









spark开发环境搭建
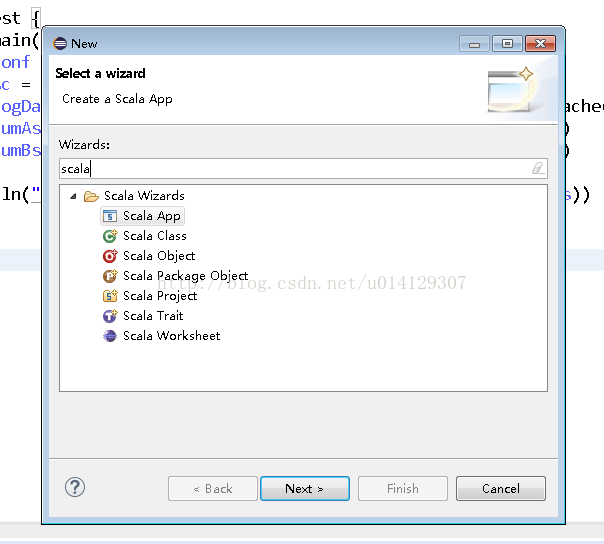
1.下载开发工具luna eclipse 或者 Intellij IDEA(官网下载的 scala for eclipse如果不能用可以使用 luna)
2.安装jdk1.7配置环境变量
3.安装scala的语言包,下载scala-2.10.4.msi 配置SCALA HOME。下载spark1.6,并且配置spark环境变量
4.在eclipse中安装scala插件
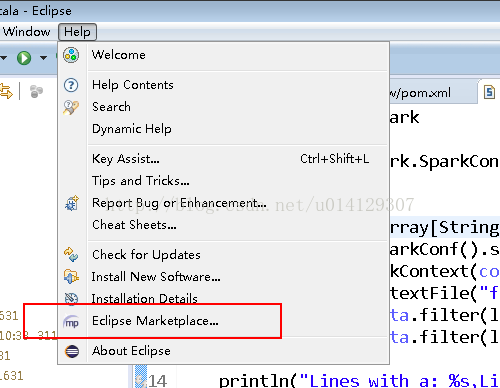
图1
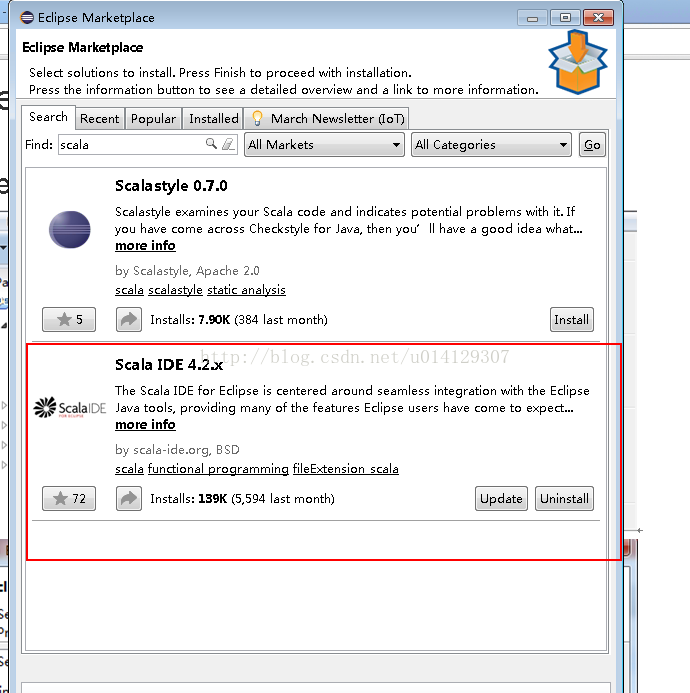
图2
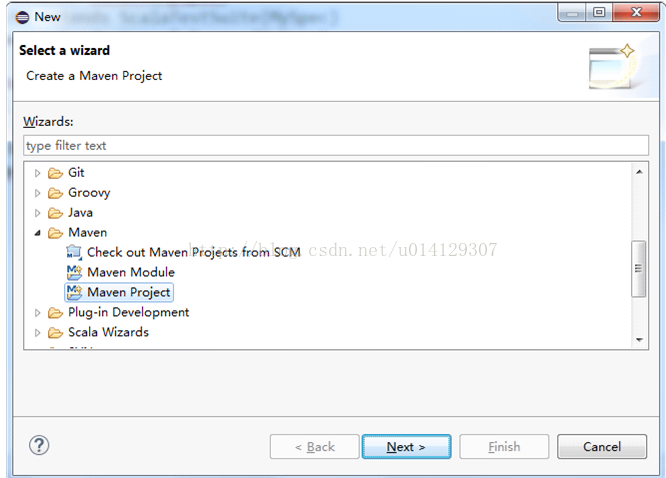
5.安装maven,并且配置maven环境变量
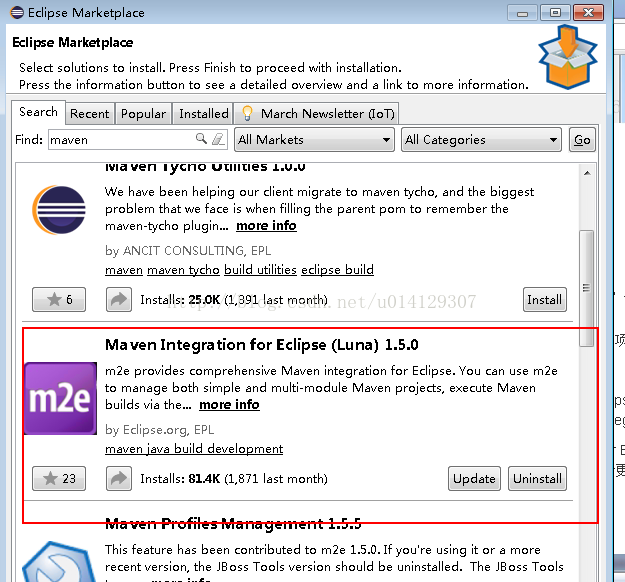
图3
安装m2e-scala::http://alchim31.free.fr/m2e-scala/update-site/
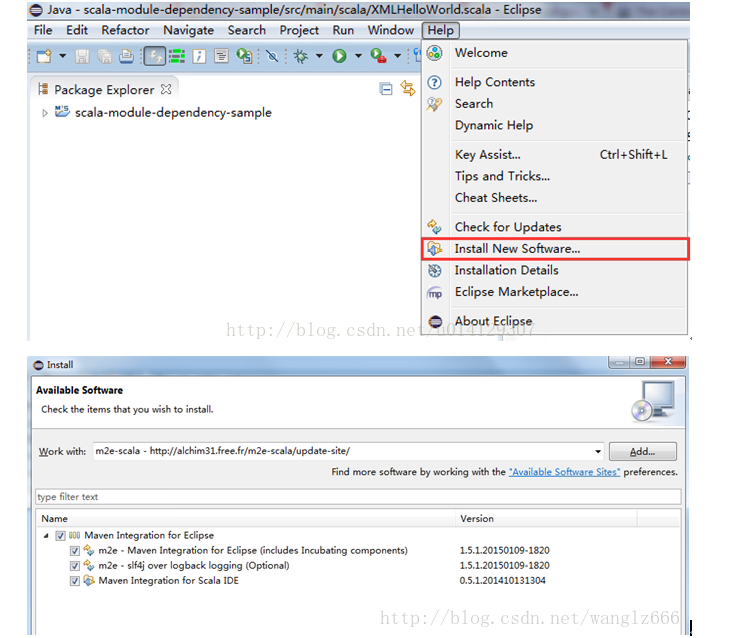
从图4中搜索到的插件名称中可以看到,这里同时也配置了m2e,也即eclipse需要的maven插件。如果eclipse没有maven插件,则可以全部选中安装;若已经有了可以单独安装第三个Maven Integration for Scala IDE。
安装完成了MavenIntegration for Scala IDE之后,再输入上面的url,可安装列表里就没有Maven Integration for Scala IDE这一项了
在eclipse中右键->new 能看到下面的表示sclaa 插件安装成功.
