






1. 概率密度建模的参数化( parametric)⽅法
前面介绍的概率分布都有具体的函数形式,并且由少量的参数控制,这些参数的值可以由数据集确定。这被称为概率密度建模的参数化( parametric)⽅法。这种⽅法的⼀个重要局限性是选择的概率密度函数可能对于⽣成数据来说是⼀个很差的模型,从⽽会导致相当差的预测表现。这一部分,考虑⼀些⾮参数化⽅法进⾏概率密度估计。
2. 直方图方法
直⽅图方法把数据空间划分成宽度为∆的箱⼦,然后对落在第i个箱⼦中的x的观测数量ni进⾏计数。同时把观测数量除以观测的总数N,再除以箱⼦的宽度∆,得到每个箱⼦的概率的值pi =ni/(N*∆)。这给出了概率密度p(x)的⼀个模型,这个概率密度在每个箱⼦的宽度内是常数。
note:直⽅图⽅法也很容易应⽤到数据顺序到达的情形.
3. 核方法
假设观测值x服从D维空间的某个未知的概率密度分布p(x)。我们考虑包含x的某个⼩区域R。x落入该区域的概率为:
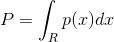
同时假设我们获得了服从p(x)分布的N次观测。由于每个数据点落在区域R中的概率P,因此位于区域R内部的数据点的总数K将服从⼆项分布:
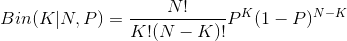
对于较⼤的N值:K ≃ NP(1)
同时假定区域R⾜够⼩,使得在这个区域内的概率密度p(x)⼤致为常数,那么我们有:P ≃ p(x)V (2), 联合(1)(2)得:p(x) = K/NV (3)
固定K然后从数据中确定V 的值,这就是K近邻⽅法。固定V 然后从数据中确定K,这就是核⽅法。
NOTE:它由⼀个很⼤的优点,即不需要进⾏“训练”阶段的计算,因为“训练”阶段只需要存储训练集即可。然⽽,这也是⼀个巨⼤的缺点,因为估计概率密度的计算代价随着数据集的规模线性增长。
4. K近邻方法
核⽅法进⾏概率密度估计的⼀个困难之处是控制核宽度的参数h。在⾼数据密度的区域,⼤的h值可能会造成过度平滑,⼩h可能导致数据空间中低密度区域估计的噪声。因此, h的最优选择可能依赖于数据空间的位置。这个问题可以通过概率密度的近邻⽅法解决。
NOTE:K近邻⽅法和核密度估计⽅法都需要存储整个训练数据。如果数据集很⼤的话,这会造成很⼤的计算代价。通过建⽴⼀个基于树的搜索结构,使得(近似)近邻可以⾼效地被找到,⽽不必遍历整个数据集。
5. 总结















 5937
5937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









