







一、数据来源
数据来源关系到分析结果的准确性和权威性,因此数据源主要从以下四个网站抓取:
- 搜房网
- 安居客
- 58同城
- 赶集网
搜房网和安居客分别是中国站长之家的房产类网站排名的1和2,58同城和赶集网是运营比较好的综合性服务网站。
二、主要抓取的数据
网站上的数据是比较复杂的,主要抓取新房、二手房和出租房的主要信息。
2.1新房
| 小区 | 房价(元/平方米) | 出售数量 |
|---|---|---|
2.2二手房
| 小区 | 地址 | 房价 | 出售数量 |
|---|---|---|---|
2.3出租房
| 地址 | 价格 | 面积 | 平方面积 |
|---|---|---|---|
三、Python抓取58同城出租房数据
选择使用Python2.7来抓取网站数据,用到的主要是BeautifulSoup和Urllib2。实现的思路比较简单,首先用urllib2来获取网站的数据,再通过BeautifulSoup来抽取我们需要的数据。
3.1获取网页源码
为了方便后期的使用,我们写成了一个函数。
def getSoup(url):
request = urllib2.Request(url)
reponse = urllib2.urlopen(request)
contents = reponse.read()
soup = BeautifulSoup(contents,from_encoding="utf-8")
return soup
3.2抽取我们需要的数据
