









基本概念
LinkedHashMap 是 key 键有序的HashMap的一种实现。它除了使用哈希表这个数据结构,使用双向链表来保证key的顺序。
LinkedHashMap 提供了两种 key 的顺序:
- 访问顺序(access order):可以使用这种顺序实现LRU(Least Recently Used)缓存。
- 插入顺序(insertion orde):同一 key 的多次插入,并不会影响其顺序。
内部构造
1.继承关系
LinkedHashMap 继承自 HashMap,说明它的内部同样采用哈希表的结构来存储元素。如下图所示:

2.Entry
即节点,它是 LinkedHashMap 的内部类,继承自 HashMap.Entry。
在创建该节点时通过调用 HashMap.Entry 的构造函数实现,说明它们的结构一样,是组成单向链表的节点。
private static class Entry<K, V> extends HashMap.Entry<K, V>{
// 构造函数
Entry(int hash, K key, V value, HashMap.Entry<K, V> next) {
super(hash, key, value, next);
}
// 省略部分代码...
}
3.单向链表
上面提到 LinkedHashMap.Entry 可以表示单向链表的节点。那么它是如何实现节点的添加、删除?
// 添加节点
Entry e1 = ...
Entry e2 = new Entry(hash,key,value,e2);
// 移除节点
e2.next = null;观察代码可知,它通过设置成员变量 next 的值来实现单向链表的基本操作。
4.双向循环链表
LinkedHashMap.Entry 既可以表示单向链表的节点,也可以表示双向循环链表的节点。
它通过两个成员变量: before、after,表示双向循环链表的前后指针。
通过 remove、addBefore 实现双链表节点的加入/移除。
private static class Entry<K, V> extends HashMap.Entry<K, V>{
// 表示前、后指针
Entry<K, V> before, after;
//移除操作
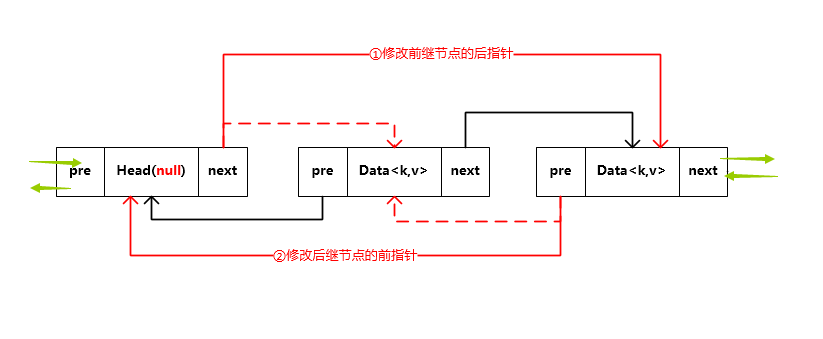
private void remove() {
before.after = after; // ①
after.before = before; //②
}
//添加操作
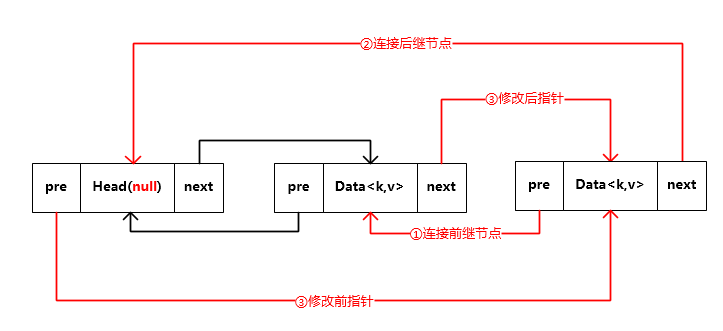
private void addBefore(Entry<K, V> existingEntry) {
// ①~④
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
// 省略部分代码...
}操作过程如下图:
- 删除操作(对应方法注释①②)
- 添加操作(对应方法注释①~④)
5.构造函数
LinkedHashMap 在所有的构建过程中都调用了 HashMap 的构造函数来实现。
HashMap 的构造方法都会调用 init 方法执行执行初始化,该方法在这里被重写。
因此 LinkedHashMap 的创建过程为:
LinkedHashMap.construct -> HashMap.construct -> LinkedHashMap.init。
下面来看它的源码:
// 按访问顺序排序,否则按照插入顺序排序
private final boolean accessOrder;
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
// 关键
void init() {
// 创建循环双链表
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}观察代码,LinkedHashMap 与 HashMap 一样,内部都采用的了哈希表的结构,不同的是:
LinkedHashMap 在构建时还会额外的创建一个双循环链表。
LinkedHashMap 构造函数的入参多了一个参数:accessOrder。该参数表示在访问 LikedHashMap 集合时是否按照访问顺序获取键值对,具体的作用下面会探究到。
操作方法
1.添加操作
在 LinkedHashMap 类中,put 方法表示添加操作。该方法继承自它的父类 HashMap。
put 方法的实现过程是:
- 先遍历哈希表是否存在匹配的 key,如果有则进行修改操作。
