







 本文详细介绍了Spark中的算子,包括Transformation和Action两大类。Transformation算子如map、filter、flatMap、groupByKey等,提供了数据转换的功能,而Action算子如reduce、collect、count等则触发实际的计算并返回结果或保存数据。文章通过Java和Scala示例展示了各种算子的使用方法。
本文详细介绍了Spark中的算子,包括Transformation和Action两大类。Transformation算子如map、filter、flatMap、groupByKey等,提供了数据转换的功能,而Action算子如reduce、collect、count等则触发实际的计算并返回结果或保存数据。文章通过Java和Scala示例展示了各种算子的使用方法。
1. 算子分类
从大方向来说,Spark 算子大致可以分为以下两类
- Transformation:操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
- Action:会触发 Spark 提交作业(Job),并将数据输出 Spark系统。
从小方向来说,Spark 算子大致可以分为以下三类:
- Value数据类型的Transformation算子。
- Key-Value数据类型的Transfromation算子。
- Action算子
1.1 Value数据类型的Transformation算子
| 类型 | 算子 |
|---|---|
| 输入分区与输出分区一对一型 | map、flatMap、mapPartitions、glom |
| 输入分区与输出分区多对一型 | union、cartesian |
| 输入分区与输出分区多对多型 | groupBy |
| 输出分区为输入分区子集型 | filter、distinct、subtract、sample、takeSample |
| Cache型 | cache、persist |
1.2 Key-Value数据类型的Transfromation算子
| 类型 | 算子 |
|---|---|
| 输入分区与输出分区一对一 | mapValues |
| 对单个RDD | combineByKey、reduceByKey、partitionBy |
| 两个RDD聚集 | Cogroup |
| 连接 | join、leftOutJoin、rightOutJoin |
1.3 Action算子
| 类型 | 算子 |
|---|---|
| 无输出 | foreach |
| HDFS | saveAsTextFile、saveAsObjectFile |
| Scala集合和数据类型 | collect、collectAsMap、reduceByKeyLocally、lookup、count、top、reduce、fold、aggregate |
2. Transformation
2.1 map
2.1.1 概述
语法(scala):
def map[U: ClassTag](f: T => U): RDD[U]说明:
将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素
2.1.2 Java示例
/**
* map算子
* <p>
* map和foreach算子:
* 1. 循环map调用元的每一个元素;
* 2. 执行call函数, 并返回.
* </p>
*/
private static void map() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> datas = Arrays.asList(
"{'id':1,'name':'xl1','pwd':'xl123','sex':2}",
"{'id':2,'name':'xl2','pwd':'xl123','sex':1}",
"{'id':3,'name':'xl3','pwd':'xl123','sex':2}");
JavaRDD<String> datasRDD = sc.parallelize(datas);
JavaRDD<User> mapRDD = datasRDD.map(
new Function<String, User>() {
public User call(String v) throws Exception {
Gson gson = new Gson();
return gson.fromJson(v, User.class);
}
});
mapRDD.foreach(new VoidFunction<User>() {
public void call(User user) throws Exception {
System.out.println("id: " + user.id
+ " name: " + user.name
+ " pwd: " + user.pwd
+ " sex:" + user.sex);
}
});
sc.close();
}
// 结果
id: 1 name: xl1 pwd: xl123 sex:2
id: 2 name: xl2 pwd: xl123 sex:1
id: 3 name: xl3 pwd: xl123 sex:22.1.3 Scala示例
private def map() {
val conf = new SparkConf().setAppName(ScalaOperatorDemo.getClass.getSimpleName).setMaster("local")
val sc = new SparkContext(conf)
val datas: Array[String] = Array(
"{'id':1,'name':'xl1','pwd':'xl123','sex':2}",
"{
'id':2,'name':'xl2','pwd':'xl123','sex':1}",
"{
'id':3,'name':'xl3','pwd':'xl123','sex':2}")
sc.parallelize(datas)
.map(v => {
new Gson().fromJson(v, classOf[User])
})
.foreach(user => {
println("id: " + user.id
+ " name: " + user.name
+ " pwd: " + user.pwd
+ " sex:" + user.sex)
})
}2.2 filter
2.2.1 概述
语法(scala):
def filter(f: T => Boolean): RDD[T]说明:
对元素进行过滤,对每个元素应用f函数,返回值为true的元素在RDD中保留,返回为false的将过滤掉
2.2.2 Java示例
static void filter() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> datas = Arrays.asList(1, 2, 3, 7, 4, 5, 8);
JavaRDD<Integer> rddData = sc.parallelize(datas);
JavaRDD<Integer> filterRDD = rddData.filter(
