






 超级会员免费看
超级会员免费看
随着MySQL自身的发展与不断完善,不知不觉中整个互联网行业已离不开这个完善又小巧的关系型数据库,整个生态链也已经变得非常成熟,即便是初创企业和传统企业也可以放心大胆地把数据库迁移到MySQL上来。在大家和MySQL数据库愉快玩耍的同时,我来聊聊MySQL架构设计相关的一些话题。
一、MySQL数据库开发规范
数据库规范到底有多重要?有过初创公司经历的朋友应该都深有体会。规范是数据库运维的一个基石,能有效地减少数据库出问题的概率,保障数据库schema的合理设计并方便后续自动化的管理。
曾经我们花了大半年时间来做数据库规范化的工作,例如制定数据库开发指南、给程序员做培训等,推进的时候也会遇到一些阻力。但规范之后运维质量会有一个质的提升,也增进了DBA的工作效率。
在开发规范方面,我们划分为开发规范和运维规范两部分。
1、开发规范
表设计的规范:
字段数量建议不超过20-50个
做好数据评估,建议纯INT不超过1500万,含有CHAR的不要超过1000万。字段类型在满足需求条件下越小越好,尽量使用UNSIGNED存储非负整数,因为实际使用时候存储负数的场景不多。
将字符转换成数字存储。例如使用UNSIGNED INT存储IPv4 地址而不是用CHAR(15) ,但这种方式只能存储IPv4,存储不了IPv6。另外可以考虑将日期转化为数字,如:from_unixtime()、unix_timestamp()。
所有字段均定义为NOT NULL,除非你真的想存储null。
索引设计的规范:
1)所有表必须有显式主键
InnoDB表是以主键排序存储的IOT表
尽量使用短、自增的列做索引
复制结构使用row格式,如果表有主键可以加速复制
UNSIGNED INT自增列,也可以考虑BIGINT
TINYINT做主键可能导致MySQL Crash
类型转换会导致查询效率很低
可用uuid_short()代替uuid(),转成BIGINT存储
2)合理地建立索引
选择区分度高的列作为索引
单个索引字段数不超过5,单表索引数量不超过5,避免冗余索引
建立的索引能覆盖80%主要的查询,不求全,解决问题的主要矛盾
复合索引排序问题,多用explain去确认
SQL编写规范:
1)避免在数据库中进行大量计算任务
大事务拆成多个事务,分批多次操作
慎用text、blob大型字段,如要用考虑好拆分方案
频繁查询的字典表考虑用Cache抗
2)优化join
避免大表与大表之间的join,考虑让小表去驱动大表join
最多允许三表join,最好控制成两表
控制join后面where选择的行数
3)注重where条件,多用EXPLAIN确认
where条件的字段,尽量用区别度高的字段,这样走索引的性能更好
出现子查询的SQL,先确认MySQL版本,利用explain确认执行计划
进行分页优化;DML时候多个value合并
Schema Review:
1)字符集问题
表字符集选择UTF8 ,如果需要存储emoj表情,就改成UTF8mb4
2)Schema设计原则
核心表字段数量尽可能地少,有大字段要考虑拆分
适当考虑一些反范式的表设计,增加冗余字段,减少JOIN
资金字段考虑统一*100处理成整型,避免使用decimal浮点类型存储
日志类型的表可以考虑按创建时间水平切割,定期归档历史数据
3)Schema设计目标
快速实现功能为主,保证节省资源
平衡业务技术各个方面,做好取舍
不要在DB里进行大计算,减少复杂操作
整体来说,这部分规范还是很容易遵守的,实现起来也没有什么难度,就能取得很好的效果。
2、运维规范
(1)SQL审核
SQL评审这部分工作相信让很多的DBA同学都叫苦不迭,人肉审核不仅效率低下,容易出错,对DBA的自身发展也非常不利,难道我们来上班就是为了审核SQL的吗?在经过了一段痛苦的人肉审核之后,我们接入了去哪儿网开源的Inception,并根据自身的业务特点做了一些调整。当然现在开源的SQL评审软件已经很多了,大家可以自由选择,也可以自行开发。
(2)权限控制
MySQL从5.6开始,逐步完善了权限系统,比如MySQL5.6可以安装检查密码强度的插件,5.7开始增加了密码过期机制、账户锁定等功能,对SSL这一块也做了一些优化,8.0版本增加了角色的功能,权限系统已经逐步在向Oracle数据库靠拢了。在日常运维中,也可以使用pt-show-grants工具提高权限审查的力度。应用程序账号应只赋予SELECT、INSERT、UPDATE权限,DELETE的逻辑改用UPDATE实现,并启用sql_safe_updates选项。
