







zookeeper是一个开源的分布式解决方案,可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、master选举、分布式锁和分布式队列等功能。zookeeper能保证一下一致性:
顺序一致性:从同一个客户端发起的事务请求,最终会按照其发起顺序被应用到zookeeper中。
原子性:事务处理在zookeeper集群所有机器中是一致的。
单一视图:无论客户端连接的是哪个zookeeper服务器,其看到的服务器数据都是一致的。
可靠性:一定服务器成功地应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务器状态将被一直保持下来,处理又有另一个事务对其修改。
实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
数据模型
zookeeper将所有的数据存在内存中,数据模型是一棵树,由(/)分割路径 如 /foo/path1, 每个节点(ZNode)会保存自己的数据内容。
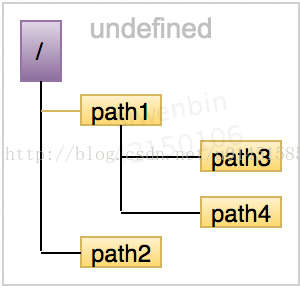
运行过程中zookeeper会定时向磁盘dump快照数据,同时在Zookeeper启动时,会通过磁盘的事务日志和快照文件恢复成一个完整的内存数据。
zookeeper集群
Zookeeper集群的角色主要有以下三类
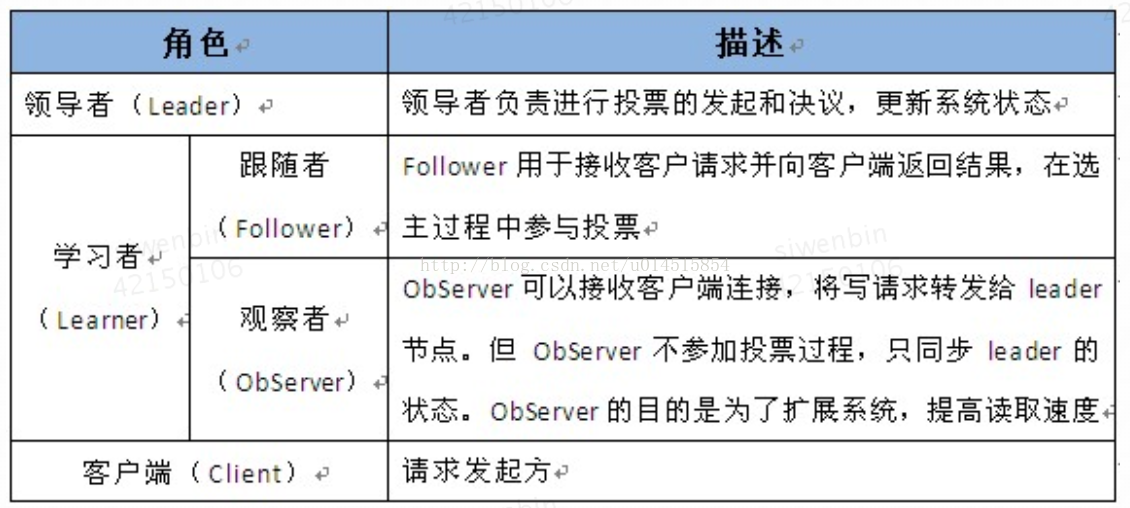
系统模型如图所示:
ZAB -- Zookeeper原子消息广播协议
Zookeeper使用了一种称为Zab(Zookeeper Atomic Broadcast)的协议作为其一致性复制的核心,具有高吞吐量、低延迟、健壮、简单的特点,但不过分要求其扩展性,是特别为zookeeper实际的崩溃可恢复的原子消息广播算法。具体的,zookeeper使用一个单一的主进程来接收并处理客户端的所有事物请求,并采用ZAB的原子广播协议,将服务器的状态变更以事物proposal的形式广播到所有的副本进程上去。
Zab协议有两种模式,它们分别是恢复模式和广播模式。
- 恢复模式 当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
- 广播模式 一旦Leader已经和多数的Follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个Server加入ZooKeeper服务中,它会在恢复模式下启动,发现Leader,并和Leader进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper服务一直维持在广播状态,直到Leader崩溃了或者Leader失去了大部分的Followers支持。
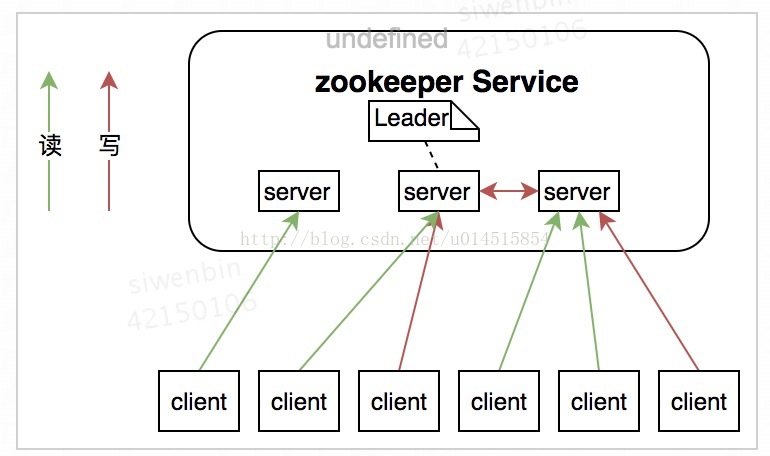
广播模式极其类似于分布式事务中的2pc(two-phrase commit 两阶段提交):即Leader提起一个决议,由Followers进行投票,Leader对投票结果进行计算决定是否通过该决议,如果通过执行该决议(事务),否则什么也不做。
两阶段提交示意图
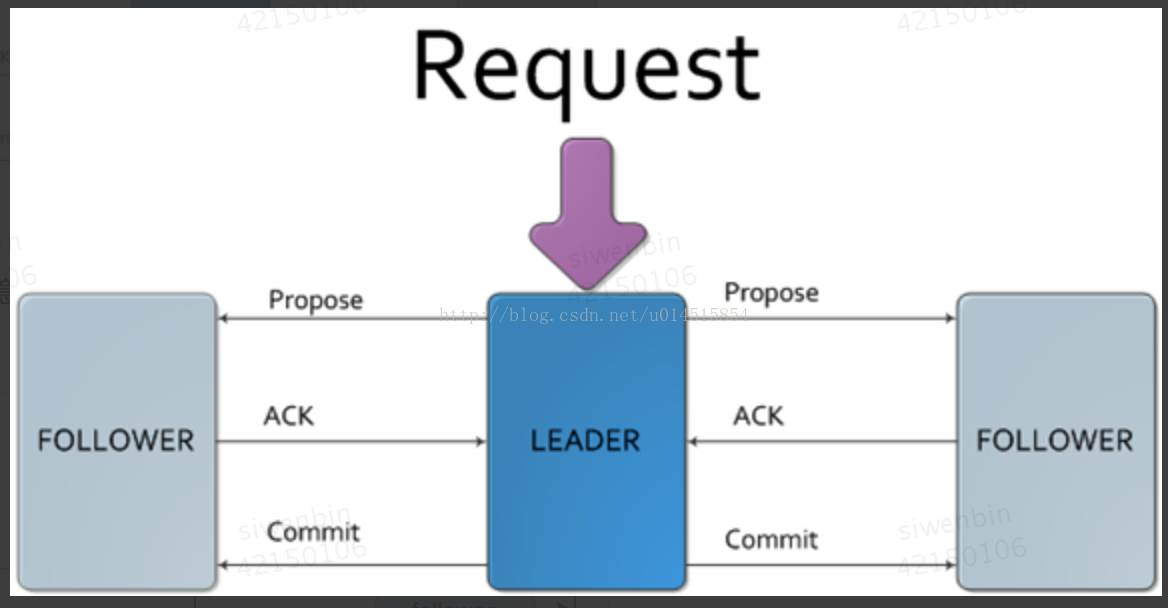
消息广播流程示意图
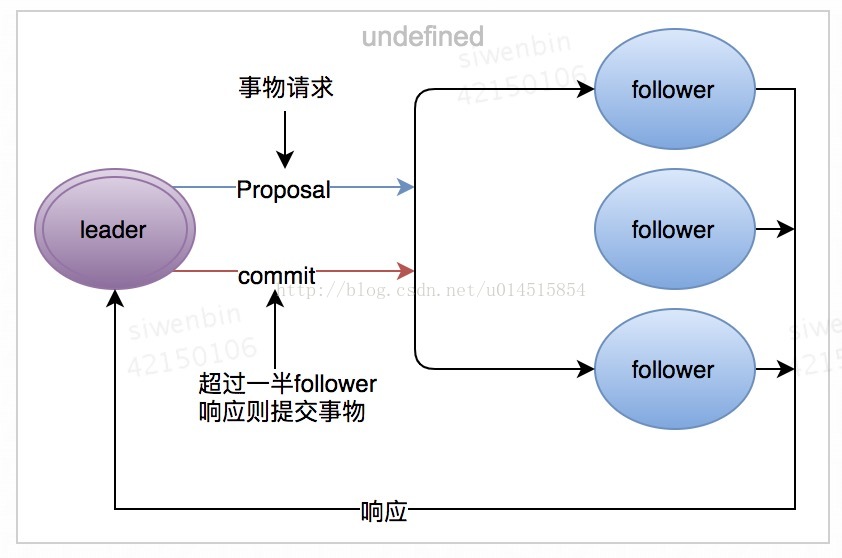
所有的事物请求必须由一个全局唯一的leader服务器来协调处理,将客户端的请求转化成一个事物Proposal(提议),并发给机器中所有的follower服务器,然后等待follower服务器反馈,一旦超过半数机器反馈正确后,那么leader服务器会再次向所有的follower服务器发送commit消息提交事物。
为了保证事务的顺序一致性,Zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。Zxid是由64位数字组成的,低32位用作简单计数器。高32位是一个epoch。每当新Leader接管它时,将获取日志中Zxid最大的epoch,新Leader Zxid的epoch位设置为epoch+1,counter位设置0。
在服务崩溃恢复时,Zab协议确定两条规则确保数据的一致性:
