







 HashMap是Java中常用的集合类,它通过哈希表实现快速查找。HashMap的工作原理包括内部桶数组和单链表解决哈希冲突。当存储的元素数量超过装载因子(默认0.75)设定的阈值时,HashMap会触发扩容,容量翻倍。扩容过程中,旧链表会被重新分配到新桶中,可能导致多线程环境下性能问题。为了优化性能,HashMap的容量必须是2的幂,利用与运算提高定位效率。
HashMap是Java中常用的集合类,它通过哈希表实现快速查找。HashMap的工作原理包括内部桶数组和单链表解决哈希冲突。当存储的元素数量超过装载因子(默认0.75)设定的阈值时,HashMap会触发扩容,容量翻倍。扩容过程中,旧链表会被重新分配到新桶中,可能导致多线程环境下性能问题。为了优化性能,HashMap的容量必须是2的幂,利用与运算提高定位效率。
1. HashMap工作原理
HashMap作为优秀的Java集合框架中的一个重要的成员,在很多编程场景下为我们所用。HashMap作为数据结构散列表的一种实现,就其工作原理来讲单独列出一篇博客来讲都是不过分的。由于本文主要是简单总结其扩容机制,因此对于HashMap的实现原理仅做简单的概述。
HashMap内部实现是一个桶数组,每个桶中存放着一个单链表的头结点。其中每个结点存储的是一个键值对整体(Entry),HashMap采用拉链法解决哈希冲突(关于哈希冲突后面会介绍)。
由于Java8对HashMap的某些地方进行了优化,以下的总结和源码分析都是基于Java7。
示意图如下:
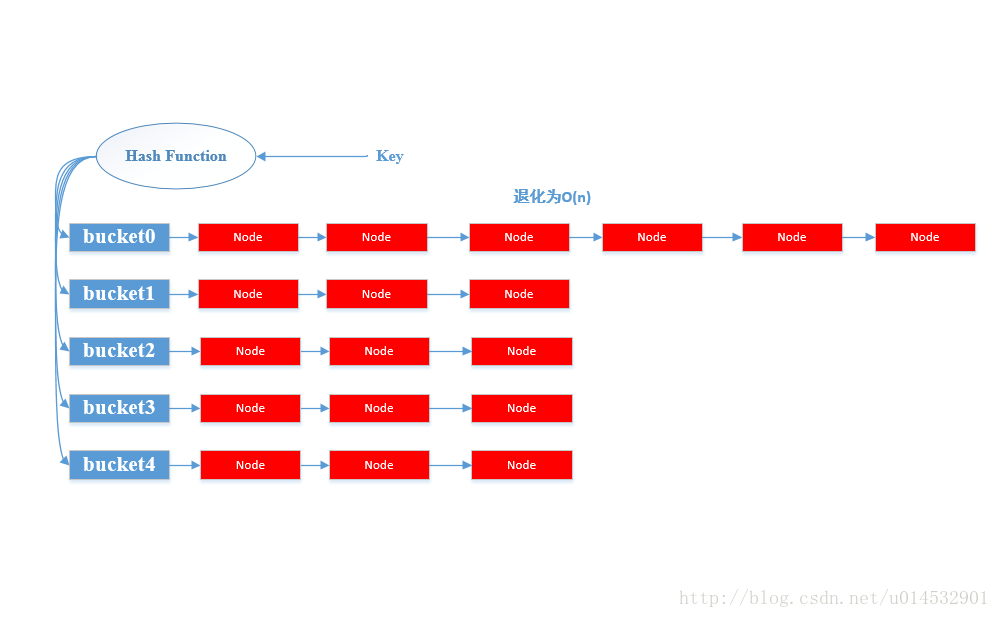
HashMap提供两个重要的基本操作,put(K, V)和get(K)。
- 当调用
put操作时,HashMap计算键值K的哈希值,然后将其对应到HashMap的某一个桶(bucket)上;此时找到以这个桶为头结点的一个单链表,然后顺序遍历该单链表找到某个节点的Entry中的Key是等于给定的参数K;若找到,则将其的old V替换为参数指定的V;否则直接在链表尾部插入一个新的Entry节点。 - 对于
get(K)操作类似于put操作,HashMap通过计算键的哈希值,先找到对应的桶,然后遍历桶存放的单链表通过比照Entry的键来找到对应的值。
以上就是HashMap的基本工作原理,但是问题总是比我们看到的要复杂。由于哈希是一种压缩映射,换句话说就是每一个Entry节点无法对应到一个只属于自己的桶,那么必然会存在多个Entry共用一个桶,拉成一条链表的情况,这种情况叫做哈希冲突。当哈希冲突产生严重的情况,某一个桶后面挂着的链表就会特别长,我们知道查找最怕看见的就是顺序查找,那几乎就是无脑查找。
哈希冲突无法完全避免,因此为了提高HashMap的性能,HashMap不得尽量缓解哈希冲突以缩短每个桶的外挂链表长度。
频繁产生哈希冲突最重要的原因就像是要存储的Entry太多,而桶不够,这和供不应求的矛盾类似。因此,当HashMap中的存储的Entry较多的时候,我们就要考虑增加桶的数量,这样对于后续要存储的Entry来讲,就会大大缓解哈希冲突。
因此就涉及到HashMap的扩容,上面算是回答了为什么扩容,那么什么时候扩容?扩容多少?怎么扩容?便是第二部分要总结的了。
2. HashMap扩容
2.1 HashMap的扩容时机
在使用HashMap的过程中,我们经常会遇到这样一个带参数的构造方法。
public HashMap(int initialCapacity, float loadFactor) ;- 第一个参数:初始容量,指明初始的桶的个数;相当于桶数组的大小。
- 第二个参数:装载因子,是一个0-1之间的系数,根据它来确定需要扩容的阈值,默认值是0.75。
现在开始通过源码来寻找扩容的时机:
put(K, V)操作
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);//计算键的hash值
int i = indexFor(hash, table.length);//通过hash值对应到桶位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//顺序遍历桶外挂的单链表
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//注意这里的键的比较方式== 或者 equals()
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);//遍历单链表完毕,没有找到与键相对的Entry,需要新建一个Entry换句话说就是桶i是一 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 854
854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