SQL堡垒机不仅可控制公司内部人员的数据库权限,追溯各类人员对数据库的操作,也能避免大查询或全表更新的情况发生,支持审计需求,整体运维质量提升了一个台阶。
(3)MySQL版本选择
MySQL社区版,用户群体最大
MySQL企业版,收费
Percona Server版,新特性多,和MySQL社区版最接近
MariaDB版,国内用户暂时不多
选择优先级:MySQL社区版> Percona Server > MariaDB > MySQL 企业版
对于版本选择这件事,建议大家还是跟进官方社区版比较好,目前比较稳定的版本是MySQL5.6,推荐大家使用。有特殊需求的话再选择MySQL5.7、PXC、TiDB、TokuDB等数据库。
二、MySQL高可用架构选型
MySQL高可用方面,目前业界主流依然是基于异步复制的技术,例如Keepalived、MHA、ZooKeeper等,要求数据强一致的场景逐步开始使用分布式协议,这方面的典型代表有PXC、Group Replication、TiDB。下面我们就重点来说说keepalived、MHA和PXC这几种大家用得比较多的架构。
1、keepalived高可用架构

业内使用非常普遍,它部署容易、方便维护,还节省服务器资源。这种架构的一个好处就是在发生切换后,原Master只需重新拉起来即可恢复高可用,不需要过多干预。扩展起来也方便,可以任意挂载只读库和灾备库。但它存在的问题也很明显,比如Keepalived的检测机制不完善、有脑裂隐患、数据一致性较弱等等。
还需要注意主从拓扑的设计。如下图,只读库挂到哪个Master比较合适?显然是M2,其它两种拓扑在发生切换后都会影响到只读库的访问。

2、MHA
MHA自诞生以来,就得到了业内的广泛关注,并迅速流行开来。与keepalived相比,MHA最大的优点就是在发生故障切换之后,能自动补齐binlog,最大程度保证数据一致性。从服务器能自动切换,无需人工干预,能非常好的工作在读写分离的环境下。基于Perl语言的脚本也非常方便进行二次开发。MHA非常适合读写压力比较大的应用。
但由于MHA在工作时需要配置SSH互信,因此选择这种架构时内网安全一定要做到位。另外也可以搭配Binlog Server使用。
3、PXC
PXC全称是Percona XtraDB Cluster,是Percona公司基于Galera协议开发的一个产品。PXC牺牲了CAP里面的P(Partition Tolerance),保留了C(Consistency )和A(Availability )。这种结构非常适合电商、金融类业务,自PXC和Group Replication出现以后,MySQL彻底扫清了进入金融行业的障碍。
PXC的优势:
同步复制,解决了传统架构复制延迟和脑裂的问题
数据强一致
多主复制,每个节点都可以读写数据
并行复制,多个事务可以并行推送到其他节点
高可用,单点故障不影响集群可用性
新节点自动部署
与传统MySQL几乎完全兼容
使用PXC要注意的问题:
不要有大事务
木桶效应,集群性能取决于性能最差的那个节点
并发效率有损失
网络要求较高,建议万兆网络
多点并发写时锁冲突、死锁问题多
写无法扩展,无法解决热点更新问题
除此之外,还有一类采用DNS/ZooKeeper的高可用架构,这种架构通常都需要自行开发,无通用的方案,比较适合大规模集群的高可用,这里我们不过多赘述。
下面简单回顾一下上述几种高可用架构:
双Master架构:非常成熟,使用很普遍,要注意延迟和数据的一致性。
PXC: 分布式协议,数据强一致性,并发效率略低,可用性好
MHA:各项指标介于M-M和PXC之间,性能无损失,适合读写分离架构。
总而言之,没有最完美的架构,只有最适合的架构。选择适合自己业务的即可。
三、MySQL sharding拆分
接下来是第三个议题,MySQL拆分原则和分库分表设计。
首先先提一个问题,为什么要拆,不拆不行吗?按照我们的经验来看,当数据和业务到了一定的规模,都不可避免的要面临分库分表的问题。这就好像汽车的发动机一样,要达到更高的性能,4缸6缸明显是不够用的,V8、V12才是王道。
拆分能解决如下几个问题:
单库并发较大
单库物理文件太大
单表过大,DDL无法接受
防止出现性能瓶颈,提升性能
防止出现抖动不稳定现象
确定要进行数据库的拆分了,应该怎么拆呢?