- 那些已经在leader服务器上提交的事物需要最终被所有服务器提交。
- 丢弃那些只在leader服务器上被提出的事物。
leader选举
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,选举完成后follower或从leader服务器同步数据,恢复到一个正确的状态提供服务。
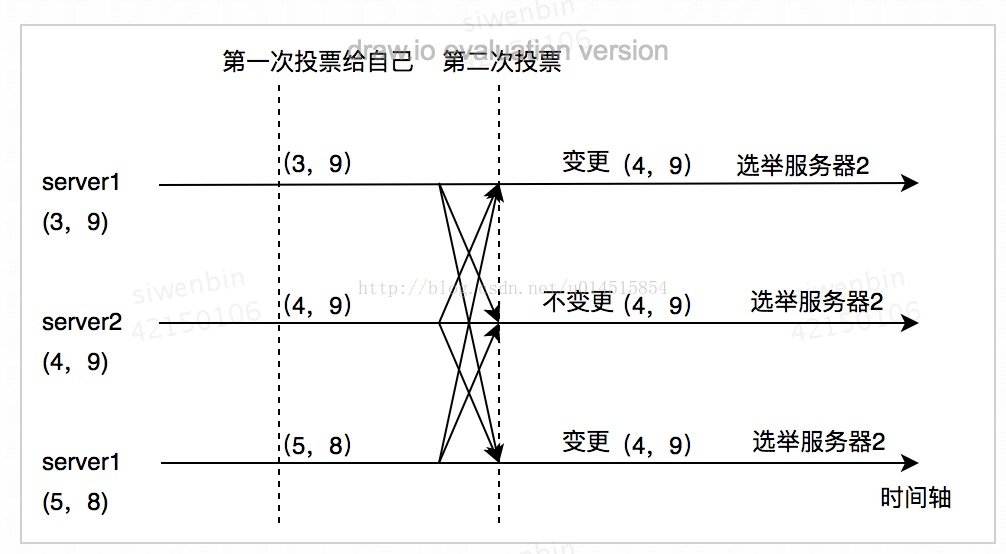
选举时每个server都会发出一票 , 形式为:(my_id,ZXID)——(服务器ID, 最大事物ID)。第一次投票,每个服务器都会投给自己,之后会根据所有服务器的选票情况投给ZXID最大的服务器,如果ZXID有相同再投最大my_id, 如果某个服务器得票超过半数服务器的数量,则该服务器当选为leader,选举结束。
以下图表示选举流程
zookeeper客户端
zookeeper客户端API包括增、删、改、查、监听(注册watcher)zookeeper目录,节点和数据。
watcher——数据变更的通知
zookeeper提供了分布式的数据发布、订阅功能,能够让多个订阅者同时收到订阅过的节点发生变化的通知,zookeeper使用watcher实现了这个功能。客户端向服务器注册一个watcher监听,当服务器的一些指定事件触发了这个watcher,那么客户端就会收到通知。 watcher注册只能收到一次变更通知,之后无效需要再次进行注册监听。
版本——保证分布式数据原子性操作
zookeeper中为数据节点引入了版本的概念,每个数据节点都具有三种类型的版本信息,对数据节点的任何更新操作(包括值没有变化的更新)都会引起版本号的变化。
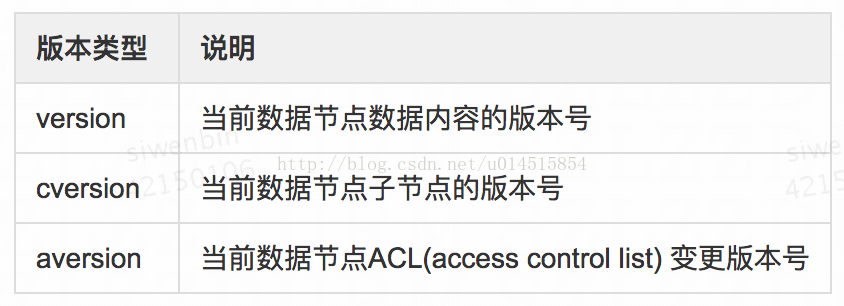
version属性是用来实现乐观锁机制中的“写入校验”,如果客户端不需要版本校验则version可传-1,操作时不进行version对比。
zookeeper开源客户端的使用
zookeeper开源客户端在原生的zookeeper API上进行了包装,使用zookeeper开源客户端进行一些基本操作,简化了开发,最常用的客户端是Curator,它解决了zookeeper客户端非常底层的细节开发工作,包括重连、反复注册watcher、和NodeExistsException异常等。
下面是基本操作方式
private CuratorFramework client;
@Before
public void init() {
client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2128")
.sessionTimeoutMs(16000)
.retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();
client.start();
}
/**
* 新增节点
* @throws Exception
*/
@Test
public void create() throws Exception {
client.create().forPath("/zookeeper/gsw", "hello!".getBytes());
}
/**
* 创建模式
1、PERSISTENT
持久化目录节点,存储的数据不会丢失。
2、PERSISTENT_SEQUENTIAL
顺序自动编号的持久化目录节点,存储的数据不会丢失,并且根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名。
3、EPHEMERAL
临时目录节点,一旦创建这个节点的客户端与服务器端口也就是session 超时,这种节点会被自动删除。
4、EPHEMERAL_SEQUENTIAL
临时自动编号节点,一旦创建这个节点的客户端与服务器端口也就是session 超时,这种节点会被自动删除,并且根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名。
* @throws Exception
*/
@Test
public void createMode() throws Exception {
