







OPTICS算法
在DBSCAN算法中,我们知道该算法需要用户输入半径和阀值。这显然是不靠谱的,虽然我们可以通过其他方法来优化参数的选择,但这其实不是最好的做法。
这里为了克服在聚类分析中使用一组全局参数的缺点,这里提出了OPTICS算法。
该算法的牛逼之处在于:它并不显示地产生数据集聚类,而是为聚类分析生成一个增广的簇排序(如以样本点输出次序为横轴,以可达距离为纵轴的坐标图)。那么这个排序就厉害了,它代表了各样本点基于密度的聚类结构,它包含的信息等价于从一个广泛的参数设置所获得的基于密度的聚类。换句话说,从这个排序中可以得到基于任何半径和任何阀值的聚类。
回头看看上面那句话,我“使用”一个广泛的参数来克服你使用一组全局参数带来的缺点。OPTICS算法有点儿上帝视角的味道了。
OK,现在我们来看到底什么是OPTICS算法。
要搞清楚OPTICS算法,同DBSCAN算法一样,需要搞清楚这么几个概念的定义,即:半径、阀值,核心点,核心距离,可达距离,最小可达距离等。
搞清楚概念之后,其实就很简单了。
我认为,OPTICS的核心思想无外乎这两句话
1、较稠密簇中的对象在簇排序中相互靠近;
2、一个对象的最小可达距离给出了一个对象连接到一个稠密簇的最短路径。
这两句话,可能一时半会儿体会不到它的意义。
那我们先来看看具体咋做
算法:OPTICS
输入:样本集D, 邻域半径E, 给定点在E领域内成为核心对象的最小领域点数MinPts
输出:具有可达距离信息的样本点输出排序
方法:
1、创建两个队列,有序队列和结果队列。(有序队列用来存储核心对象及其该核心对象的直接可达对象,并按可达距离升序排列;结果队列用来存储样本点的输出次序。你可以把有序队列里面放的理解为待处理的数据,而结果队列里放的是已经处理完的数据);
2、如果所有样本集D中所有点都处理完毕,则算法结束。否则,选择一个未处理(即不在结果队列中)且为核心对象的样本点,找到其所有直接密度可达样本点,如过该样本点不存在于结果队列中,则将其放入有序队列中,并按可达距离排序;
3、如果有序队列为空,则跳至步骤2(重新选取处理数据)。否则,从有序队列中取出第一个样本点(即可达距离最小的样本点)进行拓展,并将取出的样本点保存至结果队列中(如果它不存在结果队列当中的话)。然后进行下面的处理。
3.1.判断该拓展点是否是核心对象,如果不是,回到步骤3(因为它不是核心对象,所以无法进行扩展了。那么就回到步骤3里面,取最小的。这里要注意,第二次取不是取第二小的,因为第一小的已经放到了结果队列中了,所以第二小的就变成第一小的了。)。如果该点是核心对象,则找到该拓展点所有的直接密度可达点;
3.2.判断该直接密度可达样本点是否已经存在结果队列,是则不处理,否则下一步;
3.3.如果有序队列中已经存在该直接密度可达点,如果此时新的可达距离小于旧的可达距离,则用新可达距离取代旧可达距离,有序队列重新排序(因为一个对象可能直接由多个核心对象可达,因此,可达距离近的肯定是更好的选择);
3.4.如果有序队列中不存在该直接密度可达样本点,则插入该点,并对有序队列重新排序;
4、迭代2,3。
5、算法结束,输出结果队列中的有序样本点。
认真学了了DBSCAN算法,肯定会对OPTICS算法感到熟悉。因为这两个算法的推进过程基本上是完全一样的。
OK,对照算法,再回想一下我说的那两句话。
1、较稠密簇中的对象在簇排序中相互靠近;
2、一个对象的最小可达距离给出了一个对象连接到一个稠密簇的最短路径。
是不是体会更深刻了一些?