垂直拆分
优点:
拆分简单明了,拆分规则明确
应用程序模块清晰,整合容易
数据维护方便易行,容易定位
缺点:
表关联需要改到程序中完成
事务处理变的复杂
热点表还有可能存在性能瓶颈
过度拆分会造成管理复杂
水平拆分
优点:
不会影响表关联、事务操作
超大规模的表和高负载的表可以打散
应用程序端改动比较小
拆分能提升性能,也比较易扩展
缺点:
数据分散,影响聚集函数的使用
切分规则复杂,维护难度增加
后期迁移较复杂
要先分库还是先分表?
分库的优点:实现简单,库与库之间界限分明,便于维护,缺点是不利于频繁跨库操作,单表数据量大的问题解决不了。
分表的优点:能解决分库的不足点,但是缺点恰恰是分库的优点,分表实现起来比较复杂,特别是分表规则的划分,程序的编写,以及后期的数据库拆分移植维护。
一巴掌拍板直接选分库或分表都是不可取的,主要是看需要达到什么样的扩展方式,才能决定先分库还是先分表,根据具体的场景决定。分库分表的最终目的还是为了扩展,而且要看拆分的规划设计是针对哪一层。
上述问题都解决了,该考虑如何实现了,到底是在应用程序中实现,还是使用中间件?个人建议如果是小规模的拆分,直接在程序逻辑中实现即可,大规模的拆分再考虑使用各种中间件。
目前业内已经开源了很多的MySQL中间件产品,例如Atlas、DBProxy、MyCAT、OneProxy、DRDS、Vitess等等,每个中间件都有自己的特点,个别不太成熟的可能会存在一些Bug,选用之前要做好相关的调研与测试工作,上线使用一定要保证自己能hold住。如果要完全贴合自身业务,并且掌控得较好的还是要自行开发。
下面说说我们的拆分经验。
首先我们先在压力比较大的数据库上做垂直拆分,剥离出活动、后台统计等业务。这一步也是最容易实现的。
接下来,如果是消息类的数据,就基于时间维度进行拆分,单表控制在5-10G,行数控制到500-1000w这个样子。这个时候我们发现数据库的性能是比较好的,而且比较好维护。如果是用户类的数据,就按照Hash或Range进行拆分。这种情况下用这种方法拆分会拆的比较均匀一些。
并发仍然比较高怎么办?可以在时间维度拆分的基础上再按Range或Hash进行拆分。
最后要注意的就是不要过度的拆分,会造成复杂度的上升。Schema设计合理的情况下,10亿的数据量也能跑的好好的。个别不关键的应用,例如日志、监控数据等,使用分区表、TokuDB也能抗。拆分对应用层总是有损的。
要做个“懒”DBA。
MySQL架构设计谈:从开发规范、选型、拆分到减压
四、利用NoSQL为MySQL减压
最后一个议题,我们聊一聊NoSQL。NoSQL现在遍地开花,应用也很广泛了,业内用的比较多的主要集中在Redis、MongoDB、Cassandra等NoSQL数据库上。今天我们主要来说说和MySQL关联最为密切的Redis。
为什么要使用Redis?
