







 批量归一化(Batch Normalization)是一种用于加速深度网络训练的技术,通过减少内部协变量偏移(Internal Covariate Shift),能够允许使用更大的学习率并起到正则化的作用。在训练时,它对每个迷你批次的数据进行归一化,而在推断时则使用全部数据的均值和方差。批量归一化不仅提升了模型的训练速度,还在某些情况下可以替代Dropout,提高模型的泛化能力。实验表明,批量归一化在卷积网络中尤其有效,可以稳定激活函数的输入分布,优化网络性能。
批量归一化(Batch Normalization)是一种用于加速深度网络训练的技术,通过减少内部协变量偏移(Internal Covariate Shift),能够允许使用更大的学习率并起到正则化的作用。在训练时,它对每个迷你批次的数据进行归一化,而在推断时则使用全部数据的均值和方差。批量归一化不仅提升了模型的训练速度,还在某些情况下可以替代Dropout,提高模型的泛化能力。实验表明,批量归一化在卷积网络中尤其有效,可以稳定激活函数的输入分布,优化网络性能。
论文题目:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
首先看看博客http://blog.csdn.net/happynear/article/details/44238541中最开始介绍的:
为什么中心化,方差归一化等,可以加快收敛?
补充一点:输入x集中在0周围,sigmoid更可能在其未饱和区域,梯度相对更大一些,收敛更快。
Abstract
1.深层网络训练时,由于模型参数在不断修改,所以各层的输入的概率分布在不断变化,这使得我们必须使用较小的学习率及较好的权重初值,导致训练很慢,同时也导致使用saturating nonlinearities 激活函数(如sigmoid,正负两边都会饱和)时训练很困难。
这种现象加 internal covariate shift ,解决办法是:对每层的输入进行归一化。
本文方法特点是 :making normalization a part of the model architecture and performing the normalization for each training mini-batch
Batch Normalization 让我们可以使用更大的学习率,初值可以更随意。它起到了正则项的作用,在某些情况下,有它就不需要使用Dropout了。
在Imagenet上, achieves the same accuracy with 14 times fewertraining steps
Introduction
1. SGD:
用minibatch去近似整个训练集的梯度,在并行计算下,m个合成一个batch计算比单独计算m次快很多。
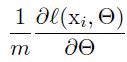
2.SGD虽然简单高效,但是需要调节很多超参,学习率,初值等。各层权重参数严重影响每层的输入,输入的小变动随着层数加深不断被放大。
这带来一个问题:各层输
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









