







 本文详细介绍了8-Queens Problem的局部极值启发式搜索方法,讨论了状态空间、不同约束条件下的解空间规模,并重点阐述了估值函数和搜索策略,包括模拟退火算法如何跳出局部最优,寻找全局最优解。文章还提供了简单统计结果,展示了算法的效率。
本文详细介绍了8-Queens Problem的局部极值启发式搜索方法,讨论了状态空间、不同约束条件下的解空间规模,并重点阐述了估值函数和搜索策略,包括模拟退火算法如何跳出局部最优,寻找全局最优解。文章还提供了简单统计结果,展示了算法的效率。
「8-Queens Problem」皇后问题局部极值启发式搜索方法
Backgrounds
背景说明:
皇后问题是算法领域的著名问题,问题的背景是在8*8的国际象棋棋盘上摆满8个皇后使之互相不能攻击(由于皇后在国际象棋规则中横、纵、斜三个方向均可以移动,即摆放要使得皇后两两不在同一横、纵、斜线上)。放松这个问题的变长条件,我们可以将其扩大至N*N的棋盘上摆放N个皇后,使之各自在三个方向上不重复出现。
大一时刚刚学习编程语言的我们,在初次接到这道题时,主要是运用了递归函数和回溯的思想去解决问题,通过深度优先搜索(depth-first search, DFS)策略,依次增加棋盘上可以摆放的位置。若遇到第k步棋子摆放的所有可能位置都发生冲突,则退回到第k-1步,修改k-1的状态,以达到期望的最终解。
State space of 8-queens problem
皇后问题的状态空间:
状态空间,这里理解成所有摆放的可能性情况。
皇后问题广义的解的状态空间,在没有过多限制条件的情况下是非常庞大的。
在64个互不重复的位置上选择无差别的8个位置,总计应该有C(64, 8)=4,426,165,368 (44亿)大小的状态空间. 图示为较为集中的分布情况和可以完全分散开的分布情况。


图 1.1 皇后分布紧凑 图 1.2 皇后分布松散
注意⚠这里C(N*N, N)表示在N*N种方案中选择N个的方案数
不同约束条件下的不同状态空间规模:
实际上,全局解状态空间的大小也由我们的限制条件决定,下面提出两种解决方案。但总体上策略一致地是,我们用一个长度为8的一维数组表示每一列皇后的位置,这种表示方法首先就压缩掉了很大一部分的解的状态空间——因为相当于即使在横向上有皇后可能会重合,这种每列一个位置数的表示方式放弃了同一列上出现多个皇后的情况。图示为横纵均不重合分散分布和允许行重复的分布情况。


