









字典树:一种利用字符串前缀来节省查找时间的树结构。例如,我需要保存"acm","acca","usb"三个字符串,可以利用"acm"和"acca"的"ac"这个公共前缀节省空间。见下图
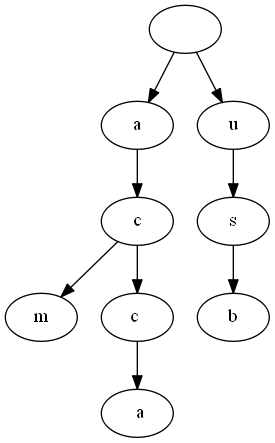
树上总有一个根结点,一般不存值,字符从根结点起到叶结点组成 字符串。
代码实现:
1)结点定义:cnt变量是该结点存的值,具体存什么看具体情况。每个结点都有一个指针数组,保存它所指向的结点,数组大小就看字符集大小。下例是26个小写字母。
struct node
{
int cnt; //字符出现的次数
node *next[27]; //结点指针
node(){
cnt=0;
memset(next,NULL,sizeof(next));
}
};next[i]:该结点的所有后继结点中编号为i的结点
2)插入一个字符串
void insert(node *p,char *s) //p一般为根结点指针传入
{
int i=0;
while(s[i]) //遍历字符串
{
int k=s[i]-'a'; //获取编号
if(!p->next[k]) //如果不存在该字符结点
p->next[k]=new node(); //新建结点
p=p->next[k]; //指向下一个字符继续
i++;
p->cnt++; //字符出现次数++,此行代码也可能是在while循环之外,在里面代表每个节点都计数+1,在外面代表只有字符串结尾才+1,看具体题目需求
}
}然后插入"acca",首先发现根下面有'a',所以就不新建了,p指向它,继续下一个字符,到第2个'c'时,原有的'c'下面没有'c'结点,新建...
3)查询 复杂度与树高有关,基本O(len)
int query(node *p,char *s)
{
int i=0,ans=0;
while(s[i])
{
int k=s[i]-'a';
if(!p->next[k]) //没有该结点,就是不存在该字符串
return 0;
p=p->next[k];
i++;
}
return p->cnt; //返回字符串最后个元素的值
}字典树入门就这么简单,需要灵活用,结点存什么、是不是只在叶结点存都看具体情况,
裸题,注意下输入格式
#include <cstdio>
#include <cmath>
#include <cstring>
#include <string>
#include <set>
#include <map>
#include <stack>
#include <queue>
#include <vector>
#include <iostream>
#include <iomanip>
#include <algorithm>
using namespace std;
#define ll __int64
#define INF 0x7FFFFFFF
#define INT_MIN -(1<<31)
#define eps 10^(-6)
#define Q_CIN ios::sync_with_stdio(false);
#define REP( i , n ) for ( int i = 0 ; i < n ; ++ i )
#define FOR( i , a , b ) for ( int i = a ; i <= b ; ++ i )
#define CLR( a , x ) memset ( a , x , sizeof (a) );
#define RE freopen("1.in","r",stdin);
#define WE freopen("1.out","w",stdout);
#define MOD 10009
#define debug(x) cout<<#x<<":"<<(x)<<endl;
struct node
{
int cnt;
node *next[27];
node(){
cnt=0;
memset(next,NULL,sizeof(next));
}
};
void insert(node *p,char *s)
{
int i=0;
while(s[i])
{
int k=s[i]-'a';
if(!p->next[k])
p->next[k]=new node();
p=p->next[k];
i++;
p->cnt++;
}
}
int query(node *p,char *s)
{
int i=0,ans=0;
while(s[i])
{
int k=s[i]-'a';
if(!p->next[k])
return 0;
p=p->next[k];
i++;
}
return p->cnt;
}
int main()
{
// RE
char s1[15];
node *p=new node();
while(gets(s1)&&s1[0])
insert(p,s1);
while(gets(s1))
cout<<query(p,s1)<<endl;
return 0;
}
判断字符串里是不是有某串是其他串的前缀
本题需要在每次使用之后删除结点,否则MLE。
#include <cstdio>
#include <cmath>
#include <cstring>
#include <string>
#include <set>
#include <map>
#include <stack>
#include <queue>
#include <vector>
#include <iostream>
#include <iomanip>
#include <algorithm>
using namespace std;
#define ll __int64
#define INF 0x7FFFFFFF