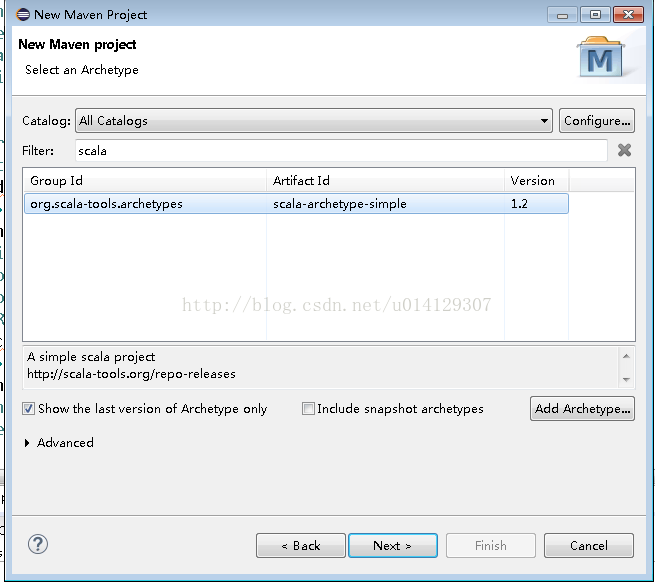
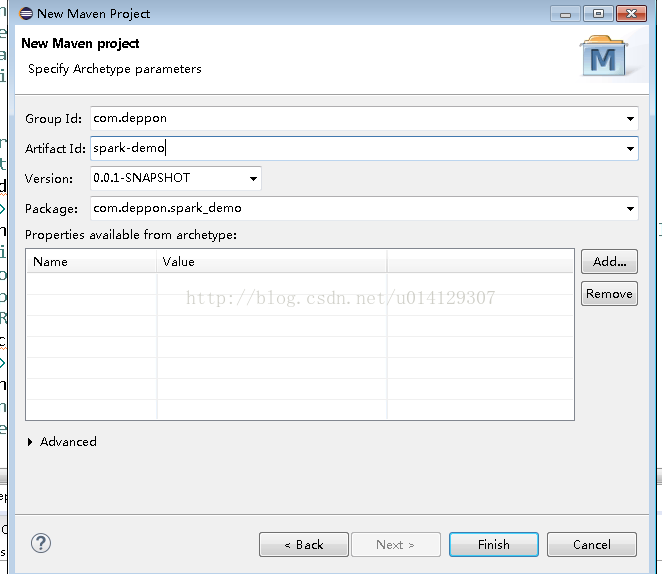
使用maven+scala搭建spark项目:
1.右键-new
2.右键项目名称-configure-Add scala Nature 将maven项目改成scala项目
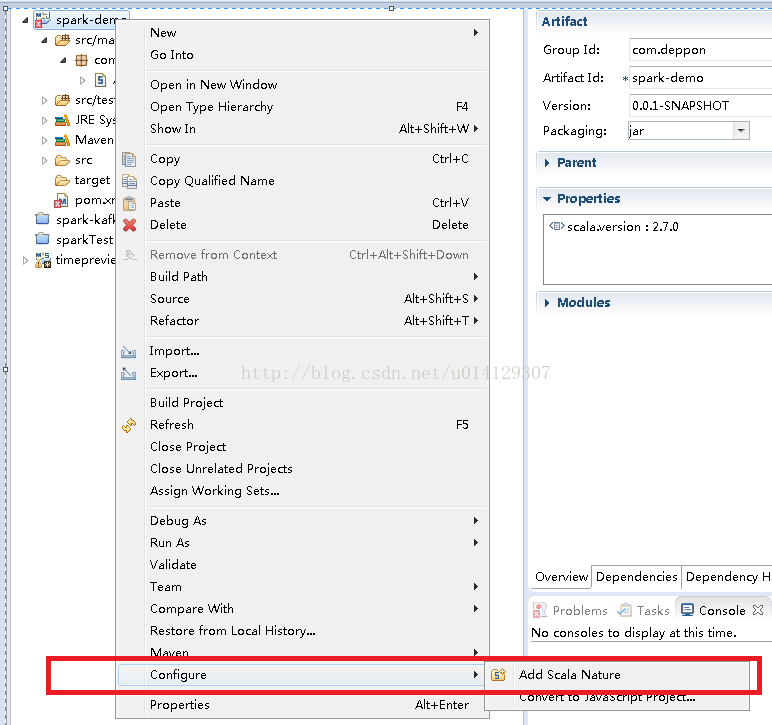
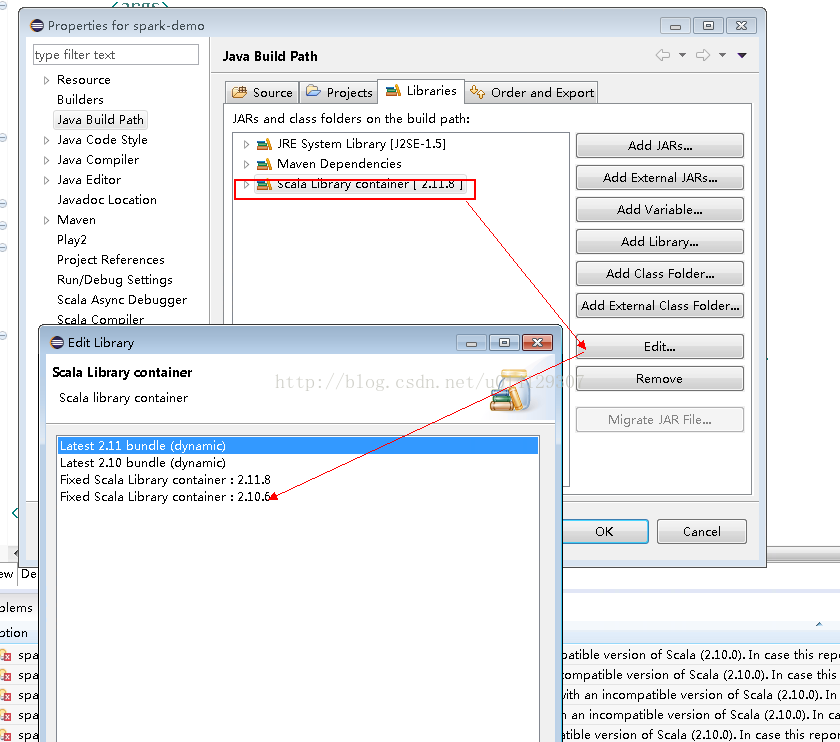
3.新建项目的默认的scala语言包默认使用的scala2.11,前面安装的是scala2.10.所以pom文件中会报错。
解决办法:右键项目-build path-configure build path,将scala语言包改成2.10
class
KafkaManager(val kafkaParams: Map[String, String])
extends
Serializable {
@transient
lazy val log = LogManager.getLogger(
this
.getClass)
private
val kc =
new
KafkaCluster(kafkaParams)
/**
* 创建数据流
* @param ssc
* @param kafkaParams
* @param topics
* @tparam K
* @tparam V
* @tparam KD
* @tparam VD
* @return
*/
def createDirectStream[K: ClassTag, V: ClassTag, KD <: Decoder[K]: ClassTag, VD <: Decoder[V]: ClassTag](
ssc: StreamingContext, kafkaParams: Map[String, String], topics: Set[String]): InputDStream[(K, V)] = {
val groupId = kafkaParams.get(
"group.id"
).get
// 在zookeeper上读取offsets前先根据实际情况更新offsets
setOrUpdateOffsets(topics, groupId)
//从zookeeper上读取offset开始消费message
val messages = {
val partitionsE = kc.getPartitions(topics)
if
(partitionsE.isLeft)
throw
new
SparkException(
"get kafka partition failed:"
)
val partitions = partitionsE.right.get
val consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)
if
(consumerOffsetsE.isLeft)
throw
new
SparkException(
"get kafka consumer offsets failed:"
)
val consumerOffsets = consumerOffsetsE.right.get
KafkaUtils.createDirectStream[K, V, KD, VD, (K, V)](
ssc, kafkaParams, consumerOffsets, (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message))
}
messages
}
/**
* 创建数据流前,根据实际消费情况更新消费offsets
* @param topics
* @param groupId
*/
private
def setOrUpdateOffsets(topics: Set[String], groupId: String): Unit = {
topics.foreach(topic => {
var hasConsumed =
true
val partitionsE = kc.getPartitions(Set(topic))
if
(partitionsE.isLeft)
throw
new
SparkException(s
"get kafka partition failed: ${partitionsE.left.get.mkString("
\n
")}"
)
val partitions: Set[TopicAndPartition] = partitionsE.right.get
val consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)
if
(consumerOffsetsE.isLeft) hasConsumed =
false
log.info(
"consumerOffsetsE.isLeft: "
+ consumerOffsetsE.isLeft)
if
(hasConsumed) {
// 消费过
log.warn(
"消费过"
)
/**
* 如果zk上保存的offsets已经过时了,即kafka的定时清理策略已经将包含该offsets的文件删除。