(1)URL地址
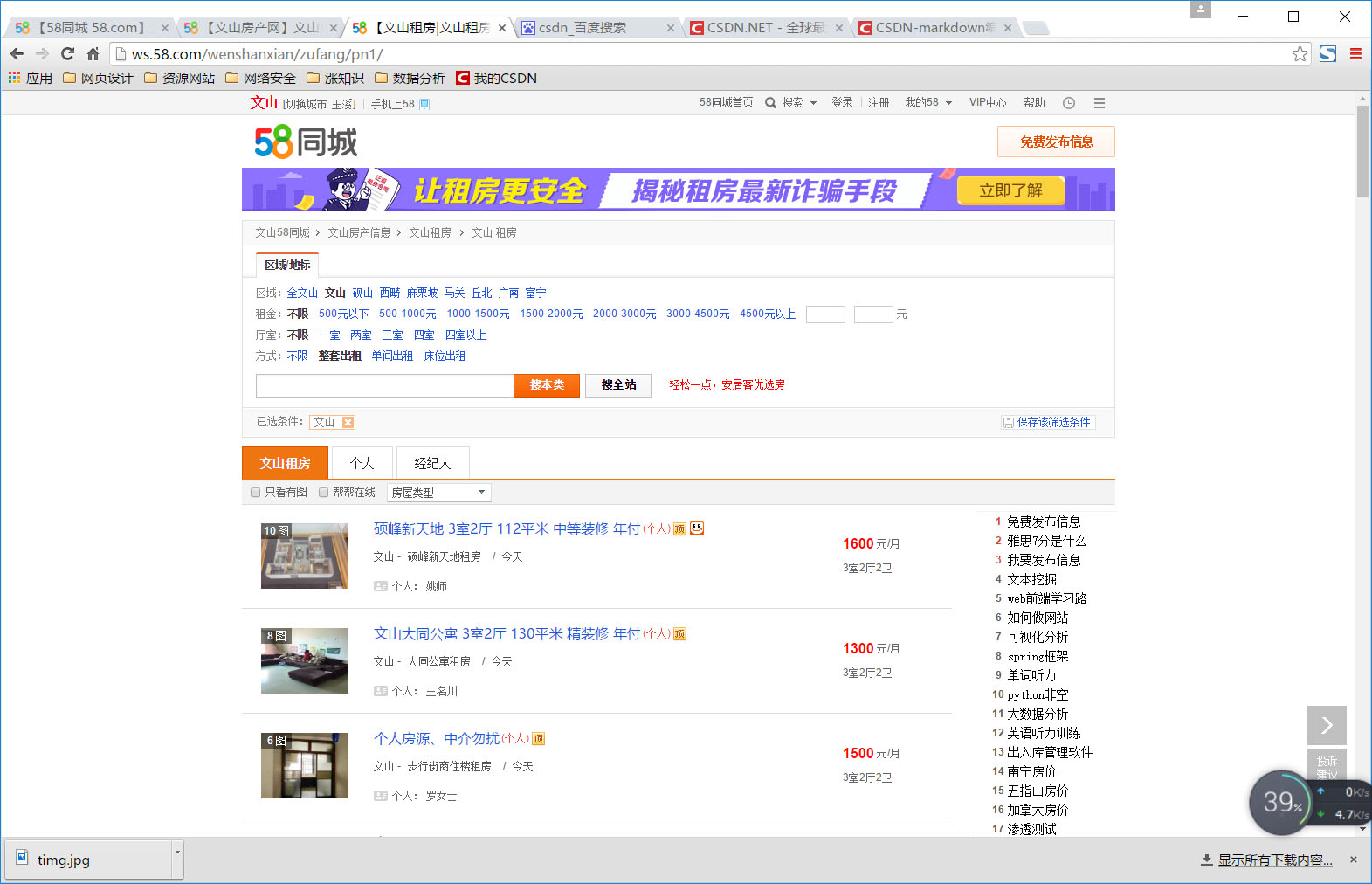
在58同城上找到文山市相关房产数据的地址
zufan_url = 'http://ws.58.com/wenshanxian/zufang/pn1/'(2)抽取数据
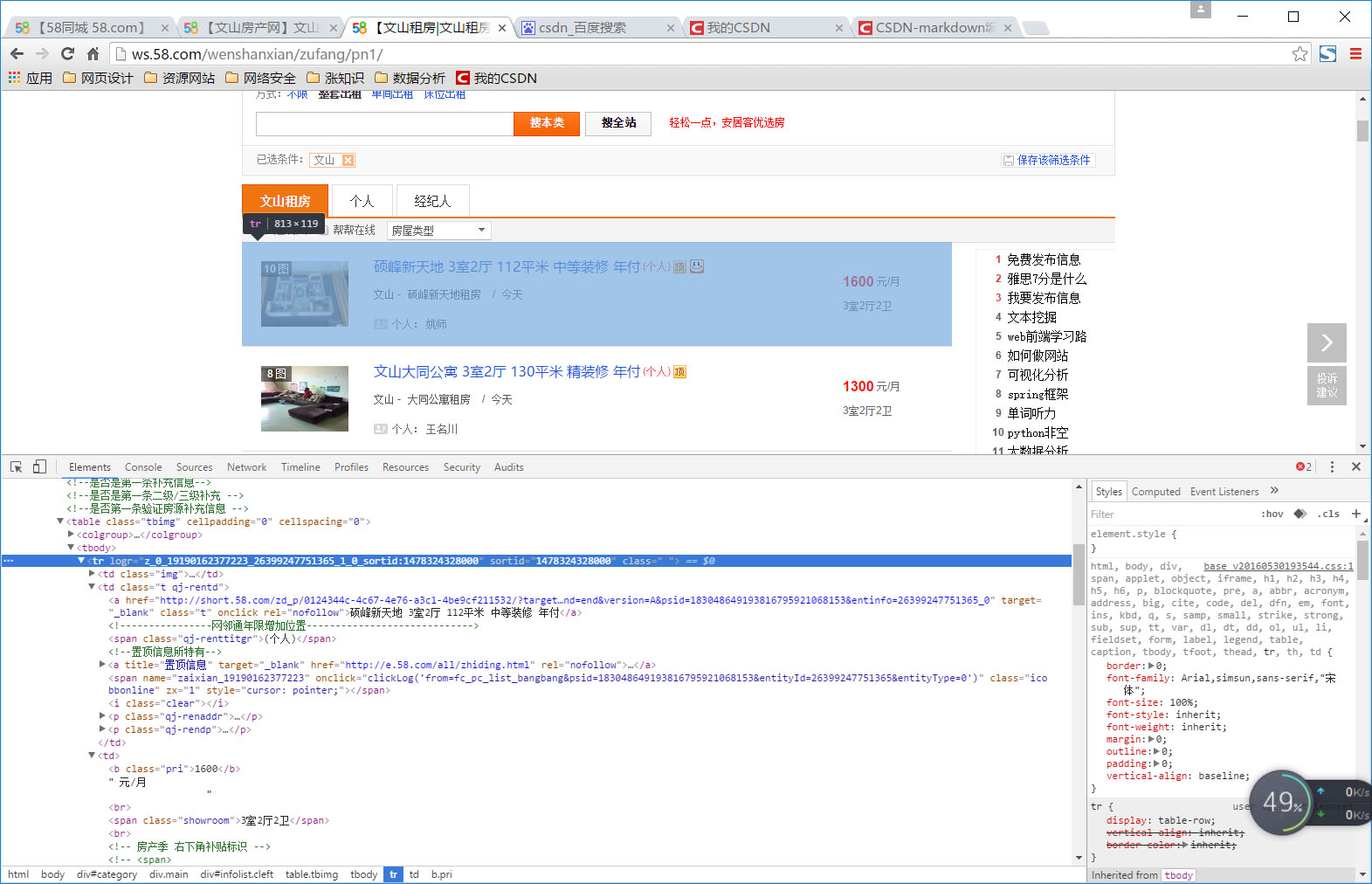
在之前的需求分析阶段定义了需要的主要信息是出租房的地址、价格和,我利用Chrome自带的开发者工具查找到了在源码中的位置,再用BeautifulSoup进行解析,获得了我们需要的数据。
def get58ZuFanData(url):
soup = getSoup(url)
zufang_row = []
for tag in soup.find('table',class_='tbimg').find_all('tr'):
Td_list = tag.find_all('td')
Title = Td_list[1].a.get_text()
Title_link = Td_list[1].a['href']
detail_soup = getSoup(Title_link)
Price = detail_soup.find('ul',class_='house-primary-content').em
if Price:
Price = Price.get_text()
Type = detail_soup.find('div',class_='house-type').get_text()