client.create().withMode(CreateMode.EPHEMERAL).forPath("/zookeeper/gsw/ephemeral1");
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath("/zookeeper/gsw/ephemeral2");
System.out.println(client.getChildren().forPath("/zookeeper/gsw"));
}
/* ---- result ----
[ephemeral20000000015, ephemeral1]
*/
/**
* 获取数据
* @throws Exception
*/
@Test
public void getData() throws Exception {
System.out.println(new String(client.getData().forPath("/zookeeper/gsw")));
}
/* ---- result ----
hello
*/
/**
* 更新数据
* @throws Exception
*/
@Test
public void updateData() throws Exception {
client.setData().forPath("/zookeeper/gsw", "hello world!".getBytes());
}
/**
* 根据版本更新数据
* @throws Exception
*/
@Test
public void updateDataWithVersion() throws Exception {
Stat stat = new Stat();
client.getData().storingStatIn(stat).forPath("/zookeeper/gsw");
client.setData().withVersion(stat.getVersion()).forPath("/zookeeper/gsw", "hello world!".getBytes());
}
/**
* 异步更新
* @throws Exception
*/
@Test
public void updateDataBackGround() throws Exception {
Stat stat = new Stat();
client.getData().storingStatIn(stat).forPath("/zookeeper/gsw");
client.setData().withVersion(stat.getVersion()).inBackground(new BackgroundCallback() {
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
}
}).forPath("/zookeeper/gsw", "hello world!".getBytes());
}
/**
* 删除节点
* @throws Exception
*/
@Test
public void delete() throws Exception {
for (String path : client.getChildren().forPath("/zookeeper/gsw")) {
client.delete().forPath("/zookeeper/gsw/" + path);
System.out.println(client.getChildren().forPath("/zookeeper/gsw"));
}
}
/* ---- result ----
[]
*/zookeeper典型使用场景
事件监听
zookeeper原生支持注册watcher来进行事件监听,但是其使用起来不是很方便,需要开发人员反复注册watcher,比较繁琐,curator引入Cache来实现对zookeeper服务器的监听, Cache 监听分为两类:节点监听、子节点监听, NodeCache,PathChildrenCache。
代码清单
/**
* 事件监听
* @throws Exception
*/
@Test
public void nodeCache() throws Exception {
