







hadoop完全分布式配置。
过程大致如下:
1.创建新用户并添加到sudoers
2.更改hosts,hostname文件
3.安装jdk,并配置环境变量
4.设置ssh无密码登录
5.hadoop安装,设置文件
1.创建新用户
$ adduser hadoop$ sudo vi /etc/sudoers
在
# User privilege specification
root ALL=(ALL:ALL) ALL
下面添加
hadoop ALL=(ALL:ALL) ALL
保存退出。
切换到hadoop用户
$ su hadoop
2.更改hosts文件。
3台机器192.168.1.101 master
192.168.1.102 slave1
192.168.1.103 slave2
$ sudo vi /etc/hosts
将上面的内容填写到末尾。
这里可以该hostname文件,也可以不改。
如果要改,那么就先该hostname,在改hosts,将里面原来的主机名改为新的名字。
改hostname可以参照下面。
ubuntu修改hostname
a.临时修改
$hostname newhostname
重启之后又变回原来的样子了
b.永久修改
第一步:sudo vi /etc/hostname
这一行,把它右边的旧主机名改成你的新主机名即可。重启网络
sudo /etc/init.d/networking restart
或则
sudo reboot
重新启动计算机生效
3.安装jdk,并配置环境变量
参照我的博客
http://blog.csdn.net/u012480384/article/details/40456187
4.设置ssh无密码登录
$ ssh-keygen$ ssh-copy-id hadoop@slave1
$ ssh slave1
这样可以登录到slave1机器上。
在slave1用类似的设置无密码登录到master。
对slave2使用一样的设置。
最后3台机器间都可以互相无密码登录。
5.hadoop安装,设置文件
hadoop集群中每个机器上面的配置基本相同,所以我们先在master上面进行配置部署,然后再复制到其他节点。所以这里的安装过程相当于在每台机器上面都要执行。【注意】:master和slaves安装的hadoop路径要完全一样,用户和组也要完全一致.
先下载hadoop编译好的压缩包。
http://hadoop.apache.org/releases.html
找一个合适的下载,注意,带src的压缩包是源码。有兴趣的可以编译源码。我博客里有编译方法。
http://blog.csdn.net/u012480384/article/details/39697267
进入到下载的目录,解压。
$ sudo tar zxvf hadoop-2.4.1.tar.gz -C /usr/local/
$ sudo mv /usr/local/hadoop-2.4.1 hadoop#该文件夹的名字,改成hadoop
ssh的通信一般是: $ ssh username@ip
如果是 $ ssh ip 。假设A机器上的a1用户使用该命令,则会连接B机器上的a1用户。
这个规则使得我们需要一致的用户和用户组。
这里要涉及到的配置文件有7个:
/etc/profile
$HADOOP_DIR/etc/hadoop/hadoop-env.sh
$HADOOP_DIR/etc/hadoop/slaves
$HADOOP_DIR/etc/hadoop/core-site.xml
$HADOOP_DIR/etc/hadoop/hdfs-site.xml
$HADOOP_DIR/etc/hadoop/mapred-site.xml
$HADOOP_DIR/etc/hadoop/yarn-site.xml
配置文件1:/etc/profile
这里设置hadoop的环境变量。
$ sudo gedit /etc/profile
将下面的添加到文件最后
#hadoop
export HADOOP=/usr/local/hadoop
export PATH=$PATH:$HADOOP/bin
在终端中,$ source /etc/profile使之生效。
在输入
$ hadoop version
查看是否显示版本。显示则成功。
配置文件2:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/lib/jvm/java)
这里是你自己的java路径,如果按在其他路径上,相应修改即可。
配置文件3:slaves (这个文件里面保存所有slave节点)
打开slaves文件,如果没有修改过的话,里面就一行,localhost。
将它改成需要成为node节点的机器。
master
slave1
slave2
保存退出。
配置文件4:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
配置文件5:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
配置文件6:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run </description>
</property>
</configuration>
【注意】:而且所有的配置文件<name>和<value>节点处不要有空格,否则会报错!