#define INT_MIN -(1<<31)
#define eps 10^(-6)
#define Q_CIN ios::sync_with_stdio(false);
#define REP( i , n ) for ( int i = 0 ; i < n ; ++ i )
#define FOR( i , a , b ) for ( int i = a ; i <= b ; ++ i )
#define CLR( a , x ) memset ( a , x , sizeof (a) );
#define RE freopen("1.in","r",stdin);
#define WE freopen("1.out","w",stdout);
#define MOD 10009
#define debug(x) cout<<#x<<":"<<(x)<<endl;
struct node
{
node *next[11];
int v; //是否为叶结点
node(){
v=0;
CLR(next,NULL);
}
};
int insert(node *p,char *s)
{
int i=0;
while(s[i])
{
int k=s[i]-'0';
if(!p->next[k])
p->next[k]=new node();
if(p->next[k]->v) //某串是该串的前缀
return 0;
p=p->next[k];
i++;
}
p->v=1;
for(int i=0;i<10;i++) //如果当前串后面还有则说明该串是某串的前缀
if(p->next[i])
return 0;
return 1;
}
void del(node *p)
{
for(int i=0;i<10;i++)
if(p->next[i]) del(p->next[i]);
delete(p);
}
int main()
{
int t,n;
// RE
cin>>t;
char s1[20];
while(t--)
{
cin>>n;
node *p=new node();
int no=0;
REP(i,n)
{
cin>>s1;
if(no)
continue;
if(!insert(p,s1))
no=1;
}
if(no)
cout<<"NO"<<endl;
else
cout<<"YES"<<endl;
del(p);
}
return 0;
}POJ.3630的141MS的数组写法: 2016-08-23 23:43:23
#include <cstdio>
#include <cmath>
#include <cstring>
#include <string>
#include <iostream>
#include <algorithm>
using namespace std;
#define ll long long
#define clr( a , x ) memset ( a , x , sizeof (a) );
#define RE freopen("in.txt","r",stdin);
#define WE freopen("out.txt","w",stdout);
const int maxn = 10000 * 13 + 5;
const int maxch = 11;
struct tree
{
int next[maxn][maxch];
bool leaf[maxn];
int cnt, root;
int newNode() {
memset(next[cnt], -1, sizeof(next[cnt]));
return cnt++;
}
void init() {
cnt = 0;
root = newNode();
memset(leaf, false, sizeof(leaf));
}
bool insert(char *s1) {
int len = strlen(s1);
int cur = root;
for (int i = 0; i < len; ++i) {
int id = s1[i] - '0';
if (next[cur][id] == -1) {
next[cur][id] = newNode();
}
if (leaf[cur]) return true;
cur = next[cur][id];
}
leaf[cur] = true;
//如果当前串后面还有则说明该串是某串的前缀
for (int i = 0; i < maxch; ++i){
if(next[cur][i] != -1) return true;
}
return false;
}
} trie;
int main() {
// RE
int t, n;
char s1[12];
scanf("%d", &t);
while (t--) {
scanf("%d", &n);
bool done = false;
trie.init();
for (int i = 0; i < n; ++i) {
scanf("%s", s1);
if (trie.insert(s1)) { done = true;}
}
if (done) printf("NO\n");
else printf("YES\n");
}
return 0;
}题意很重要..."you will find for each word the shortest prefix that uniquely identifies the word it represents. ",没看懂的时候还一直想为什么"car"最短不是"c"。。一开始以为是我们帮它们选前缀,保证不一样就行..其实是用选能唯一识别的前缀。