client.create().forPath("/home");
NodeCache nodeCache = new NodeCache(client, "/home");
nodeCache.start(true);
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("node has changed");
}
});
client.delete().deletingChildrenIfNeeded().forPath("/home");
client.create().creatingParentsIfNeeded().forPath("/home/hello");
PathChildrenCache pcc = new PathChildrenCache(client, "/home", false);
// 添加监听器
pcc.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("PathChildrenNode has changed event:" + event.getType());
}
});
pcc.start();
TimeUnit.SECONDS.sleep(1);
client.delete().forPath("/home/hello");
TimeUnit.SECONDS.sleep(1);
client.delete().forPath("/home");
}master选举
实现思路:选择一个根节点,例如 /master_select ,多台机器同时向该节点创建一个子节点/master_select/lock, 利用zookeeper的特性,最终只有一台机器能够创建成功,成功的机器成为master。
代码清单
@Test
public void selectMaster() throws InterruptedException {
new Thread(this::master1).start();
new Thread(this::master2).start();
new Thread(this::master3).start();
Thread.sleep(Integer.MAX_VALUE);
}
public void master1() {
try {
LeaderSelector selector = new LeaderSelector(client, "/zookeeper/gsw/master_path", new LeaderSelectorListenerAdapter() {
@Override
public void takeLeadership(CuratorFramework client) throws Exception {
System.out.println("1成为master角色");
TimeUnit.SECONDS.sleep(3);
System.out.println("1完成master 操作退出");
}
});
selector.autoRequeue();
selector.start();
Thread.sleep(Integer.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
}
}
public void master2() {
try {
LeaderSelector selector = new LeaderSelector(client, "/zookeeper/gsw/master_path", new LeaderSelectorListenerAdapter() {
@Override
public void takeLeadership(CuratorFramework client) throws Exception {
System.out.println("2成为master角色");
TimeUnit.SECONDS.sleep(3);
System.out.println("2完成master 操作退出");
}
});
selector.autoRequeue();
selector.start();
Thread.sleep(Integer.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