图 2.1 允许同行冲突 图 2.2 保证横纵均不冲突
但上述两种表示方法出于求解出尽可能多的局部极值和尽快求解出最优解的考虑,依然是稳妥的。此时状态空间的大小至多已经被压缩至8^8=16,777,216 (1670万)种,相比于44亿已经极大地压缩了解的数量。
(1).第一种表示方法,我们在允许行重合的情况下,每次操作只在该列上对棋子进行上下移动,并考虑每次移动对于总冲突数的影响。
此种排列的状态空间为8^8=16,777,216.
(2).第二种表示方法,我们对1~8的数字进行全排列,得到{a1, a2, …, ai, …, a8}用于表示第i 列上的皇后位置,这样可以保证行列均不重复。
此种排列的状态空间为8!=40,320.
局部极值和全局最值的理解:
全局最值,是对于每一个搜索问题需要找到的最终结果。对于不同的问题,其问题的离散/连续性可能不同,解的数量、状态分布也不相同。皇后问题本身是一个离散问题(解的状态空间数量是有限个数的,虽然解空间总规模可能非常大),且解的数量也是巨大的。至少对于8皇后,不存在唯一的状态。后续运行程序可知,在不考虑翻转、旋转等价的情况下,有92组互不相同的解。即在横纵均不重合的40,320规模的状态空间(或在更大范围的状态空间中)有92组全局最值。
局部极值,是我们通过某种途径趋向全局最值时经过的、不能再用当前算法得出相对更进一步的结果(而必须由重启、重新打乱而继续开始一次新的搜索)时,“卡住”的状态。
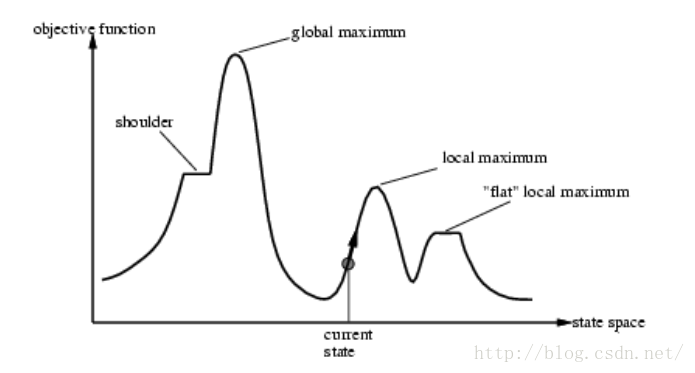
图 3 搜索路径与全局最优、局部最优的关系
(state space为构成搜索路径的n维解空间的子集,objective function为目标函数)
对于同一个问题,我们考虑f(x1, x2, …, xi, …, xn)=K的目标函数,希望通过启发式搜索的方式寻找全局K的最优值,即在n维解空间上,我们得到由目标函数f(.)决定的决策-目标曲面。在这个n+1维曲面S(X<x1, x2, …, xn>, K)上,不同的约束条件和算法就相当于通过不同的n维路径Ls<x1s, x2s, …, xns>去逼近全局最优K.
其中Ls是某种启发式搜索算法的搜索路径,对于特定的搜索算法,Ls是n维解状态空间的有向路径。记Ls上的每一步解为Xj, 并设该条路径从某一初始状态X0出发,经过p步可以到达全局或局部最优值(其中任意Xj都是n维状态空间上的点),则该路径Ls可以表示为Ls={ X0, X1, …, Xj, …, Xp}. 由于状态空间的不平整性,显然通过不同的算法定义到的局部最优解(局部极值)也是不同的。
注意⚠这里的定义包括后续目标函数的定义、估值函数的定义、最终的求解目的等等
Evaluation function
估值函数:
对于启发式搜索,我们需要在巨大的解的状态空间中尽可能快地找出尽可能多的全局最优解,这就需要我们在做每一步选择(选择继续扩大解的已知范围,使之尽快铺展至n维或跳转至下一个解的暂留状态)时,能有效评判该解对于“发现最优解”这一目的的贡献意义的函数。或者我们也可以这样理解:搜索算法在在搜索路径的每一个解Xj停留时,并不知道该解是否处于到达全局最优的必经路径上,因此搜算算法会根据一个估值函数,对“该步操作可以到达全局最优或局部最优”这一事件做出概率分析。当搜索路径Ls走到Xj-1这一步时,会对所有可能的后续状态集合{ Xj’|Xj’=Xj’1, Xj’2,…}进行估值,最后选出估值最大的一个Xj’作为Xj下一步。后续也据此方法继续走下去。
当最终走到某一步,估值函数对所有可能的后继都没有最优估值或正向估值时,就说明搜索路径已经到达极值。此时检查目标函数K即可判断当前解是否是全局最优。
需要说明的是,对于全局最优,我们也可以有不同的定义方法。在本问题中,我们选择用“冲突行、列或斜线上棋子数减一”表示冲突情况,即当某行、列或斜线上皇后棋子数目为0个或1个时,认为没有冲突;皇后棋子数目为2个及以上时,认为冲突数是皇后数目-1.
|
1
2
3
4
5
6
7
8
9
10
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2075
2075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