print Title
print Price
Address = Td_list[1].p.get_text()
zufang_info = [Title,Address,Price,Type]
zufang_row.append(zufang_info)
return zufang_row(3)保存数据到csv文件中
为了接下来的工作顺利进行,我们需要将所抓取的数据保存到本地。我用了最简单的方式–保存到csv文件中。
if __name__ == '__main__':
wuba_zufanglist = []
for zufang_i in range(1,41):
zufan_url = 'http://ws.58.com/wenshanxian/zufang/pn'+ str(zufang_i) +'/'
wuba_zufanglist.extend(get58ZuFanData(zufan_url))
wuba_zufang = pd.DataFrame(wuba_zufanglist)
wuba_zufang.to_csv('data/wuba_zufang.csv',encoding='utf-8')最终得到的数据结果为:
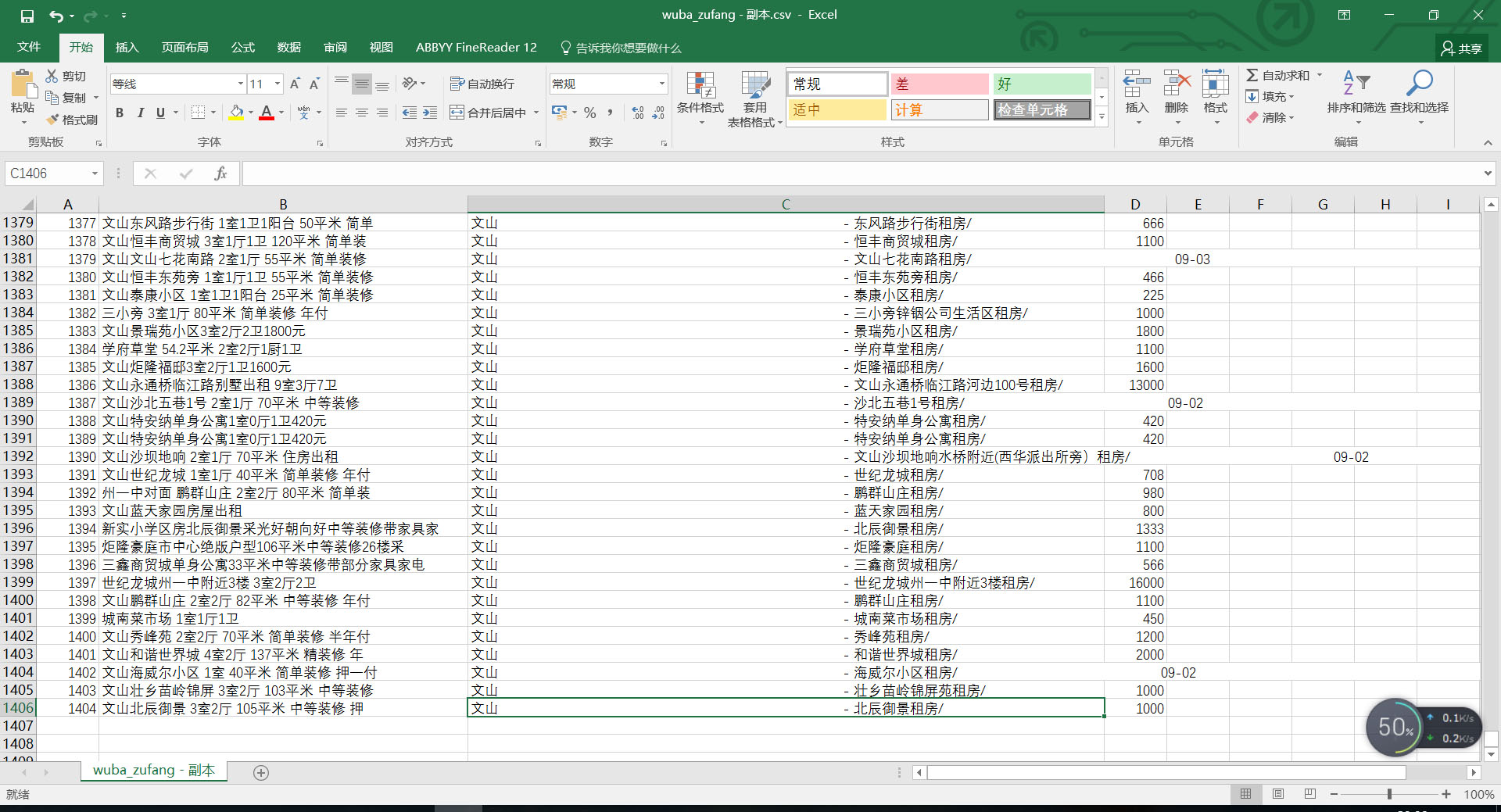















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