}
}
public void master3() {
try {
LeaderSelector selector = new LeaderSelector(client, "/zookeeper/gsw/master_path", new LeaderSelectorListenerAdapter() {
@Override
public void takeLeadership(CuratorFramework client) throws Exception {
System.out.println("3成为master角色");
TimeUnit.SECONDS.sleep(3);
System.out.println("3完成master 操作退出");
}
});
selector.autoRequeue();
selector.start();
Thread.sleep(Integer.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
}
}分布式锁
分布式环境中,为了保证数据一致性,经常需要分布式锁的功能,zookeeper锁的实现思路与master类似。
@Test
public void lock() throws Exception {
String lockPath = "/lock_path";
InterProcessLock lock = new InterProcessMutex(client, lockPath);
try {
lock.acquire();
TimeUnit.SECONDS.sleep(3);
} finally {
lock.release();
}
}分布式计数器
实现思路:指定一个zookeeper数据节点作为计数器,多个应用实例再分布式锁的控制下,通过更新该数据节点的内容来实现计数功能。
/**
* 分布式计数器
* @throws Exception
*/
@Test
public void distribute_int() throws Exception {
String dis_Path = "/distribute_atomic_int_page";
DistributedAtomicInteger distributedAtomicInteger = new DistributedAtomicInteger(client, dis_Path, new RetryNTimes(1000, 3));
AtomicValue<Integer> rc = distributedAtomicInteger.add(2);
System.out.print("result:" + rc.succeeded());
} 分布式Barrier
功能与JDK自带的CyclicBarrier一样,zookeeper实现分布式barrier实现原理与计数器类似。zookeeper的实现barrier有两种
DistributedBarrier--必须由其他线程释放barrier
DistributedDoubleBarrier -- 计数自己释放的barrier
/**
* 分布式barrier
* @throws Exception
*/
@Test
public void barrier() throws Exception {
String dis_Path = "/distribute_barrier_int_page";
DistributedBarrier distributedBarrier = new DistributedBarrier(client, dis_Path);
new Thread(() -> {
try {
distributedBarrier.setBarrier();
distributedBarrier.waitOnBarrier();
} catch (Exception e) {
e.printStackTrace();
}
});
// 主线程释放
distributedBarrier.removeBarrier();
for (int i=0; i<5; i++) {
dis_Path = "/double_distribute_barrier_int_page";