复制到其他节点
上面配置完毕,我们基本上完成了90%了剩下就是复制。我们可以把整个hadoop复制过去:使用如下命令:$ sudo scp -r /usr/local/hadoop hadoop@slave1:~/
然后,移动到/usr/local下
登录slave1
$ ssh slave1
$ sudo mv ~/hadoop /usr/local
后面我们会经常遇到问题,经常修改配置文件,所以修改完一个配置文件后,其他节点都需要修改,这里附上脚本操作方便:
一、节点之间传递数据:第一步:vi scp.sh第二步:把下面内容放到里面(记得修改下面红字部分,改成自己的)
#!/bin/bash
#slave1
scp -r /usr/local/hadoop/etc/ hadoop@slave1:~/
#slave2
scp -r /usr/local/hadoop/etc/ hadoop@slave2:~/
第三步:保存scp.sh第四步:bash scp.sh
执行二、移动文件夹:可以自己写了。
上面将hadoop目录下的/etc文件夹全部复制到其他机器hadoop用户的主目录里。
在每个机器上将/etc目录跟新。(删除原来/hadoop下的etc目录,将新的复制过去)
启动验证
(1)启动hadoop格式化namenode
$ hdfs namenode -format
$ cd $HADOOP #进入hadoop目录
启动hdfs:
$ sbin/start-dfs.sh
此时在master上的java进程有:
namenode
secondarynamenode
slave上有:
datanode
在对应终端里输入“jps”来查看。
启动yarn
$ sbin/start-yarn.sh
master上有:
namenode
secondarynamenode
resourcemanager
slave上有:
datanode
nodemanager
此时hadoop集群已全部配置完成!!!
(2)web查看页面
a、可以通过登录Web控制台,查看HDFS集群状态,访问如下地址:
http://master:50070/
这里查看hdfs集群状态。
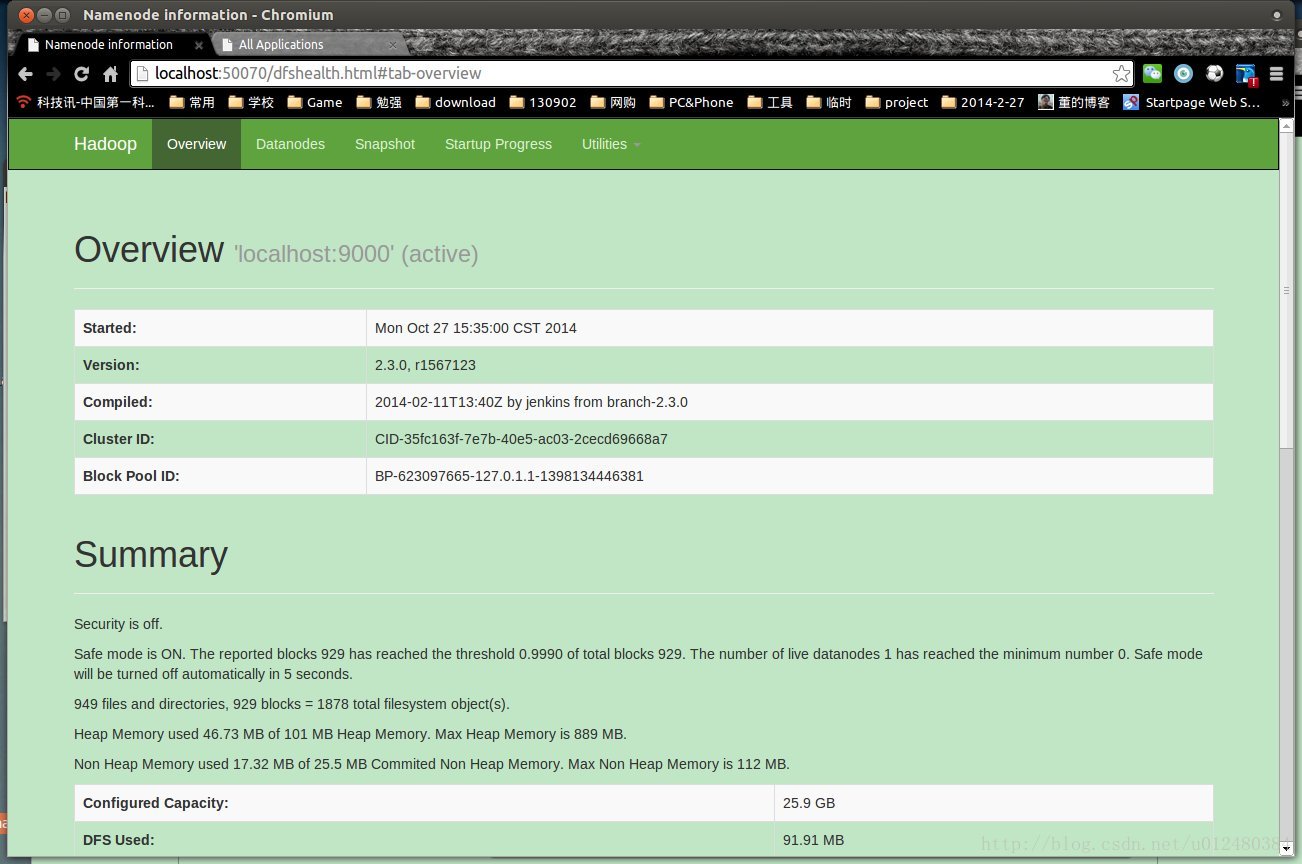
来源:
组件 :HDFS
节点 :NameNode
默认端口:50070
配置 :dfs.namenode.http-address
用途说明:http服务的端口
b、ResourceManager运行在主节点master上,可以Web控制台查看状态
http://master:8088/
或者 http://ip地址:8088/
这里的master会通过你刚才设置的hosts文件映射成对应的ip地址。
如果不是在集群的机器上想访问,可以通过ip地址的形式来访问。或者添加对应的ip地址到机器的hosts文件里。
win7 进入下面路径:
C:\Windows\System32\drivers\etc
里面有hosts文件,对应添加一下就OK了。下面遇到同样的问题,可以参照这里。
这里查看job运行状态。
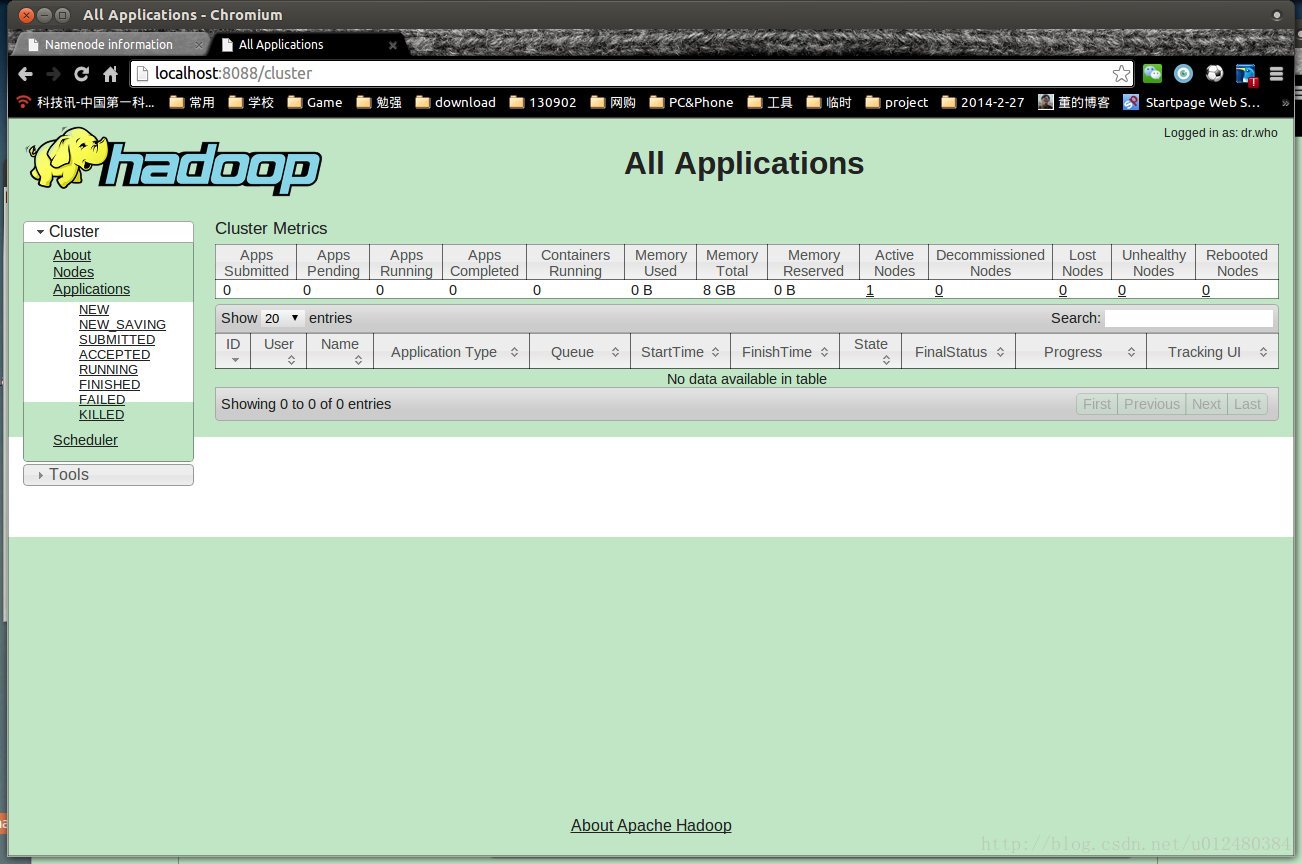
这里介绍8088的来源:
/usr/local/hadoop/share/hadoop/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
中的默认设置。
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
可以通过前面提到的yarn-site.xml中来更改设置
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
