







一,概述:
流的介绍:流的概念源于Unix中管道的概念,管道是一条不间断的流,用来实现程序或者进程间的通信,或读写外围设备,外部文件等。一个流必须有源端和目的端,他们可以实现进程或者进程间的通信,或读写外围设备迈步文件等。
流的方向是重要的,根据流的方向,流可分为两类:输入流和输出流。用户可以从输入流中读取信息,但不能写它。相反,对输出流,只能往输入流写,而不能读它。实际上,流的源端和目的端可简单地看成是字节的生产者和消费者,对输入流,可不必关心它的源端是什么,只要简单地从流中读数据,而对输出流,也可不知道它的目的端,只是简单地往流中写数据。
形象的比喻——水流 ,文件======程序 ,文件和程序之间连接一个管道,水流就在之间形成了,自然也就出现了方向:可以流进,也可以流出.便于理解,这么定义流: 流就是一个管道里面有流水,这个管道连接了文件和程序。
二,流的分类:
图例:
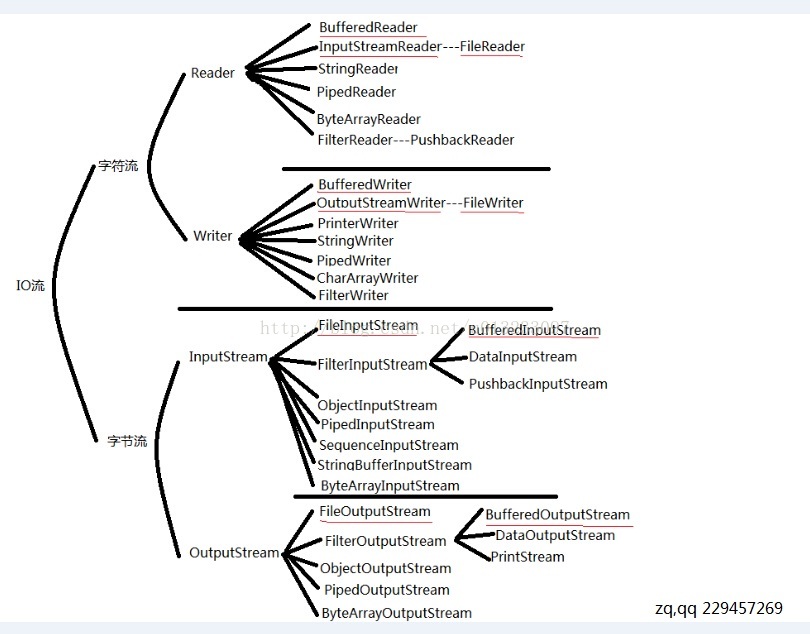
1,java.io包中的类对应两类流:
一类流直接从指定的位置(如磁盘文件或内存区域)读或写,这类流称为结点流(node stream),
其它的流则称为过滤器(filters)。过滤器输入流往往是以其它输入流作为它的输入源,经过过滤或处理后再以新的输入流的形式提供给用户,过滤器输出流的原理也类似。
定义流: 流就是一个管道里面有流水,这个管道连接了文件和程序。
2,Java的常用输入、输出流:
java.io包中的stream类根据它们操作对象的类型是字符还是字节可分为两大类: 字符流和字节流。
输入流:InputStream(字节流),Reader(字符流)。输出流:OutputStream(字节流),Writer(字符流)。
三,字符流介绍:
1,字节流不能操作Unicode字符,由于Java采用16位的Unicode字符,即一个字符占16位,所以要使用基于字符的输入输出操作。所以创造了字符流,以提供直接的字符输入输出的支持。字符流处理的单元为 2 个字节的 Unicode 字符,分别操作字符、字符数组或字符串。
2,字符流主要是用来处理字符的。Java采用16位的Unicode来表示字符串和字符,对应的字符流按输入和输出分别称为reader和writer。专门用于操作的否是字符数据的流对象。
3,Reader:
用于读取字符流的抽象类,子类必须实现的方法只有:reader(char[],int,int)和close()。read():读取单个字符并返回,read(char[]):将数据读取到数组中,并返回读取的个数。
4,Writer:
写入字符流的抽象类。子类必须实现的方法仅有 write(char[], int, int)、flush() 和 close()。但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能。
5,FileReader:
用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。要自己指定这些值,可以先在 FileInputStream 上构造一个 InputStreamReader。FileReader 用于读取字符流。要读取原始字节流,请考虑使用FileInputStream。
6,FileWriter
用来写入字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。要自己指定这些值,可以先在 FileOutputStream 上构造一个 OutputStreamWriter。
复制文本文件实例:
package File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class CopyTextTest {
public static void main(String[] args) throws IOException {
// 练习:复制文本文件:
// 思路:
// 使用字符流,操作的为文件,涉及硬盘,默认编码。
// 使用fileReader 和FileWriter。
copyTextFile();
}
private static void copyTextFile() throws IOException {
//复制时先明确源文件和目的
FileReader fr = new FileReader("e:\\file.txt");
FileWriter fw = new FileWriter("e:\\fw.txt");
//该方法循环效率低:
/*int ch = 0;
while((ch=fr.read())!=-1){
fw.write(ch);
}*/
//自定义缓冲区数组,字符数组。此方法效率较高:
char[] buf = new char[1024];//一个字符两个字节,开辟了2k个大小的数组char[]。
int len=0;
while((len=fr.read(buf))!=-1){
fw.write(buf,0,len);
}
fw.write(buf);
fr.close();
fw.close();
}
}
7,BufferedReader和BufferedWriter:
缓冲区的原理:
1,使用了底层流对象从具体设备获取数据,并将存储到缓冲区中的数组内。
2,可以通过缓冲区的read方法,从缓冲区中来获取具体的字符数据。
3,如果用read()方法读取字符数据,并存储到另一个容器中,直到读取到了换行符时,另一个容器中临时存储的数据准成字符串返回,就形成了readline()功能。
package file;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
public class CopyFileByBuffer {