DistributedDoubleBarrier distributedDoubleBarrier = new DistributedDoubleBarrier(client, dis_Path, 5);
// 第一次阻塞
distributedDoubleBarrier.enter();
// 第二次阻塞
distributedDoubleBarrier.leave();
// 执行5次自己能够释放
}
} Kafka中zookeeper的应用
为了更好的理解,这里先介绍kafka中常用的术语
- 消息生产者:Producer
- 消息消费者:Consumer
- 主题:Topic,配置在服务器端,用于消费者和生产者之间的订阅关系,生产者发送消息到topic下,消费者消费该topic下的消息。
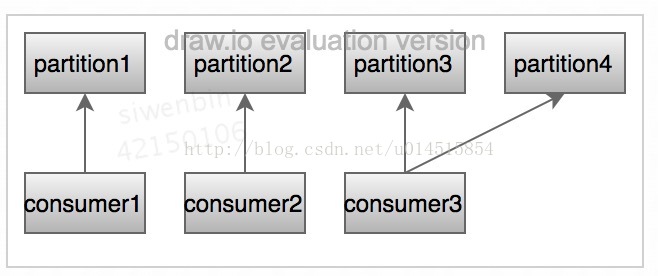
- 消息分区:Partition,一个topic下面会分为多个分区,一个分区只能有一个消费者消费。
- Broker:mafka服务器,用于存储消息。
- 消费者分组:Group
- Offset:读取消息所需的消息在文件中的偏移量。
消费者与partition的关系 一对多:
Broker注册
每个Broker服务器在启动时,都会到zookeeper上进行注册,在路径为:/broker/ids/[0...N] 下创建属于自己的节点,每个broker会将自己的IP地址和和端口等信息写入到该节点中去。这些节点都是临时节点,也就是说,一旦哪个broker服务器宕机或是下线了,那么对应的broker节点也就被删除了。如此我们可以通过broker节点的变化信息来动态表broker服务器的可用性。
Topic注册
在kafka中,会将同一个Topic的消息分成多个分区分布到多个broker上,这样的分区信息以及与broker的对应关系也都是由zookeeper维护的。broker服务器在启动后,回到对应的节点下注册自己的broker ID,并写入topic的分区总数。
如 /brokers/topics/topic_name/3 → 2 , 这个节点表明broker ID为3的服务器,对于"topic_name"这个topic的消息提供了2个分区消息储存。同样这个分区节点也是一个临时节点。
使用zookeeper进行负载均衡
使用zookeeper,kafka的生产者会对zookeeper上的“broker的新增和减少”、“topic的新增和减少” 和 “broker与topic的关联关系的变化”等事件注册watcher监听,这样就可以实现一直动态的负载均衡机制了。
消息分区与消费者之间的关系
zookeeper上记录了消费分区与消费者之间的关系,每个消费者一旦确定了对一个消息分区的消费的权利,那么需要将其Consumer ID写入到对应消息分区的临时节点上。
如: /consumers/[group_id]/owners/[topic]/[broker_id - partition_id], 其中 [broker_id - partition_id]是一个消息分区的标识,其节点数据就是Consumer ID。
消息消费进度offset记录
在消息者对指定消息分区进行消费的过程中,需要定时地将分区消息的消费进度offset记录到走哦keeper上去,以便在消费者重启或是其他消费者重新接管该消息分区后,能够从之前的进度开始读取消息。 offset在zookeeper上由专门的一个节点负责,其路径为:/consumers/[group_id]/offsets/[topic]/[broker_id - partition_id] , 其节点数据就是offset值。
消费者注册
消费者注册的临时节点:/consumers/[group_id]/ids/[consumer_id], 每个消费者都需要关注所属消费者分组中消费者服务器和broker服务器的变化情况,即对 /consumers/[group_id]/ids/ 与 /broker/ids/[0...N] 节点注册watcher进行监听,根据变化来决定是否需要进行消费者负载均衡。














 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