- 若没有通过进行添加操作。
在 LinkedHashMap 中类对 addEntry 、createEntry 进行了重写。其调用过程为:
super.put-> addEntry ->super.addEntry -> createEntry。
代码如下:
// 1.HashMap.put
public V put(K key, V value) {
// 省略部分代码...
// 不存在相同节点,执行添加操作;该方法在 LinkedHashMap 被重写
addEntry(hash, key, value, i);
return null;
}
// 2.LinkedHashMap.addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
Entry<K, V> eldest = header.after;
// 默认返回 false
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
// 3.HashMap.addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
// 省略代码:判断扩容操作,是的话,重新计算哈希表的位置...
// 创建新节点,并插入链表
createEntry(hash, key, value, bucketIndex);
}
// 4.LinkedHashMap.createEntry
void createEntry(int hash, K key, V value, int bucketIndex) {
// 构建新节点并加入哈希表
HashMap.Entry<K, V> old = table[bucketIndex];
Entry<K, V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 添加到双链表头节点的前面,即成为双链表的尾节点
e.addBefore(header);
size++;
}2.修改操作
在 LinkedHashMap 类中,put 方法同样表示修改操作。上面提到该方法继承自它的父类 HashMap。
// 1.HashMap.put
public V put(K key, V value) {
// 省略部分代码...
// 遍历该位置上的链表
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
// 判断是否存在相同节点,存在则执行修改操作
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
// 关键,在 HashMap 为空方法,这里对它进行了重写。
e.recordAccess(this);
return oldValue;
}
}
addEntry(hash, key, value, i);
return null;
}不同于 HashMap 的 Entry,在 LinkedHashMap 中节点对 recordAccess 进行方法进行了重写。
// LinkedHashMap.Entry.recordAccess
void recordAccess(HashMap<K, V> m) {
LinkedHashMap<K, V> lm = (LinkedHashMap<K, V>) m;
if (lm.accessOrder) {
lm.modCount++;
// 移除当前节点
remove();
// 添加到双链表的头节点之前,即链表末尾
addBefore(lm.header);
}
}通过 LinkedHashMap 将操作过的节点转移到双链表的末尾位置,以此实现 LRU。
3.删除操作
在 LinkedHashMap 类中,remove 方法同样表示删除操作。该方法继承自它的父类 HashMap,这里不再分析。
4.查询操作
在 LinkedHashMap 类中,get 方法表示操作查询。
与修改操作一样,不同的是其内部类 Entry 定义的 recordAccess 方法 。
public V get(Object key) {
// HashMap.getEntry
Entry<K, V> e = (Entry<K, V>) getEntry(key);
if (e == null){
return null;
}
// 关键
e.recordAccess(this);
return e.value;
}














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