解法:给每个结点加上出现次数,全部插入完后查找那些字符串,在一定能找到的情况下有字母出现一次那就是最短前缀的结尾了,如果找完都没找到为1的那结果就是字符串本身。
#include <cstdio>
#include <cmath>
#include <cstring>
#include <string>
#include <set>
#include <map>
#include <stack>
#include <queue>
#include <vector>
#include <iostream>
#include <iomanip>
#include <algorithm>
using namespace std;
#define ll __int64
#define INF 0x7FFFFFFF
#define INT_MIN -(1<<31)
#define eps 10^(-6)
#define Q_CIN ios::sync_with_stdio(false);
#define REP( i , n ) for ( int i = 0 ; i < n ; ++ i )
#define FOR( i , a , b ) for ( int i = a ; i <= b ; ++ i )
#define CLR( a , x ) memset ( a , x , sizeof (a) );
#define RE freopen("1.in","r",stdin);
#define WE freopen("1.out","w",stdout);
#define MOD 10009
#define debug(x) cout<<#x<<":"<<(x)<<endl;
struct node
{
node *next[27];
int cnt;
node(){
cnt=0;
CLR(next,NULL);
}
};
void insert(node *p,char *s)
{
int i=0;
while(s[i])
{
int k=s[i]-'a';
if(!p->next[k])
p->next[k]=new node();
p->next[k]->cnt++;
p=p->next[k];
i++;
}
}
int cnt;
int loc;
void find(node *p,char *s)
{
int i=0;
while(s[i])
{
int k=s[i]-'a';
if(p->cnt==1){
loc=i-1;return;
}
p=p->next[k];
i++;
}
loc=strlen(s)-1;
}
char s1[1005][23];
int main()
{
int t,n;
// RE
Q_CIN
node *p=new node();
int j=0;
while(cin>>s1[j])
{
insert(p,s1[j]);
j++;
}
REP(i,j)
{
loc=0;
cout<<s1[i]<<" ";
find(p,s1[i]);
FOR(q,0,loc)
cout<<s1[i][q];
cout<<endl;
}
return 0;
}
给定一个单词表,在里面找出指定单词出现的位置(首字母)和方向(8个,'A'表示北,'B'表示东北,'C'为东...顺时针)
对查询的单词建树,如果对字母表建则位置信息会丢失。
思路:建立好树后,DFS表中每个点,每个方向,沿着这个方向走下去,如果找到树上的字符串就保存结果到一个结构体数组里。
判断找到:当然是树上的字符串最后个单词给个标记,判断到字符串尾部。然后因为是DFS,先找到哪个我们并不知道,所以就把那个串的标记也加上编号,如第一个字符串的尾上有id=1,第2个字符串有id=2.然后保存答案到ans[ id ]里。
Hints:在某地某方向找到一个后不能return,要继续找,因为可能后面还可以组成字符串,如:
在1行3列的“ABC"里找"AB"和"ABC",找到"AB"后还得继续找,这也是字典树在这题的时间效率体现:公共前缀。
// 3250MS 14868K
#include <cstdio>
#include <cmath>
#include <cstring>
#include <string>
#include <set>
#include <map>
#include <stack>
#include <queue>
#include <vector>
#include <iostream>
#include <iomanip>
#include <algorithm>
using namespace std;
#define ll __int64
#define INF 0x7FFFFFFF
#define INT_MIN -(1<<31)
#define eps 10^(-6)
#define Q_CIN ios::sync_with_stdio(false);
#define REP( i , n ) for ( int i = 0 ; i < n ; ++ i )
#define FOR( i , a , b ) for ( int i = a ; i <= b ; ++ i )
#define CLR( a , x ) memset ( a , x , sizeof (a) );
#define RE freopen("1.in","r",stdin);
#define WE freopen("1.out","w",stdout);
#define MOD 10009
#define debug(x) cout<<#x<<":"<<(x)<<endl;
int _dir[][2]={-1,0,-1,1,0,1,1,1,1,0,1,-1,0,-1,-1,-1};
struct node
{
node *next[27];
int id; //被查询单词的序号