数据存储在内存中,访问速度快
能支持大批量操作及爆发性负载
数据结构丰富,有效缓解MySQL压力
协议简单,支持各种语言的API
存储大量数据无需担心性能
Redis主要作用还是抗读的压力。读操作先到Redis,Redis中取不到再从MySQL数据库访问,从MySQL读取到数据后,还要回写到Redis。
使用Redis要注意的几点:
性能方面,由于Redis完全是基于内存的访问,性能无需担心。
在使用Redis时,要注意Cache 和Storage不要混合使用。不要依赖Redis的持久化,持久化这一块Redis要努力的还很多。另外如果你把Redis拿来做Storage的话,一旦Redis的内存跑满,那就惨了,所有的Redis连接都会卡着不响应。如果只是把Redis来做cache的话,那问题就不大。
还有诸如缓存穿透、缓存雪崩、热点key重建时缓存失效这些问题也是重点关注的对象。
如何利用Redis给MySQL加速:
1)利用K/V结构,缓存结果,例如存储用户信息、全局排行、统计信息等。
2)利用其丰富的数据结构为MySQL减压,例如计数器、排序、Hash(把表映射到Redis中)、消息队列等。
总结
系统架构设计是一个长期总结与进化的过程,讲究均衡与取舍。在进行大规模MySQL架构设计的过程中,除了要汲取别人的经验之外,还要关注各种架构背后的业务场景与架构思想,与自己的实际业务场景相结合,才能设计出一个好的系统架构来。
一、MySQL数据库开发规范
数据库规范到底有多重要?有过初创公司经历的朋友应该都深有体会。规范是数据库运维的一个基石,能有效地减少数据库出问题的概率,保障数据库schema的合理设计并方便后续自动化的管理。
曾经我们花了大半年时间来做数据库规范化的工作,例如制定数据库开发指南、给程序员做培训等,推进的时候也会遇到一些阻力。但规范之后运维质量会有一个质的提升,也增进了DBA的工作效率。
在开发规范方面,我们划分为开发规范和运维规范两部分。
1、开发规范
表设计的规范:
字段数量建议不超过20-50个
做好数据评估,建议纯INT不超过1500万,含有CHAR的不要超过1000万。字段类型在满足需求条件下越小越好,尽量使用UNSIGNED存储非负整数,因为实际使用时候存储负数的场景不多。
将字符转换成数字存储。例如使用UNSIGNED INT存储IPv4 地址而不是用CHAR(15) ,但这种方式只能存储IPv4,存储不了IPv6。另外可以考虑将日期转化为数字,如:from_unixtime()、unix_timestamp()。
所有字段均定义为NOT NULL,除非你真的想存储null。
索引设计的规范:
1)所有表必须有显式主键
InnoDB表是以主键排序存储的IOT表
尽量使用短、自增的列做索引
复制结构使用row格式,如果表有主键可以加速复制
UNSIGNED INT自增列,也可以考虑BIGINT
TINYINT做主键可能导致MySQL Crash
类型转换会导致查询效率很低
可用uuid_short()代替uuid(),转成BIGINT存储
2)合理地建立索引
选择区分度高的列作为索引
单个索引字段数不超过5,单表索引数量不超过5,避免冗余索引
建立的索引能覆盖80%主要的查询,不求全,解决问题的主要矛盾
复合索引排序问题,多用explain去确认
SQL编写规范:
1)避免在数据库中进行大量计算任务
大事务拆成多个事务,分批多次操作
慎用text、blob大型字段,如要用考虑好拆分方案
频繁查询的字典表考虑用Cache抗
2)优化join
避免大表与大表之间的join,考虑让小表去驱动大表join
最多允许三表join,最好控制成两表
控制join后面where选择的行数
3)注重where条件,多用EXPLAIN确认
where条件的字段,尽量用区别度高的字段,这样走索引的性能更好
出现子查询的SQL,先确认MySQL版本,利用explain确认执行计划