OPTICS全称是Ordering points to identify the clustering structure 。翻译过来就是,对点排序以此来确定簇结构。实际上,我觉得这个名字就点出了这个算法很多东西了。
最后,参考Wiki上的图,来具体感受下OPTICS最后跑出来的结果。
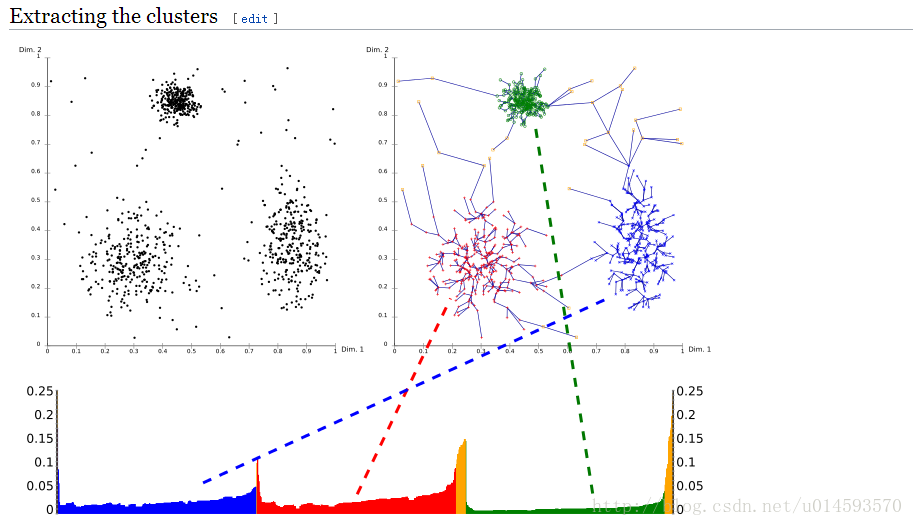
多的不说,直说下面几点
1、X轴代表OPTICS算法处理点的顺序,y轴代表可达距离。
2、簇在坐标轴中表述为凹陷(山谷??Valley),并且凹陷越深,簇越紧密
3、黄色代表的是噪声,它们不形成任何凹陷。
在最开始就已经说了,OPTICS是用的广泛的参数。
当你需要提取聚集的时候,参考Y轴和图像,自己设定一个阀值就可以提取聚集了。这里将阀值设为0.1就挺合适的。
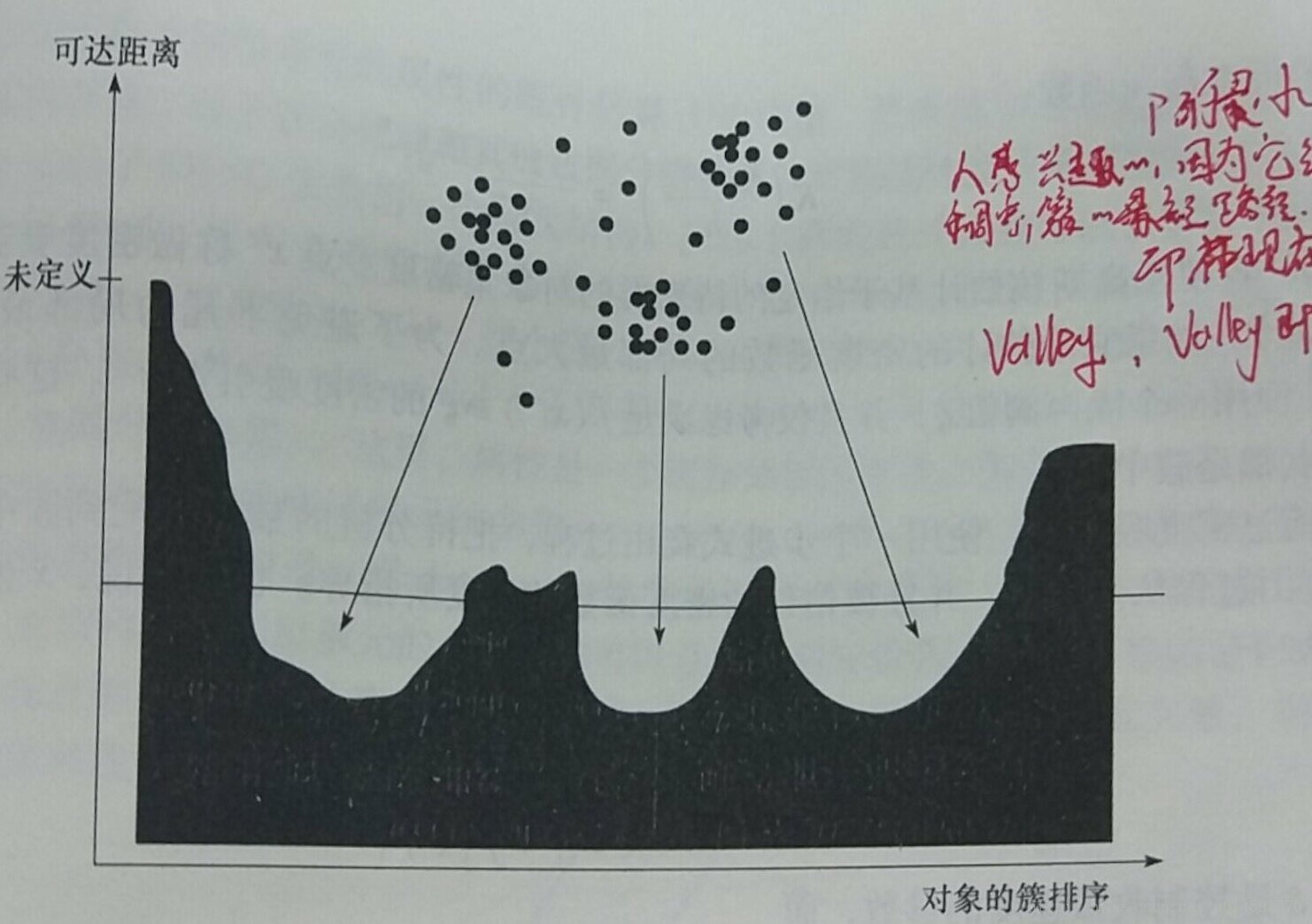
再来一张凹陷明显的















 3102
3102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