node(){
id=0;
CLR(next,NULL);
}
};
struct res
{
int x,y;
char dir;
}ans[1005];
char tu[1005][1005];
int l,c,w;
void insert(node *p,char *s,int id)
{
int i=0;
while(s[i])
{
int k=s[i]-'A';
if(!p->next[k])
p->next[k]=new node();
p=p->next[k];
i++;
}
p->id=id;
}
bool inmap(int x,int y)
{
if(x>=0&&x<l)
if(y>=0&&y<c)
return true;
return false;
}
void dfs(node *p,int row,int col,int qx,int qy,int dir)
{
if(!p) return;
if(p->id) //到结尾
{
ans[p->id].x=qx;
ans[p->id].y=qy;
ans[p->id].dir='A'+dir;
// return; //不能return,同一个位置可能有多个单词可以找到
}
int tx=row+_dir[dir][0];
int ty=col+_dir[dir][1];
if(!inmap(tx,ty)) return;
int k=tu[tx][ty]-'A';
if(p->next[k])
dfs(p->next[k],tx,ty,qx,qy,dir);
}
int main()
{
int t,n;
char s1[1200];
while(cin>>l>>c>>w)
{
node *p=new node();
REP(i,l)
cin>>tu[i];
FOR(i,1,w)
{
cin>>s1;
insert(p,s1,i);
}
REP(i,l)
REP(j,c)
REP(k,8) //0到7,没有8
dfs(p->next[tu[i][j]-'A'],i,j,i,j,k); //若直接传递p,则会发生第一个字母位置偏移
FOR(i,1,w)
cout<<ans[i].x<<" "<<ans[i].y<<" "<<ans[i].dir<<endl;
}
return 0;
}
POJ 2503 Babelfish
水题一个,对乱乱 的单词建树,并用1个数组保存编号为i的字母的原字符串,然后查找乱单词的编号,对应输出
#include <cstdio>
#include <cmath>
#include <cstring>
#include <string>
#include <set>
#include <map>
#include <stack>
#include <queue>
#include <vector>
#include <iostream>
#include <iomanip>
#include <algorithm>
using namespace std;
#define ll __int64
#define INF 0x7FFFFFFF
#define INT_MIN -(1<<31)
#define eps 10^(-6)
#define Q_CIN ios::sync_with_stdio(false);
#define REP( i , n ) for ( int i = 0 ; i < n ; ++ i )
#define FOR( i , a , b ) for ( int i = a ; i <= b ; ++ i )
#define CLR( a , x ) memset ( a , x , sizeof (a) );
#define RE freopen("1.in","r",stdin);
#define WE freopen("1.out","w",stdout);
#define MOD 10009
#define debug(x) cout<<#x<<":"<<(x)<<endl;
struct node
{
int id;
node *next[27];
node(){
id=0;
CLR(next,NULL);
}
};
void insert(node *p,char *s,int idx)
{
int i=0;
while(s[i])
{
int k=s[i]-'a';
if(!p->next[k]) p->next[k]=new node();
p=p->next[k];
i++;
}
p->id=idx;
}
int query(node *p,char *s)
{
int i=0;
while(s[i])
{
int k=s[i]-'a';
if(!p->next[k]) return 0;
p=p->next[k];
i++;
}
return p->id;
}
char dic[100005][12];
int main()
{
// RE
char str[30];
int i=1;
int t=0;
node *p=new node();
strcpy(dic[0],"eh\0");
while(gets(str),str[0])
{
int loc=0;
while(str[loc]!=' ') loc++;
str[loc]='\0';
memcpy(dic[i],str,loc);
insert(p,str+loc+1,i);
i++;
}
while(gets(str))
printf("%s\n",dic[query(p,str)]);
return 0;
}














 3167
3167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