进行分页优化;DML时候多个value合并
Schema Review:
1)字符集问题
表字符集选择UTF8 ,如果需要存储emoj表情,就改成UTF8mb4
2)Schema设计原则
核心表字段数量尽可能地少,有大字段要考虑拆分
适当考虑一些反范式的表设计,增加冗余字段,减少JOIN
资金字段考虑统一*100处理成整型,避免使用decimal浮点类型存储
日志类型的表可以考虑按创建时间水平切割,定期归档历史数据
3)Schema设计目标
快速实现功能为主,保证节省资源
平衡业务技术各个方面,做好取舍
不要在DB里进行大计算,减少复杂操作
整体来说,这部分规范还是很容易遵守的,实现起来也没有什么难度,就能取得很好的效果。
2、运维规范
(1)SQL审核
SQL评审这部分工作相信让很多的DBA同学都叫苦不迭,人肉审核不仅效率低下,容易出错,对DBA的自身发展也非常不利,难道我们来上班就是为了审核SQL的吗?在经过了一段痛苦的人肉审核之后,我们接入了去哪儿网开源的Inception,并根据自身的业务特点做了一些调整。当然现在开源的SQL评审软件已经很多了,大家可以自由选择,也可以自行开发。
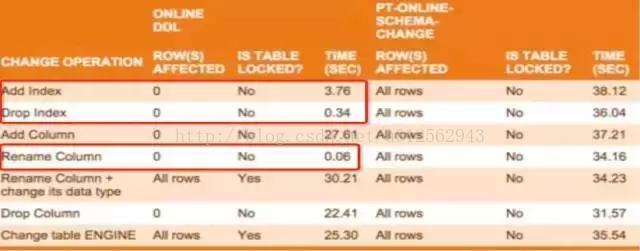
在审核与执行上线DDL语句的时候,要注意MySQL官方原生Online DDL和Percona公司的pt-osc之间的一些差异,例如pt-osc在执行时每次都要copy全表,相对来说比较慢,好处是不锁表,并且有完善的条件检测和延时负载策略控制。官方Online DDL虽然官方也一直在改进,但生产环境使用还不是很完美,尤其要注意执行过程中容易导致MDL锁。官方Online DDL也有优于pt-osc的地方,比如增删索引,重命名列等,如下图所示。
(2)权限控制
MySQL从5.6开始,逐步完善了权限系统,比如MySQL5.6可以安装检查密码强度的插件,5.7开始增加了密码过期机制、账户锁定等功能,对SSL这一块也做了一些优化,8.0版本增加了角色的功能,权限系统已经逐步在向Oracle数据库靠拢了。在日常运维中,也可以使用pt-show-grants工具提高权限审查的力度。应用程序账号应只赋予SELECT、INSERT、UPDATE权限,DELETE的逻辑改用UPDATE实现,并启用sql_safe_updates选项。
另一个有效控制权限的方法就是SQL堡垒机,早期我们通过改造MyWebSQL实现,在Web版客户端的基础上加入了一些资源控制策略、审计、语法校验等功能。后续又使用Python开发了功能更完备的SQL堡垒机,同时支持MySQL、Oracle、Greenplum等数据库。
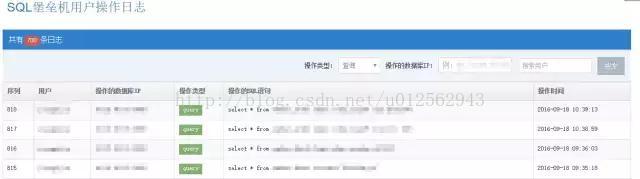
SQL堡垒机不仅可控制公司内部人员的数据库权限,追溯各类人员对数据库的操作,也能避免大查询或全表更新的情况发生,支持审计需求,整体运维质量提升了一个台阶。
(3)MySQL版本选择
MySQL社区版,用户群体最大
MySQL企业版,收费
Percona Server版,新特性多,和MySQL社区版最接近
MariaDB版,国内用户暂时不多
选择优先级:MySQL社区版> Percona Server > MariaDB > MySQL 企业版
对于版本选择这件事,建议大家还是跟进官方社区版比较好,目前比较稳定的版本是MySQL5.6,推荐大家使用。有特殊需求的话再选择MySQL5.7、PXC、TiDB、TokuDB等数据库。
二、MySQL高可用架构选型
MySQL高可用方面,目前业界主流依然是基于异步复制的技术,例如Keepalived、MHA、ZooKeeper等,要求数据强一致的场景逐步开始使用分布式协议,这方面的典型代表有PXC、Group Replication、TiDB。下面我们就重点来说说keepalived、MHA和PXC这几种大家用得比较多的架构。