* 针对这种情况,只要判断一下zk上的consumerOffsets和earliestLeaderOffsets的大小,
* 如果consumerOffsets比earliestLeaderOffsets还小的话,说明consumerOffsets已过时,
* 这时把consumerOffsets更新为earliestLeaderOffsets
*/
val earliestLeaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)
if
(earliestLeaderOffsetsE.isLeft)
throw
new
SparkException(s
"get earliest offsets failed: ${earliestLeaderOffsetsE.left.get.mkString("
\n
")}"
)
val earliestLeaderOffsets = earliestLeaderOffsetsE.right.get
val consumerOffsets = consumerOffsetsE.right.get
// 可能只是存在部分分区consumerOffsets过时,所以只更新过时分区的consumerOffsets为earliestLeaderOffsets
var offsets: Map[TopicAndPartition, Long] = Map()
consumerOffsets.foreach({
case
(tp, n) =>
val earliestLeaderOffset = earliestLeaderOffsets(tp).offset
if
(n < earliestLeaderOffset) {
log.warn(
"consumer group:"
+ groupId +
",topic:"
+ tp.topic +
",partition:"
+ tp.partition +
" offsets已经过时,更新为"
+ earliestLeaderOffset)
offsets += (tp -> earliestLeaderOffset)
}
})
log.warn(
"offsets: "
+ consumerOffsets)
if
(!offsets.isEmpty) {
kc.setConsumerOffsets(groupId, offsets)
}
}
else
{
// 没有消费过
log.warn(
"没消费过"
)
val reset = kafkaParams.get(
"auto.offset.reset"
).map(_.toLowerCase)
var leaderOffsets: Map[TopicAndPartition, LeaderOffset] =
null
if
(reset == Some(
"smallest"
)) {
leaderOffsets = kc.getEarliestLeaderOffsets(partitions).right.get
}
else
{
leaderOffsets = kc.getLatestLeaderOffsets(partitions).right.get
}
val offsets = leaderOffsets.map {
case
(tp, offset) => (tp, offset.offset)
}
log.warn(
"offsets: "
+ offsets)
kc.setConsumerOffsets(groupId, offsets)
}
})
}
/**
* 更新zookeeper上的消费offsets
* @param rdd
*/
def updateZKOffsets(rdd: RDD[(String, String)]): Unit = {
val groupId = kafkaParams.get(
"group.id"
).get
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for
(offsets <- offsetsList) {
val topicAndPartition = TopicAndPartition(offsets.topic, offsets.partition)
val o = kc.setConsumerOffsets(groupId, Map((topicAndPartition, offsets.untilOffset)))
if
(o.isLeft) {
log.error(s
"Error updating the offset to Kafka cluster: ${o.left.get}"
)
}
}
}
}
@DeveloperApi
class
KafkaCluster(val kafkaParams: Map[String, String])
extends
Serializable {
import
KafkaCluster.{ Err, LeaderOffset, SimpleConsumerConfig }
@transient
private
var _config: SimpleConsumerConfig =
null
def config: SimpleConsumerConfig =
this
.