//通过缓冲区复制一个.java文件
public static void main(String[] args) throws Exception {
BufferedReader bufr = null;
BufferedWriter bufw = null;
bufr = new BufferedReader(new FileReader("e:\\java\\ThreadDemo.java"));
bufw = new BufferedWriter(new FileWriter(new File("e:\\","ThreadDemo.java")));
String line = null;
while((line=bufr.readLine())!=null){
bufw.write(line);
bufw.flush();
}
}
}
四,字节流介绍:
1,字节流:字节流就是存储类的二进制原始信息,不需要翻译。字节流处理单元为 1 个字节,操作字节和字节数组。
2,InputStream 和 OutputStream 是两个 abstact 类,对于字节为导向的 stream 都扩展这两个鸡肋(基类 ^_^ )。
outputStream:输出字节流的超类,1,操作的数据都是字节,2,定义了输出字节流的基本共性功能,输出流中定义都是些write方法,它可以操作字节数组write(byte[]),操作单个字节write(byte)。
InputStream:字节输入流的超类。
1,常见功能,
int read():读取一个字节并返回。没有字节则返回-1。
int read(byte[]):读取一定量的字节数,并存储到字节数组中。返回读取到的字节数。
3,FileInputStream和FileOutputStream:
这两个类属于结点流,第一个类的源端和第二个类的目的端都是磁盘文件,它们的构造方法允许通过文件的路径名来构造相应的流。如: FileInputStream infile = new FileInputStream("myfile.dat");FileOutputStream outfile = new FileOutputStream("results.dat");要注意的是,构造FileInputStream, 对应的文件必须存在并且是可读的,而构造FileOutputStream时,如输出文件已存在,则必须是可覆盖的。
代码实例:
<pre name="code" class="java">package File;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopyTest {
//复制文件练习:
public static void main(String[] args) throws IOException {
/*//1,明确源和目的
File srcFile = new File("e:\\java\\car.java");//可以复制音乐文件
File destFile = new File("e:\\java.txt");
//2,明确字节流 输入流和源相关联,输出流和目的关联。
FileInputStream fis = new FileInputStream(srcFile);
FileOutputStream fos = new FileOutputStream(destFile);
//3,使用输入流的读取方式读取字节,并将字节写入到目的中.一次读取一个字节,并写入一次一个字节。
int ch = 0;
while ((ch = fis.read())!=-1){
fos.write(ch);
} */
//自定义缓冲数组复制文件:
/*//1,明确源和目的
File srcFile = new File("e:\\java\\car.java");//可以复制音乐文件
File destFile = new File("e:\\java.txt");
//2,明确字节流 输入流和源相关联,输出流和目的关联。
FileInputStream fis = new FileInputStream(srcFile);
FileOutputStream fos = new FileOutputStream(destFile);
//定义一个缓冲区:
byte[] buf = new byte[1024];//一次读取1024个字节,可以改变数字大小。
int len = 0;
while ((len=fis.read(buf))!=-1){
fos.write(buf, 0, len);//将数组中的指定长度的数据写入到输出流中。
}
//4,关闭流资源。
fos.close();*/
FileInputStream fis = new FileInputStream("g:\\图片素材\\df.jpg");
byte[] buf = new byte[fis.available()];//定义一个刚刚好的数组,文件过大容易溢出
fis.read(buf);
String str = new String(buf);
System.out.println(str);
fis.close();
}
}
4.BufferedInputStream和BufferedOutputStream:
它们是过滤器流,其作用是提高输入输出的效率。DataInputStream和DataOutputStream这两个类创建的对象分别被称为数据输入流和数据输出流。这是很有用的两个流,它们允许程序按与机器无关的风格读写Java数据。所以比较适合于网络上的数据传输。这两个流也是过滤器流,常以其它流如InputStream或OutputStream作为它们的输入或输出。
五,使用规律:
IO流中对象的使用规律总结:
解决问题时(处理设备上的数据时)到底该用哪一个对象?