1、keepalived高可用架构
业内使用非常普遍,它部署容易、方便维护,还节省服务器资源。这种架构的一个好处就是在发生切换后,原Master只需重新拉起来即可恢复高可用,不需要过多干预。扩展起来也方便,可以任意挂载只读库和灾备库。但它存在的问题也很明显,比如Keepalived的检测机制不完善、有脑裂隐患、数据一致性较弱等等。
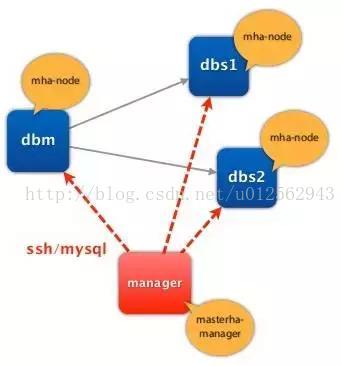
还需要注意主从拓扑的设计。如下图,只读库挂到哪个Master比较合适?显然是M2,其它两种拓扑在发生切换后都会影响到只读库的访问。
2、MHA
MHA自诞生以来,就得到了业内的广泛关注,并迅速流行开来。与keepalived相比,MHA最大的优点就是在发生故障切换之后,能自动补齐binlog,最大程度保证数据一致性。从服务器能自动切换,无需人工干预,能非常好的工作在读写分离的环境下。基于Perl语言的脚本也非常方便进行二次开发。MHA非常适合读写压力比较大的应用。
但由于MHA在工作时需要配置SSH互信,因此选择这种架构时内网安全一定要做到位。另外也可以搭配Binlog Server使用。
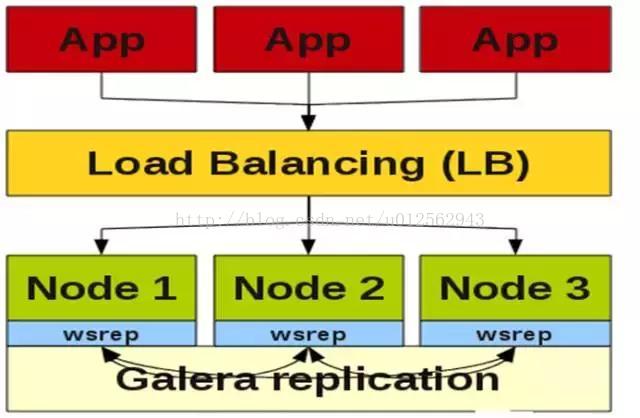
3、PXC
PXC全称是Percona XtraDB Cluster,是Percona公司基于Galera协议开发的一个产品。PXC牺牲了CAP里面的P(Partition Tolerance),保留了C(Consistency )和A(Availability )。这种结构非常适合电商、金融类业务,自PXC和Group Replication出现以后,MySQL彻底扫清了进入金融行业的障碍。
PXC的优势:
同步复制,解决了传统架构复制延迟和脑裂的问题
数据强一致
多主复制,每个节点都可以读写数据
并行复制,多个事务可以并行推送到其他节点
高可用,单点故障不影响集群可用性
新节点自动部署
与传统MySQL几乎完全兼容
使用PXC要注意的问题:
不要有大事务
木桶效应,集群性能取决于性能最差的那个节点
并发效率有损失
网络要求较高,建议万兆网络
多点并发写时锁冲突、死锁问题多
写无法扩展,无法解决热点更新问题
除此之外,还有一类采用DNS/ZooKeeper的高可用架构,这种架构通常都需要自行开发,无通用的方案,比较适合大规模集群的高可用,这里我们不过多赘述。
下面简单回顾一下上述几种高可用架构:
双Master架构:非常成熟,使用很普遍,要注意延迟和数据的一致性。
PXC: 分布式协议,数据强一致性,并发效率略低,可用性好
MHA:各项指标介于M-M和PXC之间,性能无损失,适合读写分离架构。
总而言之,没有最完美的架构,只有最适合的架构。选择适合自己业务的即可。
三、MySQL sharding拆分
接下来是第三个议题,MySQL拆分原则和分库分表设计。
首先先提一个问题,为什么要拆,不拆不行吗?按照我们的经验来看,当数据和业务到了一定的规模,都不可避免的要面临分库分表的问题。这就好像汽车的发动机一样,要达到更高的性能,4缸6缸明显是不够用的,V8、V12才是王道。
拆分能解决如下几个问题:
单库并发较大
单库物理文件太大
单表过大,DDL无法接受
防止出现性能瓶颈,提升性能
防止出现抖动不稳定现象
确定要进行数据库的拆分了,应该怎么拆呢?
垂直拆分
优点:
拆分简单明了,拆分规则明确
应用程序模块清晰,整合容易
数据维护方便易行,容易定位
缺点:
表关联需要改到程序中完成
事务处理变的复杂
热点表还有可能存在性能瓶颈
过度拆分会造成管理复杂
水平拆分
优点:
不会影响表关联、事务操作
超大规模的表和高负载的表可以打散
应用程序端改动比较小
拆分能提升性能,也比较易扩展
缺点:
数据分散,影响聚集函数的使用
切分规则复杂,维护难度增加
后期迁移较复杂
要先分库还是先分表?
