【场景实例】
我们每天都会用百度、Google等搜索引擎去查询一些相关东西,我们也经常会上淘宝、京东等网站去搜索自己想要的东西,我们的搜索,广泛、不确定,但我们同样可以快速、高效地得到搜索结果。
【搜索方案】
其实,对于这些数据量大、数据结构不固定的数据,通常都采用全文检索方式搜索。
那么,什么是全文检索呢?如下:
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。从非结构化数据中提取出然后重新组织的信息,称之为索引。因此,先建立索引,再对索引进行搜索的过程叫全文检索。
【如何实现】
用Lucene就可以实现全文搜索,另外,solr和elasticsearch都是基于Lucene实现的开源搜索引擎,也可以实现。
1. Lucene:其是Apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。其目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能。
2. Solr:其是Apache下的一个顶级开源项目,采用Java开发,基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
3. Elasticsearch:其是一个基于Apache Lucene(TM)的开源搜索引擎。其也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
整个搜索的过程,可分为两个过程:索引过程和查询过程。
【索引过程】
索引过程是指对要搜索的原始内容进行索引,构建一个索引库。主要包括:确定原始内容 —> 采集文档 —> 创建文档 —> 分析文档 —> 索引文档。
1. 获得原始文档:原始文档是指要索引和搜索的内容。原始内容可以是互联网上的网页、数据库中的数据和磁盘上的文件等。
2. 信息采集:从互联网上、数据库、文件系统中等获取需要搜索的原始信息,这个过程是信息采集,目的是为了对原始内容进行索引。
3. 创建文档对象:获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档,文档中包括一个个域(Field),域中存储内容。比如,我们可以将磁盘上的一个文件当成一个document,document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容),如下图:
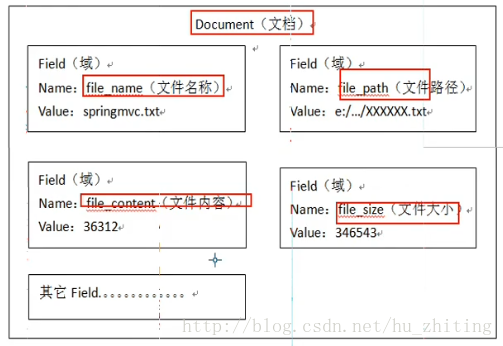
4. 分析文档:将原始内容创建为包含域的文档,需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成的最终的语汇单元,可以将语汇单元理解为一个个单词。
5. 创建索引:对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document。
以上过程,代码如下:
@Test
public void testIndex() throws Exception {
Directory directory=FSDirectory.open(new File("D:\\temp\\index"));
Analyzer analyzer=new StandardAnalyzer();
IndexWriterConfig config=new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
IndexWriter indexWriter=new IndexWriter(directory, config);
File f=new File("D:\\Lucene");
File[] listFiles = f.listFiles();
for (File file : listFiles) {
Document document=new Document();
String file_name = file.getName();
Field fileNameField=new TextField("fileName", file_name, Store.YES);
long file_size = FileUtils.sizeOf(file);
Field fileSizeField= new LongField("fileSize", file_size, Store.YES);
String file_path = file.getPath();
Field filePathField=new StoredField("filePath", file_path);
String file_content = FileUtils.readFileToString(file);
Field fileContentField=new TextField("fileContent", file_content, Store.YES);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField);
indexWriter.addDocument(document);
}
indexWriter.close();
}
【查询过程】
查询过程是指从索引过程中创建好的索引库进行查询,主要包括:用户通过搜索界面 —> 创建查询 —> 执行搜索,从索引库搜索 —> 渲染搜索结果。代码如下:
@Test
public void testSearch() throws Exception{
Directory directory=FSDirectory.open(new File("D:\\temp\\index"));
IndexReader indexReader =DirectoryReader.open(directory);
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
Query query=new TermQuery(new Term("fileName","lucene.txt"));
TopDocs topDocs = indexSearcher.search(query, 2);
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int doc=scoreDoc.doc;
Document document = indexSearcher.doc(doc);
String fileName = document.get("fileName");
System.out.println(fileName);
String fileContent = document.get("fileContent");
System.out.println(fileContent);
String filePath = document.get("filePath");
System.out.println(filePath);
String fileSize = document.get("fileSize");
System.out.println(fileSize);
System.out.println("----------");
}
indexReader.close();
}
【小结比较】
通过上面两个过程,我们大致了解了Lucene的实现原理,而solr和elasticsearch是基于Lucene实现的,原理也是一样,可能所涉及的一些概念略有差别。
1. solr与Lucene
- Lucene本质上是搜索库,不是独立的应用程序,而Solr是。
- Lucene专注于搜索底层的建设,而Solr专注于企业应用。
- Lucene不负责支撑搜索服务所必须的管理,而Solr负责。
所以说,一句话概括 Solr: Solr是Lucene面向企业搜索应用的扩展。
2. solr与Elasticsearch
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式。
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供。
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。






















 1353
1353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