// jdk1.8
// v1 -> v1 >= 3
new Function<Integer, Boolean>() {
public Boolean call(Integer v) throws Exception {
return v >= 3;
}
}
);
filterRDD.foreach(
// jdk1.8
// v -> System.out.println(v)
new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
System.out.println(integer);
}
}
);
sc.close();
}
// 结果
3
7
4
5
82.2.3 Scala示例
def filter {
val conf = new SparkConf().setAppName(ScalaOperatorDemo.getClass.getSimpleName).setMaster("local")
val sc = new SparkContext(conf)
val datas = Array(1, 2, 3, 7, 4, 5, 8)
sc.parallelize(datas)
.filter(v => v >= 3)
.foreach(println)
}2.3 flatMap
2.3.1 简述
语法(scala):
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]说明:
与map类似,但每个输入的RDD成员可以产生0或多个输出成员
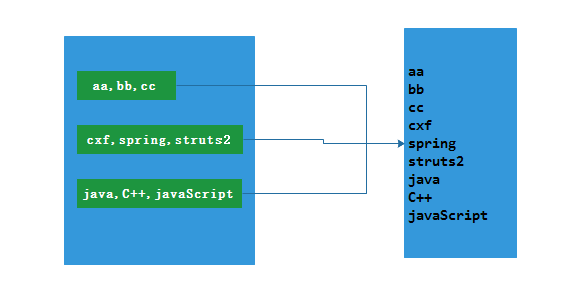
2.3.2 Java示例
static void flatMap() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> data = Arrays.asList(
"aa,bb,cc",
"cxf,spring,struts2",
"java,C++,javaScript");
JavaRDD<String> rddData = sc.parallelize(data);
JavaRDD<String> flatMapData = rddData.flatMap(
v -> Arrays.asList(v.split(",")).iterator()
// new FlatMapFunction<String, String>() {
// @Override
// public Iterator<String> call(String t) throws Exception {
// List<String> list= Arrays.asList(t.split(","));
// return list.iterator();
// }
// }
);
flatMapData.foreach(v -> System.out.println(v));
sc.close();
}
// 结果
aa
bb
cc
cxf
spring
struts2
java
C++
javaScript2.3.3 Scala示例
sc.parallelize(datas)
.flatMap(line => line.split(","))
.foreach(println)2.4 mapPartitions
2.4.1 概述
语法(scala):
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]说明:
与Map类似,但map中的func作用的是RDD中的每个元素,而mapPartitions中的func作用的对象是RDD的一整个分区。所以func的类型是
Iterator<T> => Iterator<U>,其中T是输入RDD元素的类型。preservesPartitioning表示是否保留输入函数的partitioner,默认false。
2.4.2 Java示例
static void mapPartitions() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> names = Arrays.asList("张三1", "李四1", "王五1", "张三2", "李四2",
"王五2", "张三3", "李四3", "王五3", "张三4");
JavaRDD<String> namesRDD = sc.parallelize(names, 3);
JavaRDD<String> mapPartitionsRDD = namesRDD.mapPartitions(
new FlatMapFunction<Iterator<String>, String>() {
int count = 0;
@Override
public Iterator<String> call(Iterator<String> stringIterator) throws Exception {
List<String> list = new ArrayList<String>();
while (stringIterator.hasNext()) {
list.add("分区索引:" + count++ + "\t" + stringIterator.next());
}
return list.iterator();
}
}
);
// 从集群获取数据到本地内存中
List<String> result = mapPartitionsRDD.collect();
result.forEach(System.out::println);
sc.close();
}
// 结果
分区索引:0 张三1
分区索引:1 李四1
分区索引:2 王五1
分区索引:0 张三2
分区索引:1 李四2
分区索引:2 王五2
分区索引:0 张三3
分区索引:1 李四3
分区索引:2 王五3
分区索引:3 张三42.4.3 Scala示例
sc.parallelize(datas, 3)
.mapPartitions(
n => {
val result = ArrayBuffer[String]()
while (n.hasNext) {
result.append(n.next())
}
result.iterator
}
)
.foreach(println)2.5 mapPartitionsWithIndex
2.5.1 概述
语法(scala):
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]说明:
与mapPartitions类似,但输入会多提供一个整数表示分区的编号,所以func的类型是
(Int, Iterator<T>) => Iterator<R>,多了一个Int
2.5.2 Java示例
private static void mapPartitionsWithIndex() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> names = Arrays.asList("张三1", "李四1", "王五1",  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