c、NodeManager运行在从节点上,可以通过Web控制台查看对应节点的资源状态,例如节点slave1:
http://slave1:8042/
/usr/local/hadoop/share/hadoop/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
中的默认设置。
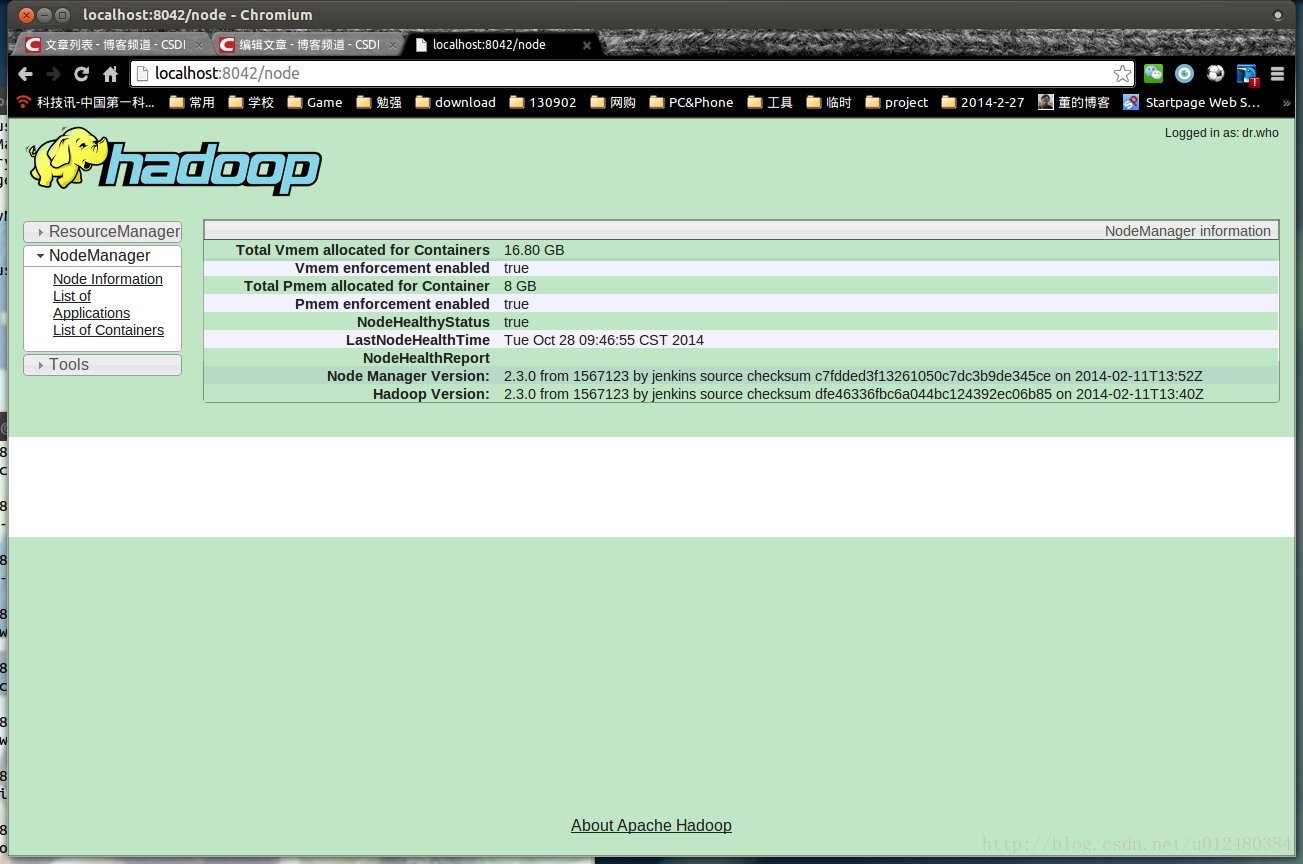
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>${yarn.nodemanager.hostname}:8042</value>
</property>
来源:
组件 :YARN
节点 :NodeManager
默认端口:8042
配置 :yarn.nodemanager.webapp.address
用途说明:http服务端口
d、管理JobHistory Server
启动可以JobHistory Server,能够通过Web控制台查看集群计算的任务的信息,执行如下命令:
$ cd $HADOOP #进入hadoop目录
$ sbin/mr-jobhistory-daemon.sh start historyserver
默认使用19888端口。
通过访问http://master:19888/
终止JobHistory Server,执行如下命令:
$ sbin/mr-jobhistory-daemon.sh stop historyserver
其他:
hadoop2.x常用端口、定义方法及默认端口、hadoop1.X端口对比
http://www.aboutyun.com/thread-7513-1-1.html














 2084
2084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









