contains 方法,它与 get,containsKey 不同。由于不能通过 value 得到数组的索引位置,只能遍历整个哈希表的元素(节点)。
因此它的步骤是 [判断是否为空 -> 遍历数组 -> 遍历单链表 -> 比较 value是否相同 -> …]
// 根据 key 找到对应的 value
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K, V> e = tab[index]; e != null; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
// 判断是否包含指定的 key
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K, V> e = tab[index]; e != null; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
// 判断是否包含指定的 value
public synchronized boolean contains(Object value) {
// 不允许 value 为空
if (value == null) {
throw new NullPointerException();
}
Entry tab[] = table;
// 从后向前遍历数组(因为不能从 value 计算中节点在哈希表中的位置 )
for (int i = tab.length; i-- > 0;) {
for (Entry<K, V> e = tab[i]; e != null; e = e.next) {
// 与 key 不同,只比较值
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}6.遍历操作(entrySet,keySet,values)
分别实现了对 Entry(节点),key,value 的遍历操作。
以 entrySet 为例,该方法通过 Collections 的同步方法创建了一个 Hashtable.EntrySet(内部类) 的实例;
相应的 keySet ,values 分别创建了 Hashtable.KeySet,Hashtable.AbstractCollection 的实例。
private transient volatile Set<Map.Entry<K, V>> entrySet = null;
public Set<Map.Entry<K, V>> entrySet() {
if (entrySet == null) {
entrySet = Collections.synchronizedSet(new EntrySet(), this);
}
return entrySet;
}以 Hashtable.EntrySet 为例子,重点来看它的 iterator 方法。
private static final int KEYS = 0;
private static final int VALUES = 1;
private static final int ENTRIES = 2;
private class EntrySet extends AbstractSet<Map.Entry<K, V>> {
// 迭代器
public Iterator<Map.Entry<K, V>> iterator() {
return getIterator(ENTRIES);
}
//...省略部分代码
}在三个内部类的 iterator 方法中都调用 getIterator 方法来创建迭代器,通过传入的 type 区分类型。
在 getIterator 中,首先会判断哈希表的元素个数。若为 0,返回 HshTable.EmptyIterator;不为 0,返回 HshTable.Enumerator。
private static Iterator emptyIterator = new EmptyIterator();
private <T> Iterator<T> getIterator(int type) {
if (count == 0) {
return (Iterator<T>) emptyIterator;
} else {
return new Enumerator<T>(type, true);
}
}下面来分析下 Enumerator 的源码,当它表示迭代器时可以操作 next,hasNext ,remove方法;当它表示枚举类时,不能操作 remove 方法。
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
Entry[] table = Hashtable.this.table;
int index = table.length;
Entry<K, V> entry = null;
Entry<K, V> lastReturned = null;
int type;
// Enumerator是 “迭代器(Iterator)” 还是 “枚举类(Enumeration)”的标志
// 为true,表示它是迭代器;否则,是枚举类
boolean iterator;
// 在将Enumerator当作迭代器使用时会用到,用来实现fail-fast机制。
protected int expectedModCount = modCount;
// 构造函数
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
// 关键--> 判断迭代器是否还有数据
public boolean hasNext() {
return hasMoreElements();
}
public boolean hasMoreElements() {
Entry<K, V> e = entry;
int i = index;
Entry[] t = table;
// 从后向前遍历数组元素
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
}
// 关键 --> 取得下一个节点
public T next() {
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
return nextElement();
}
public T nextElement() {
Entry<K, V> et = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
Entry<K, V> e = lastReturned = entry;
entry = e.next;
return type == KEYS ? (T) e.key : (type == VALUES ? (T) e.value : (T) e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
// 移除当前迭代的节点
public void remove() {
// 当该类表示迭代器时才能调用该方法
if (!iterator) {
throw new UnsupportedOperationException();
}
if (lastReturned == null) {
throw new IllegalStateException("Hashtable Enumerator");
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
synchronized (Hashtable.this) {
Entry[] tab = Hashtable.this.table;
int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length;
// 计算索引位置,遍历单链表
for (Entry<K, V> e = tab[index], prev = null; e != null; prev = e, e = e.next) {
// 判断是不是当前迭代的节点
if (e == lastReturned) {
modCount++;
expectedModCount++;
if (prev == null) {
tab[index] = e.next;
} else {
prev.next = e.next;
}
count--;
lastReturned = null;
return;
}
}
throw new ConcurrentModificationException();
}
}
}7.工具类方法
public synchronized int size() {
return count;
}
public synchronized boolean isEmpty() {
return count == 0;
}















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