synchronized
{
if
(_config ==
null
) {
_config = SimpleConsumerConfig(kafkaParams)
}
_config
}
def connect(host: String, port: Int): SimpleConsumer =
new
SimpleConsumer(host, port, config.socketTimeoutMs,
config.socketReceiveBufferBytes, config.clientId)
def connectLeader(topic: String, partition: Int): Either[Err, SimpleConsumer] =
findLeader(topic, partition).right.map(hp => connect(hp._1, hp._2))
def findLeader(topic: String, partition: Int): Either[Err, (String, Int)] = {
val req = TopicMetadataRequest(TopicMetadataRequest.CurrentVersion,
0
, config.clientId, Seq(topic))
val errs =
new
Err
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp: TopicMetadataResponse = consumer.send(req)
resp.topicsMetadata.find(_.topic == topic).flatMap { tm: TopicMetadata =>
tm.partitionsMetadata.find(_.partitionId == partition)
}.foreach { pm: PartitionMetadata =>
pm.leader.foreach { leader =>
return
Right((leader.host, leader.port))
}
}
}
Left(errs)
}
def findLeaders(
topicAndPartitions: Set[TopicAndPartition]): Either[Err, Map[TopicAndPartition, (String, Int)]] = {
val topics = topicAndPartitions.map(_.topic)
val response = getPartitionMetadata(topics).right
val answer = response.flatMap { tms: Set[TopicMetadata] =>
val leaderMap = tms.flatMap { tm: TopicMetadata =>
tm.partitionsMetadata.flatMap { pm: PartitionMetadata =>
val tp = TopicAndPartition(tm.topic, pm.partitionId)
if
(topicAndPartitions(tp)) {
pm.leader.map { l =>
tp -> (l.host -> l.port)
}
}
else
{
None
}
}
}.toMap
if
(leaderMap.keys.size == topicAndPartitions.size) {
Right(leaderMap)
}
else
{
val missing = topicAndPartitions.diff(leaderMap.keySet)
val err =
new
Err
err +=
new
SparkException(s
"Couldn't find leaders for ${missing}"
)
Left(err)
}
}
answer
}
def getPartitions(topics: Set[String]): Either[Err, Set[TopicAndPartition]] = {
getPartitionMetadata(topics).right.map { r =>
r.flatMap { tm: TopicMetadata =>
tm.partitionsMetadata.map { pm: PartitionMetadata =>
TopicAndPartition(tm.topic, pm.partitionId)
}
}
}
}
def getPartitionMetadata(topics: Set[String]): Either[Err, Set[TopicMetadata]] = {
val req = TopicMetadataRequest(
TopicMetadataRequest.CurrentVersion,
0
, config.clientId, topics.toSeq)
val errs =
new
Err
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp: TopicMetadataResponse = consumer.send(req)
val respErrs = resp.topicsMetadata.filter(m => m.errorCode != ErrorMapping.NoError)
if
(respErrs.isEmpty) {
return
Right(resp.topicsMetadata.toSet)
}
else
{
respErrs.foreach { m =>
val cause = ErrorMapping.exceptionFor(m.errorCode)
val msg = s
"Error getting partition metadata for '${m.topic}'. Does the topic exist?"
errs +=
new
SparkException(msg, cause)
}
}
}
Left(errs)
}
def getLatestLeaderOffsets(
topicAndPartitions: Set[TopicAndPartition]): Either[Err, Map[TopicAndPartition, LeaderOffset]] =
getLeaderOffsets(topicAndPartitions, OffsetRequest.LatestTime)
def getEarliestLeaderOffsets(
topicAndPartitions: Set[TopicAndPartition]): Either[Err, Map[TopicAndPartition, LeaderOffset]] =
getLeaderOffsets(topicAndPartitions, OffsetRequest.EarliestTime)
def getLeaderOffsets(
topicAndPartitions: Set[TopicAndPartition],
before: Long): Either[Err, Map[TopicAndPartition, LeaderOffset]] = {
getLeaderOffsets(topicAndPartitions, before,
1
).right.map { r =>
r.map { kv =>
// mapValues isn't serializable, see SI-7005
kv._1 -> kv._2.head
}
}
}
private
def flip[K, V](m: Map[K, V]): Map[V, Seq[K]] =
m.groupBy(_._2).map { kv =>
kv._1 -> kv._2.keys.toSeq
}
def getLeaderOffsets(
topicAndPartitions: Set[TopicAndPartition],
before: Long,
maxNumOffsets: Int): Either[Err, Map[TopicAndPartition, Seq[LeaderOffset]]] = {
findLeaders(topicAndPartitions).right.flatMap { tpToLeader =>
val leaderToTp: Map[(String, Int), Seq[TopicAndPartition]] = flip(tpToLeader)
val leaders = leaderToTp.keys
var result = Map[TopicAndPartition, Seq[LeaderOffset]]()
val errs =
new
Err
withBrokers(leaders, errs) { consumer =>
val partitionsToGetOffsets: Seq[TopicAndPartition] =
leaderToTp((consumer.host, consumer.port))
val reqMap = partitionsToGetOffsets.map { tp: TopicAndPartition =>
tp -> PartitionOffsetRequestInfo(before, maxNumOffsets)
}.toMap
val req = OffsetRequest(reqMap)
val resp = consumer.getOffsetsBefore(req)
val respMap = resp.partitionErrorAndOffsets
partitionsToGetOffsets.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { por: PartitionOffsetsResponse =>
if
(por.error == ErrorMapping.NoError) {
if
(por.offsets.nonEmpty) {
result += tp -> por.offsets.map { off =>
LeaderOffset(consumer.host, consumer.port, off)
}
}
else
{
errs +=
new
SparkException(
s
"Empty offsets for ${tp}, is ${before} before log beginning?"