1,明确要操作的数据是数据源还是数据目的。
若是数据源:则能用的:InputStream Reader。(读数据)
若是目的:OutputStream writer(写数据)
先根据需求,明确了要读还是要写。
2,要操作的数据的设备上的数据是字节还是文本?
源数据为字节:InputStream
源数据为文本:reader
目的数据为字节:OutputStream
目的数据问文本:Writer
3,已经明确体系开始寻找要使用的对象:
明确数据所在具体设备?
源设备:
硬盘:文件,File开头。
内存:数组,字符串,常用。
键盘:System.in
网络:Socket(插座)
目的设备:
硬盘:文件,File开头。
内存:数组,字符串,常用。
屏幕:System.Out
网络:Socket
完全可以明确具体要使用哪个流对象。
4,是否需要额外功能?
额外功能:
是否需要转换?需要,则用转换流。InputStreamReader,OutputStream
高效?需要则用缓冲区对象。BufferedXXX
有多个源吗?序列流。SequenceInputStream
对象需要序列化吗?ObjectInputStream,ObjectOutputStream
需要操作基本类型数据保证字节原样性吗?DataOutputStream DataInputStream。
源和目的都是内存的流对象:
字节流:ByteArrayInputStream, ByteArrayOutputStream
字符流:CharArrayReader CharArrayWriter
StringReader StringWriter
原理其实通过流的read,write方法对数组以及字符串进行操作。
关闭这些流都是无效的,因为并未调用系统资源,不需要抛出IOException。
六,细节:
1,OutputStreamWriter:是字符流通向字节流的桥梁:可以使用指定的charSet将要写入流中的字符编码成字节。他的作用就是,将字符串按照指定的编码表转成字节,在使用字节流将这些字节写出去。
2,flush和close区别:
flush:将流中的缓冲区缓冲的数据刷新到目的地,刷新后,流还可以继续使用。
close:关闭资源,但在关闭之前会将缓冲区的数据先刷新到目的地,然后再关闭流,流不可以再使用。
写入数据多,一定要一边写一遍刷新,最后一遍可以不刷新,由close完成刷新并关闭。
字节流操作的是字节数组,字符流操作的是字符数组。
3,继承关系:OutputStreamWriter:
--FileWriter:
InputStreamReader:
--FileReader:
父类和子类功能区别:
osw和isr是字符和字节的桥梁:也可以称之为转换流。
转换流原理:字节流+编码表。
Fw和Fr最为子类,仅作为操作字符文件的便捷类存在,当操作的字符文件,使用的是默认编码表时,可以不用父类,而直接用子类就完成操作了,简化了代码。
InputStreamReader isr = new InputStreamReader(new FileInputStream("sds.txt"));//使 用了默认编码表
InputStreamReader isr = new InputStreamReader(new FileInputStream("sds.txt"),“gbk”);//指定编码表为gbk
FileReader fr = new FileReader("a.txt");//不能指定编码变,只能使用默认编码表,与上面两句意思一样。最为便捷。
一旦要指定gdk其他编码时,绝对不能使用子类,必须使用字符转换流。
当操作的是文件,并使用的是默认编码时,使用子类。














 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