分库的优点:实现简单,库与库之间界限分明,便于维护,缺点是不利于频繁跨库操作,单表数据量大的问题解决不了。
分表的优点:能解决分库的不足点,但是缺点恰恰是分库的优点,分表实现起来比较复杂,特别是分表规则的划分,程序的编写,以及后期的数据库拆分移植维护。
一巴掌拍板直接选分库或分表都是不可取的,主要是看需要达到什么样的扩展方式,才能决定先分库还是先分表,根据具体的场景决定。分库分表的最终目的还是为了扩展,而且要看拆分的规划设计是针对哪一层。
上述问题都解决了,该考虑如何实现了,到底是在应用程序中实现,还是使用中间件?个人建议如果是小规模的拆分,直接在程序逻辑中实现即可,大规模的拆分再考虑使用各种中间件。
目前业内已经开源了很多的MySQL中间件产品,例如Atlas、DBProxy、MyCAT、OneProxy、DRDS、Vitess等等,每个中间件都有自己的特点,个别不太成熟的可能会存在一些Bug,选用之前要做好相关的调研与测试工作,上线使用一定要保证自己能hold住。如果要完全贴合自身业务,并且掌控得较好的还是要自行开发。
下面说说我们的拆分经验。
首先我们先在压力比较大的数据库上做垂直拆分,剥离出活动、后台统计等业务。这一步也是最容易实现的。
接下来,如果是消息类的数据,就基于时间维度进行拆分,单表控制在5-10G,行数控制到500-1000w这个样子。这个时候我们发现数据库的性能是比较好的,而且比较好维护。如果是用户类的数据,就按照Hash或Range进行拆分。这种情况下用这种方法拆分会拆的比较均匀一些。
并发仍然比较高怎么办?可以在时间维度拆分的基础上再按Range或Hash进行拆分。
最后要注意的就是不要过度的拆分,会造成复杂度的上升。Schema设计合理的情况下,10亿的数据量也能跑的好好的。个别不关键的应用,例如日志、监控数据等,使用分区表、TokuDB也能抗。拆分对应用层总是有损的。
要做个“懒”DBA。
MySQL架构设计谈:从开发规范、选型、拆分到减压
四、利用NoSQL为MySQL减压
最后一个议题,我们聊一聊NoSQL。NoSQL现在遍地开花,应用也很广泛了,业内用的比较多的主要集中在Redis、MongoDB、Cassandra等NoSQL数据库上。今天我们主要来说说和MySQL关联最为密切的Redis。
为什么要使用Redis?
数据存储在内存中,访问速度快
能支持大批量操作及爆发性负载
数据结构丰富,有效缓解MySQL压力
协议简单,支持各种语言的API
存储大量数据无需担心性能
Redis主要作用还是抗读的压力。读操作先到Redis,Redis中取不到再从MySQL数据库访问,从MySQL读取到数据后,还要回写到Redis。
使用Redis要注意的几点:
性能方面,由于Redis完全是基于内存的访问,性能无需担心。
在使用Redis时,要注意Cache 和Storage不要混合使用。不要依赖Redis的持久化,持久化这一块Redis要努力的还很多。另外如果你把Redis拿来做Storage的话,一旦Redis的内存跑满,那就惨了,所有的Redis连接都会卡着不响应。如果只是把Redis来做cache的话,那问题就不大。
还有诸如缓存穿透、缓存雪崩、热点key重建时缓存失效这些问题也是重点关注的对象。
如何利用Redis给MySQL加速:
1)利用K/V结构,缓存结果,例如存储用户信息、全局排行、统计信息等。
2)利用其丰富的数据结构为MySQL减压,例如计数器、排序、Hash(把表映射到Redis中)、消息队列等。
总结
系统架构设计是一个长期总结与进化的过程,讲究均衡与取舍。在进行大规模MySQL架构设计的过程中,除了要汲取别人的经验之外,还要关注各种架构背后的业务场景与架构思想,与自己的实际业务场景相结合,才能设计出一个好的系统架构来。














 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