)
}
}
else
{
errs += ErrorMapping.exceptionFor(por.error)
}
}
}
if
(result.keys.size == topicAndPartitions.size) {
return
Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs +=
new
SparkException(s
"Couldn't find leader offsets for ${missing}"
)
Left(errs)
}
}
private
def defaultConsumerApiVersion: Short =
0
/** Requires Kafka >= 0.8.1.1. Defaults to the original ZooKeeper backed api version. */
def getConsumerOffsets(
groupId: String,
topicAndPartitions: Set[TopicAndPartition]): Either[Err, Map[TopicAndPartition, Long]] =
getConsumerOffsets(groupId, topicAndPartitions, defaultConsumerApiVersion)
def getConsumerOffsets(
groupId: String,
topicAndPartitions: Set[TopicAndPartition],
consumerApiVersion: Short): Either[Err, Map[TopicAndPartition, Long]] = {
getConsumerOffsetMetadata(groupId, topicAndPartitions, consumerApiVersion).right.map { r =>
r.map { kv =>
kv._1 -> kv._2.offset
}
}
}
def getConsumerOffsetMetadata(
groupId: String,
topicAndPartitions: Set[TopicAndPartition]): Either[Err, Map[TopicAndPartition, OffsetMetadataAndError]] =
getConsumerOffsetMetadata(groupId, topicAndPartitions, defaultConsumerApiVersion)
def getConsumerOffsetMetadata(
groupId: String,
topicAndPartitions: Set[TopicAndPartition],
consumerApiVersion: Short): Either[Err, Map[TopicAndPartition, OffsetMetadataAndError]] = {
var result = Map[TopicAndPartition, OffsetMetadataAndError]()
val req = OffsetFetchRequest(groupId, topicAndPartitions.toSeq, consumerApiVersion)
val errs =
new
Err
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp = consumer.fetchOffsets(req)
val respMap = resp.requestInfo
val needed = topicAndPartitions.diff(result.keySet)
needed.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { ome: OffsetMetadataAndError =>
if
(ome.error == ErrorMapping.NoError) {
result += tp -> ome
}
else
{
errs += ErrorMapping.exceptionFor(ome.error)
}
}
}
if
(result.keys.size == topicAndPartitions.size) {
return
Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs +=
new
SparkException(s
"Couldn't find consumer offsets for ${missing}"
)
Left(errs)
}
/** Requires Kafka >= 0.8.1.1. Defaults to the original ZooKeeper backed api version. */
def setConsumerOffsets(
groupId: String,
offsets: Map[TopicAndPartition, Long]): Either[Err, Map[TopicAndPartition, Short]] =
setConsumerOffsets(groupId, offsets, defaultConsumerApiVersion)
def setConsumerOffsets(
groupId: String,
offsets: Map[TopicAndPartition, Long],
consumerApiVersion: Short): Either[Err, Map[TopicAndPartition, Short]] = {
val meta = offsets.map { kv =>
kv._1 -> OffsetAndMetadata(kv._2)
}
setConsumerOffsetMetadata(groupId, meta, consumerApiVersion)
}
def setConsumerOffsetMetadata(
groupId: String,
metadata: Map[TopicAndPartition, OffsetAndMetadata]): Either[Err, Map[TopicAndPartition, Short]] =
setConsumerOffsetMetadata(groupId, metadata, defaultConsumerApiVersion)
def setConsumerOffsetMetadata(
groupId: String,
metadata: Map[TopicAndPartition, OffsetAndMetadata],
consumerApiVersion: Short): Either[Err, Map[TopicAndPartition, Short]] = {
var result = Map[TopicAndPartition, Short]()
val req = OffsetCommitRequest(groupId, metadata, consumerApiVersion)
val errs =
new
Err
val topicAndPartitions = metadata.keySet
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp = consumer.commitOffsets(req)
val respMap = resp.commitStatus
val needed = topicAndPartitions.diff(result.keySet)
needed.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { err: Short =>
if
(err == ErrorMapping.NoError) {
result += tp -> err
}
else
{
errs += ErrorMapping.exceptionFor(err)
}
}
}
if
(result.keys.size == topicAndPartitions.size) {
return
Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs +=
new
SparkException(s
"Couldn't set offsets for ${missing}"
)
Left(errs)
}
private
def withBrokers(brokers: Iterable[(String, Int)], errs: Err)(fn: SimpleConsumer => Any): Unit = {
brokers.foreach { hp =>
var consumer: SimpleConsumer =
null
try
{
consumer = connect(hp._1, hp._2)
fn(consumer)
}
catch
{
case
NonFatal(e) =>
errs += e
}
finally
{
if
(consumer !=
null
) {
consumer.close()
}
}
}
}
}
@DeveloperApi
object KafkaCluster {
type Err = ArrayBuffer[Throwable]
def checkErrors[T](result: Either[Err, T]): T = {
result.fold(
errs =>
throw
new
SparkException(errs.mkString(
"\n"
)),
ok => ok)
}
case
class
LeaderOffset(host: String, port: Int, offset: Long)
class
SimpleConsumerConfig
private
(brokers: String, originalProps: Properties)
extends
ConsumerConfig(originalProps) {
val seedBrokers: Array[(String, Int)] = brokers.split(
","
).map { hp =>
val hpa = hp.split(
":"
)
if
(hpa.size ==
1
) {
throw
new
SparkException(s
"Broker not in the correct format of <host>:<port> [$brokers]"
)
}
(hpa(
0
), hpa(
1
).toInt)
}
}
object SimpleConsumerConfig {
def apply(kafkaParams: Map[String, String]): SimpleConsumerConfig = {
val brokers = kafkaParams.get(
"metadata.broker.list"
)
.orElse(kafkaParams.get(
"bootstrap.servers"
))
.getOrElse(
throw
new
SparkException(
"Must specify metadata.broker.list or bootstrap.servers"
))
val props =
new
Properties()
kafkaParams.foreach {
case
(key, value) =>
if
(key !=
"metadata.broker.list"
&& key !=
"bootstrap.servers"
) {
props.put(key, value)
}
}
Seq(
"zookeeper.connect"
,
"group.id"
).foreach { s =>
if
(!props.containsKey(s)) {
props.setProperty(s,
""
)
}
}
new
SimpleConsumerConfig(brokers, props)
