







一、将pyspark放入:
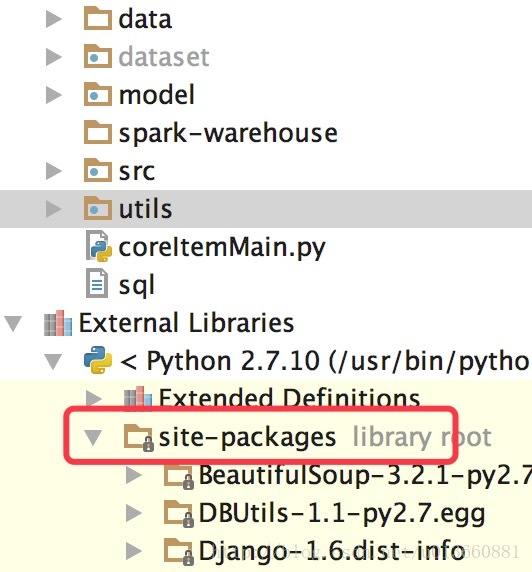
该目录位置(我的是mac):
/Library/Python/2.7/site-packages
二、env配置:
步骤1:
步骤2:
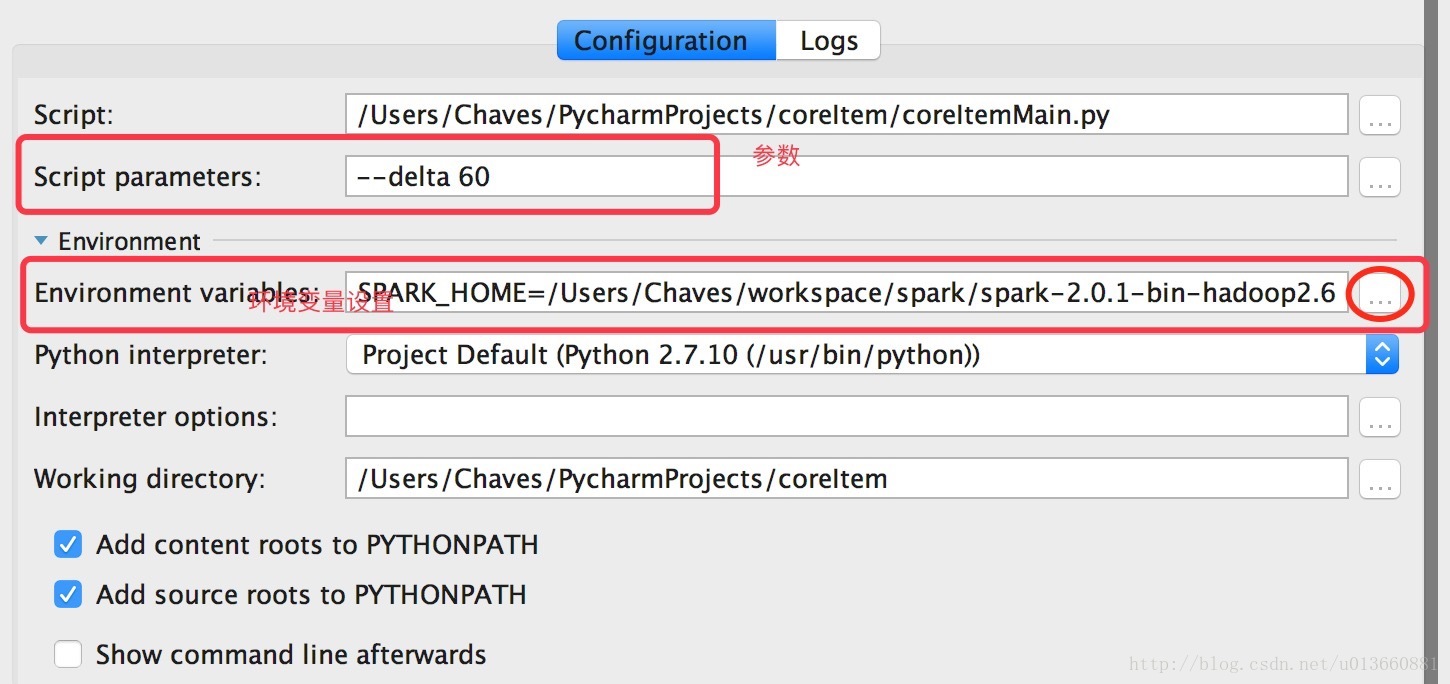
步骤3:
 本文介绍了如何在Mac上使用PyCharm配置和运行Spark 2.0.1。主要内容包括将pyspark添加到Python路径,设置环境变量如SPARK_CLASSPATH和SPARK_HOME,以及详细描述了如何在spark终端运行命令和修改SPARK_CLASSPATH的步骤。此外,还提及了Spark 2.0.1与1.0版本的区别。
本文介绍了如何在Mac上使用PyCharm配置和运行Spark 2.0.1。主要内容包括将pyspark添加到Python路径,设置环境变量如SPARK_CLASSPATH和SPARK_HOME,以及详细描述了如何在spark终端运行命令和修改SPARK_CLASSPATH的步骤。此外,还提及了Spark 2.0.1与1.0版本的区别。
一、将pyspark放入:
该目录位置(我的是mac):
/Library/Python/2.7/site-packages
二、env配置:
步骤1:
步骤2:
步骤3:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6038
6038





