







Redis原理
转自:http://m.blog.csdn.net/article/details?id=51518928
redis是一种高性能的key-value数据库。
一、 redis目前使用有两种场景,一种是作为缓存,一种是作为数据库使用。
当作为缓冲使用时,如图,视图已经被某大神画好,感激。。。

图解,访问时,如果key存在时,直接获取key的值,返回给客户端;如果key不存在时,则去持久化数据库中获取数据,返回给用户,并缓存redis。
适用场合:数据量大而且不经常变更。
当作为数据库时,如图

优点:用redis做数据库,更新速度快,适合频繁变化的数据。
缺点:对redis的依赖大,做好故障时的数据的保存。
难点:前期时key的格式设计,更好的保存到db中。
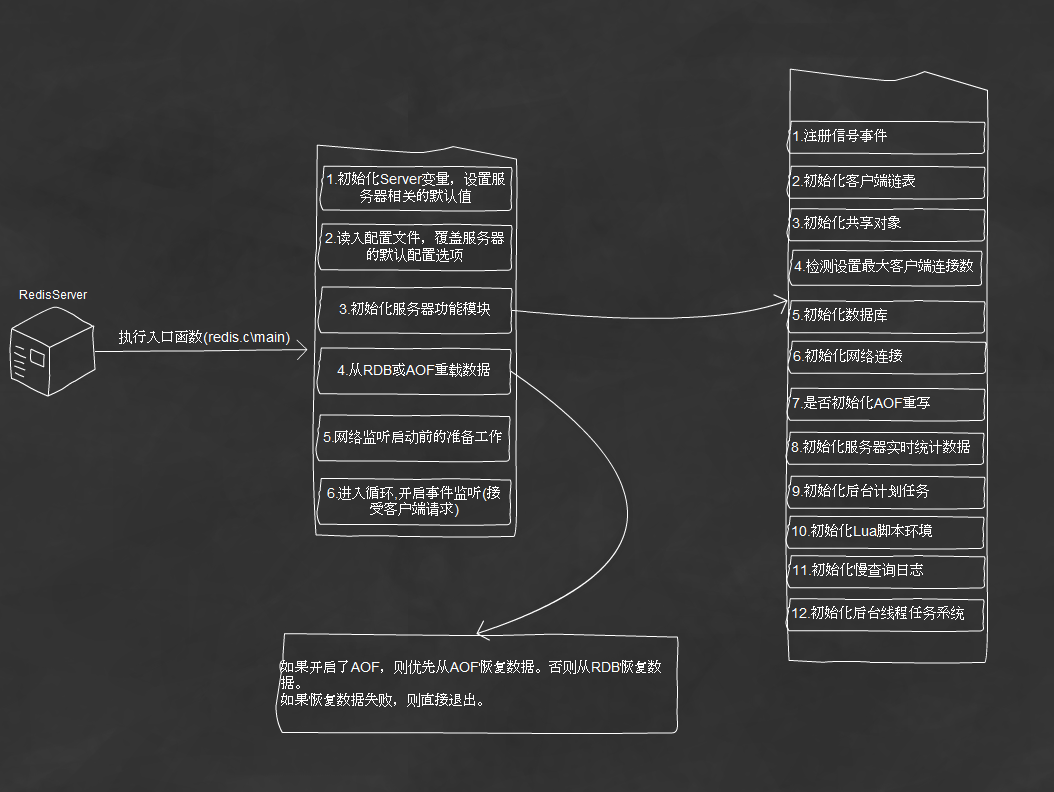
二、 redis的启动流程。
再次感谢大神提供的视图。。。
三、redis 数据库的持久化方案
1、RDB持久化方案
在redis运行时,reb程序会将当前内存中的数据的快照保存到磁盘中,redis需要重启时,rdb程序会通过重载rdb文件来还原数据。
看出rdb有两个功能:
保存(rdbsave):rdbsave负责将数据库中的数据转换成RDB的格式保存到磁盘,如果rdb文件存在则替换,在保存的时候进程会发生阻塞,影响其他客户端请求:
为了避免阻塞,redis提出了rdbsavebackgroup函数,在新建的子进程中调用rdbsave,完成保存后发送型号通知主进程,主进程继续处理客户端请求。
读取(rdbload):当Redis启动时,会根据配置的持久化模式,决定是否读取RDB文件,并将其中的对象保存到内存中。
2、AOF持久化方案
以协议文本的方式,将所有对数据库写入的命令保存到AOF文件中,达到记录数据库状态的目的。
a保存)
1、将客户端请求命令转化为网络协议格式。
2、将协议内容追加到server.aof_buf中。
3、当达到aof系统设定的条件时,会调用aof_fsync(文件描述符)写入到磁盘
其中第三步才是aof的性能关键,目前redis支持三种状态:
1、AOF_FSYNC_NO:不保存
此模式,每执行一条客户端的命令,都将会把协议字符串追加到serveraof_buf中,但不会写入磁盘。
写入只发生在:1、redis被正常关闭。2、Aof被关系。3、系统写缓存已满,或后台定时保存操作被执行。
上面三种情况都会阻塞主进程,导致客户端请求失败。
2、.AOF_FSYNC_EVERYSECS:每一秒保存一次
由后台子进程调用写入保存,不会阻塞主进程。如果发生宕机,那么最大丢失数据会在2s以内的数据。这也是默认的设置选项。
3、AOF_FSYNC_ALWAYS:每执行一个命令都保存一次
这种模式下,可以保证每一条客户端指令都被保存,保证数据不会丢失。但缺点就是性能大大下降,因为每一次操作都是独占性的,需要阻塞主进程。
b读取)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