}
}
}
object ConsumerMain
extends
Serializable {
@transient
lazy val log = LogManager.getRootLogger
val hBaseConf = HBaseConfiguration.create()
hBaseConf.set(
"hbase.zookeeper.quorum"
,
"192.168.10.228,192.168.10.229,192.168.10.230,192.168.10.231,192.168.10.232"
)
hBaseConf.set(
"hbase.zookeeper.property.clientPort"
,
"2181"
);
// zookeeper端口号
hBaseConf.set(
"hbase.master"
,
"192.168.10.228:60000"
);
def functionToCreateContext(): StreamingContext = {
var startTime:Long=System.currentTimeMillis();
//SparkConf包含了Spark集群配置的各种参数
val sparkConf =
new
SparkConf().setMaster(
"local[4]"
).setAppName(
"Streming"
).set(
"spark.executor.memory"
,
"2g"
).set(
"spark.driver.maxResultSize"
,
"2g"
)
//.set("spark.streaming.kafka.maxRatePerPartition", "10")
.set(
"spark.sql.codegen"
,
"true"
)
val mapper =
new
ObjectMapper()
mapper.registerModule(DefaultScalaModule)
val ssc =
new
StreamingContext(sparkConf, Seconds(
120
))
val wayBillTable =
new
HTable(hBaseConf, TableName.valueOf(
"T_OPT_WAYBILL_STOCK"
))
val serBillTable =
new
HTable(hBaseConf, TableName.valueOf(
"T_SRV_WAYBILL"
))
val serBillTableWAYBILLNO =
new
HTable(hBaseConf, TableName.valueOf(
"T_SRV_WAYBILL_TEST"
))
//35468 //43744
wayBillTable.setAutoFlush(
false
,
false
)
//关闭自动提交
wayBillTable.setWriteBufferSize(
5
*
1024
*
1024
)
//设置缓存为5M
serBillTable.setAutoFlush(
false
,
false
)
//关闭自动提交
serBillTable.setWriteBufferSize(
5
*
1024
*
1024
)
//设置缓存为5M
serBillTableWAYBILLNO.setAutoFlush(
false
,
false
)
//关闭自动提交
serBillTableWAYBILLNO.setWriteBufferSize(
5
*
1024
*
1024
)
//设置缓存为5M
// Create direct kafka stream with brokers and topics
val topicsSet =
"kafkatopic5"
.split(
","
).toSet
//T_SRV_WAYBILL1,,T_OPT_WAYBILL_STOCK
val kafkaParams = scala.collection.immutable.Map[String, String](
"metadata.broker.list"
->
"192.168.10.228:9092,192.168.10.229:9092,192.168.10.230:9092,192.168.10.231:9092,192.168.10.232:9092"
,
"zookeeper.connect"
->
"192.168.10.228:2181,192.168.10.229:2181,192.168.10.230:2181,192.168.10.231:2181,192.168.10.232:2181"
,
"auto.offset.reset"
->
"smallest"
,
"group.id"
->
"group1"
)
val km =
new
KafkaManager(kafkaParams)
/* createDstream 使用了receivers来接收数据,利用的是Kafka高层次的消费者api,
对于所有的receivers接收到的数据将会保存在Spark executors中,
然后通过Spark Streaming启动job来处理这些数据,默认会丢失*/
/*createDirectStream 这种方式定期地从kafka的topic+partition中查询最新的偏移量*/
val kafkaDirectStream = km.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
//更新zk中的offset
kafkaDirectStream.foreachRDD(rdd => {
println(
"=========================="
+rdd.count()+
"=============================="
)
for
(line <- rdd.collect.toArray){
//{table:'aa',XXXX}{table:'aa',XXXX}
//分割数据 }|{
var message1 =line._2.replace(
"}{\"table"
,
"}|{\"table"
);
var message2 = message1.split(
"\\|"
)
for
(m<- message2){
println(
"m======================= "
+m)
//if("{".equals(m.substring(0,1))&& "}".equals(m.substring(m.length()-1))){
if
(m.contains(
"{\"table\""
) &&
"}"
.equals(m.substring(m.length()-
1
))){
println(m)
val obj = mapper.readValue(m, classOf[MessageEntity])
//修改
if
(
"U"
.equals(obj.op_type)){
//库存表
if
(
"TFR.T_OPT_WAYBILL_STOCK"
.equals(obj.table)){
var json =
new
JsonUtil().map2Json(obj.after.asInstanceOf[mutable.Map[String,Object]])
var way= mapper.readValue(json, classOf[WayBillStock])
println(
"库存表:"
+way.WAYBILL_NO+
"===============>"
+way.ORG_CODE)
// update(obj.after,"cf",way.ID)
wayBillTable.put(insert(obj.after,
"cf"
,way.ID))
}
}
//新增
if
(
"I"
.equals(obj.op_type)){
//库存表
if
(
"SCOTT.T_OPT_WAYBILL_STOCK"
.equals(obj.table)){
var json =
new
JsonUtil().map2Json(obj.after.asInstanceOf[mutable.Map[String,Object]])
var way= mapper.readValue(json, classOf[WayBillStock])
println(
"库存表:"
+way.WAYBILL_NO+
"===============>"
+way.ORG_CODE)
wayBillTable.put(insert(obj.after,
"cf"
,way.ID))
}
//运单表
if
(
"PKP.T_SRV_WAYBILL1"
.equals(obj.table)){
var json =
new
JsonUtil().map2Json(obj.after.asInstanceOf[mutable.Map[String,Object]])
var ser= mapper.readValue(json, classOf[SerWayBill])
println(
"运单表:"
+ser.WAYBILL_NO+
"===============>"
+ser.ACCOUNT_NAME)
// serBillTable.put(insert(obj.after,"cf",ser.ID))
serBillTableWAYBILLNO.put(insert(obj.after,
"cf"
,ser.WAYBILL_NO))
}
}
//删除TFR.T_OPT_WAYBILL_STOCK
if
(
"D"
.equals(obj.op_type)){
if
(
"TFR.T_OPT_WAYBILL_STOCK"
.equals(obj.table)){
var json =
new
JsonUtil().map2Json(obj.before.asInstanceOf[mutable.Map[String,Object]])
var way= mapper.readValue(json, classOf[WayBillStock])
println(
"库存表:"
+way.WAYBILL_NO+
"===============>"
+way.ORG_CODE)
delete(
"TFR.T_OPT_WAYBILL_STOCK"
,way.ID)
}
}
}
}
}
if
(!rdd.isEmpty){
km.updateZKOffsets(rdd)
}
})
wayBillTable.flushCommits()
serBillTable.flushCommits()
serBillTableWAYBILLNO.flushCommits()
ssc
}
/**
* 插入
*/
def insert(map:mutable.Map[String,Object],familyName:String,rowkey:String):Put={
var rowKey=UUID.randomUUID().toString().getBytes
val p =
new
Put(rowKey)
var valueArray:Array[Object] =
new
Array[Object](map.values.size)
var keyArray:Array[String] =
new
Array[String](map.keys.size)
map.values.copyToArray(valueArray)
map.keys.copyToArray(keyArray)
var strs:Array[String] =
new
Array[String](map.values.size)
for
( i <-
1
to (valueArray.length -
1
) ) {
strs(i)=String.valueOf(valueArray(i))
}
for
( i <-
1
to (keyArray.length -
1
) ) {
p.addColumn(familyName.getBytes, keyArray(i).getBytes,
if
(strs(i)!=
null
&& !
""
.equals(strs(i))) strs(i).toString().getBytes
else
""
.getBytes)
}
return
p
}
/**
* 根据rowkey删除一条数据
*/
def delete(tableName:String,rowkey:String):Unit ={
val table =
new
HTable(hBaseConf,
"T_OPT_WAYBILL_STOCK"
)
val delete =
new
Delete(Bytes.toBytes(rowkey))
table.delete(delete)
println(
"delete record done."
)
table.close()
// hBaseCon.close()
}
def main(args: Array[String]): Unit = {
val ssc = functionToCreateContext()
ssc.start()
ssc.awaitTermination()
sys.addShutdownHook({ssc.stop(
true
,
true
)})
}
}
object SparkSqlUtil {
val sparkConf =
new
SparkConf().setMaster(
"local[4]"
).setAppName(
"User"
)
sparkConf.set(
"spark.sql.codegen"
,
"true"
);
var dataFomat:SimpleDateFormat =
new
SimpleDateFormat(
"yyyy-MM-dd HH:mm"
)
// 创建 spark context
val sc =
new
SparkContext(sparkConf)
val sqlContext =
new
SQLContext(sc)
import
sqlContext.implicits._
// 创建HBase configuration
val hBaseConf = HBaseConfiguration.create()
hBaseConf.set(
"hbase.zookeeper.quorum"
,
"192.168.10.228,192.168.10.229,192.168.10.230,192.168.10.231,192.168.10.232"
)
hBaseConf.set(
"hbase.zookeeper.property.clientPort"
,
"2181"
);
// zookeeper端口号
hBaseConf.set(
"hbase.master"
,
"192.168.10.228:60000"
);
val myTable =
new
HTable(hBaseConf, TableName.valueOf(
"T_BAS_EXECPTION_INFO"
))
myTable.setAutoFlush(
false
,
false
)
//关闭自动提交
myTable.setWriteBufferSize(
5
*
1024
*
1024
)
//设置缓存为5M
def schedule(){
var startTime:Long=System.currentTimeMillis();
println(
"===========================================程序开始============================================"
)
// 应用newAPIHadoopRDD读取HBase,返回NewHadoopRDD
hBaseConf.set(TableInputFormat.INPUT_TABLE,
"T_SRV_WAYBILL"
)
val hbaseRDD1 = sc.newAPIHadoopRDD(hBaseConf,classOf[TableInputFormat],classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],classOf[org.apache.hadoop.hbase.client.Result])
hBaseConf.set(TableInputFormat.INPUT_TABLE,
"T_OPT_WAYBILL_STOCK"
)
val hbaseRDD2 = sc.newAPIHadoopRDD(hBaseConf,classOf[TableInputFormat],classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],classOf[org.apache.hadoop.hbase.client.Result])
hBaseConf.set(TableInputFormat.INPUT_TABLE,
"T_BAS_LINE"
)
val hbaseRDD3 = sc.newAPIHadoopRDD(hBaseConf,classOf[TableInputFormat],classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],classOf[org.apache.hadoop.hbase.client.Result])
hBaseConf.set(TableInputFormat.INPUT_TABLE,
"T_BAS_DEPARTURE_STD"
)
val hbaseRDD4 =sc.newAPIHadoopRDD(hBaseConf,classOf[TableInputFormat],classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],classOf[org.apache.hadoop.hbase.client.Result])
// 将数据映射为表 也就是将 RDD转化为 dataframe schema
// 读取结果集RDD,返回一个MapPartitionsRDD
val resRDD1 = hbaseRDD1.map(tuple => tuple._2)
val resRDD2 = hbaseRDD2.map(tuple => tuple._2)
val resRDD3 = hbaseRDD3.map(tuple => tuple._2)
val resRDD4 = hbaseRDD4.map(tuple => tuple._2)
// HBaseSpark.queryVirtual("W3000020619", ", sc, sqlContext, hBaseConf)
//运单表 dataframe
resRDD1.map(r => (
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"ID"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"WAYBILL_NO"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"DELIVERY_CUSTOMER_NAME"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"GOODS_NAME"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"BILL_TIME"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"RECEIVE_ORG_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"ACTIVE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"TIME"
)))
)).toDF(
"ID"
,
"WAYBILL_NO"
,
"DELIVERY_CUSTOMER_NAME"
,
"GOODS_NAME"
,
"BILL_TIME"
,
"RECEIVE_ORG_CODE"
,
"ACTIVE"
,
"TIME"
).registerTempTable(
"T_SRV_WAYBILL"
)
//库存表
resRDD2.map(r => (
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"WAYBILL_NO"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"ORG_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"NEXT_ORG_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"BILL_TIME"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
), Bytes.toBytes(
"f.ORIG_ORG_CODE"
)))
)).toDF(
"WAYBILL_NO"
,
"ORG_CODE"
,
"NEXT_ORG_CODE"
,
"BILL_TIME"
,
"f.ORIG_ORG_CODE"
).registerTempTable(
"T_OPT_WAYBILL_STOCK"
)
//线路
resRDD3.map(r=>(
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"VIRTUAL_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"ORIG_ORG_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"DEST_ORG_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"ACTIVE"
)))
)).toDF(
"VIRTUAL_CODE"
,
"ORIG_ORG_CODE"
,
"DEST_ORG_CODE"
,
"ACTIVE"
).registerTempTable(
"T_BAS_LINE"
)
//发车标准
resRDD4.map(r=>(
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"LEAVE_TIME"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"ARRIVE_TIME"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"LINE_VIRTUAL_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"FREQUENCY_NO"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"VIRTUAL_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"DEST_ORG_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"ORIG_ORG_CODE"
))),
Bytes.toString(r.getValue(Bytes.toBytes(
"cf"
),Bytes.toBytes(
"ACTIVE"
)))
)).toDF(
"LEAVE_TIME"
,
"ARRIVE_TIME"
,
"LINE_VIRTUAL_CODE"
,
"FREQUENCY_NO"
,
"VIRTUAL_CODE"
,
"DEST_ORG_CODE"
,
"ORIG_ORG_CODE"
,
"ACTIVE"
).registerTempTable(
"T_BAS_DEPARTURE_STD"
)
var date=
"'"
+dataFomat.format(
new
Date())+
"'"
var data=sqlContext.sql(
"select g.WAYBILL_NO,g.BILL_TIME,g.DELIVERY_CUSTOMER_NAME,g.GOODS_NAME from( "
+
"select ws.WAYBILL_NO, concat(concat(substr(ws.BILL_TIME,0,10),' '),concat(concat(substr(ld.LEAVE_TIME,0,2),':')),substr(ld.LEAVE_TIME,3)) BILL_TIME,ws.DELIVERY_CUSTOMER_NAME,ws.GOODS_NAME "
+
" from "
+
"( "
+
" select w.WAYBILL_NO,s.ORG_CODE,s.NEXT_ORG_CODE,w.BILL_TIME,w.DELIVERY_CUSTOMER_NAME,w.GOODS_NAME "
+
" from (select s.WAYBILL_NO,s.ORG_CODE,s.NEXT_ORG_CODE "
+
" from T_OPT_WAYBILL_STOCK s "
+
" where s.NEXT_ORG_CODE is not null group by s.WAYBILL_NO,s.ORG_CODE,s.NEXT_ORG_CODE "
+
" ) s "
+
" join T_SRV_WAYBILL w on s.ORG_CODE=w.RECEIVE_ORG_CODE and s.WAYBILL_NO=w.WAYBILL_NO "
+
" where w.ACTIVE='Y' "
+
" ) ws "
+
" join "
+
" ( "
+
" select l.ORIG_ORG_CODE,l.DEST_ORG_CODE,d.LEAVE_TIME "
+
" from T_BAS_LINE l "
+
" join (select d.LINE_VIRTUAL_CODE, max(d.LEAVE_TIME) LEAVE_TIME "
+
" from T_BAS_DEPARTURE_STD d "
+
" where d.ACTIVE='Y' and d.LEAVE_TIME <> d.ARRIVE_TIME "
+
" group by d.LINE_VIRTUAL_CODE) d "
+
" on l.VIRTUAL_CODE = d.LINE_VIRTUAL_CODE "
+
" where l.ACTIVE='Y' "
+
" ) ld "
+
" on ws.ORG_CODE=ld.ORIG_ORG_CODE and ws.NEXT_ORG_CODE=ld.DEST_ORG_CODE"
+
// where ld.LEAVE_TIME<"+date+
") g where g.BILL_TIME<"
+date
//+date
)
data.foreach { x =>
println(x.get(
0
).toString()+
"============>"
+x.get(
1
).toString())
var rowKey=UUID.randomUUID().toString().getBytes
val p =
new
Put(rowKey)
p.addColumn(
"cf"
.getBytes,
"ID"
.getBytes,rowKey)
p.addColumn(
"cf"
.getBytes,
"WAYBILL_NO"
.getBytes, x.get(
0
).toString().getBytes)
p.addColumn(
"cf"
.getBytes,
"DELIVERY_CUSTOMER_NAME"
.getBytes,
if
(x.get(
2
)!=
null
) x.get(
2
).toString().getBytes
else
""
.getBytes)
p.addColumn(
"cf"
.getBytes,
"GOODS_NAME"
.getBytes,
if
(x.get(
3
)!=
null
) x.get(
3
).toString().getBytes
else
""
.getBytes)
myTable.put(p)
}
myTable.flushCommits()
//计算完成将数据提交
var endTime:Long=System.currentTimeMillis();
println(
"================================================共耗时:"
+(endTime-startTime)+
"========================================="
)
sc.stop()
}
def main(args: Array[String]): Unit = {
var timeInterval:Long =
1000
*
60
var r=
new
Runnable{
def run() {
while
(
true
) {
schedule
Thread.sleep(timeInterval);
}
}
}
var thread=
new
Thread(r);
thread.start();
}
}
<modelVersion>4.0.0</modelVersion>
<groupId>com.deppon.spark</groupId>
<artifactId>timepreview</artifactId>
<version>0.0.1-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.10.6</scala.version>
</properties>
<repositories>
<repository>
<id>cdh</id>
<name>cdh Releases</name>
<url>https://repository.cloudera.com/content/repositories/releases/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
<!-- <dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.4</version>
</dependency> -->
<dependency>
<groupId>net.minidev</groupId>
<artifactId>json-smart</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.7.0</version>
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.7.0</version>
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- spark sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.7</arg>
</args>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4.1</version>
<configuration>
<archive>
<manifest>
<mainClass>com.deppon.spark.Test</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
部署:
1.了解spark作业提交流程:
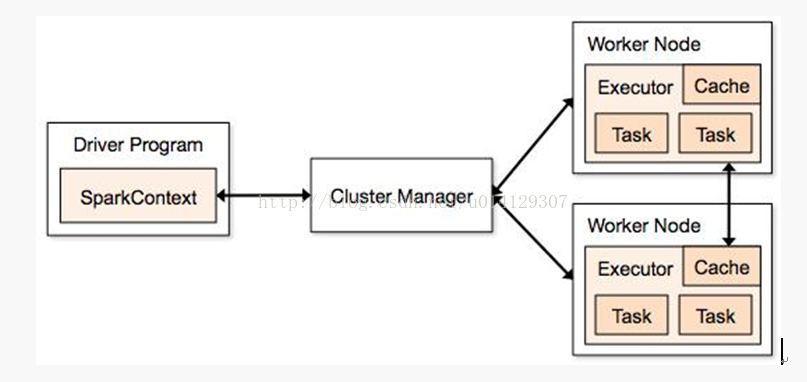
Spark Application的运行架构由两部分组成:driver program(SparkContext)和executor
Spark YARN模式:Hadoop YARN资源管理模式;
Standalone模式: 简单模式或称独立模式,可以单独部署到一个集群中,无依赖任何其他资源管理系统。不使用其他调度工具时会存在单点故障,使用Zookeeper等可以解决;
Local模式:本地模式,可以启动本地一个线程来运行job,可以启动N个线程或者使用系统所有核运行job;
2.将前面搭建spark-demo工程打成jar包上传至集群服务器上
3.使用spark yarn-client 将作业提交到集群中运行
yarn-cluster:dirver运行在AM中,它只是向yarn申请资源,并且监督作用提交完成,就关闭client
yarn-client:AM只是向yarn申请executor,client和请求的容器通信来调度工作,所有client不能离开。
[manager@hadoop1bin]$ spark-submit --executor-memory 2g --driver-memory 3g --total-executor-cores288--executor-cores2 --master yarn --classcom.deppon.spark.SparkMan /opt/zc/app/spark-demo.jar














 4130
4130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









