







最近在参加一个识别的竞赛,项目里涉及了许多类别的分类,原本打算一个大的类别训练一个分类模型,但是这样会比较麻烦,对于同一图片的分类会重复计算分类网络中的卷积层,浪费计算时间和效率。后来发现现在深度学习中的多任务学习可以实现多标签分类,所有的类别只需要训练一个分类模型就行,其不同属性的类别之间是共享卷积层的。我所有的项目开发都是基于caffe框架的,默认的,Caffe中的Data层只支持单维标签,不支持多标签分类。我也是参考了大牛的博客修改了caffe里面的源码,使得caffe支持多标签分类。下面介绍怎么在caffe中修改源码支持多标签,包括训练和测试过程的修改。
Caffe源码修改:
需要修改Caffe中的convert_imageset.cpp以支持多标签,convert_imageset.cpp是在caffe的根目录下的tools文件下。我是直接下载了修改后的convert_imageset.cpp替换了我原来的convert_imageset.cpp。然后需要重新编译caffe,进入caffe目录下,输入指令:
make clean
make –j4
make pycaffe
好了,到了这里如果没有出错caffe就可以支持多标签分类了,接下来就是根据自己的数据和多标签类别数目训练网络模型。
注:基于好多人找我要convert_imageset.cpp,我把它上传了:
http://download.csdn.net/detail/xjz18298268521/9776275
需要的可以自己去下载。
修改代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
训练模型:
上面我们就有了多任务的深度学习的基础部分数据输入。为了向上兼容Caffe框架,我也是参考了大牛的博客,摒弃了部分开源实现增加Data层标签维度选项并修改Data层代码的做法,直接使用两个Data层将数据读入,即分别读入数据和多维标签。接下来详细介绍训练所需要做的步骤以及和修改。
1. Lmdb的数据制作
由于篇幅的原因,我只贴了部分主要的代码图,注意下图标红的部分,第一个是你多标签所需要的类别数目,第二个是一些数据的路径。
由于现在为了支持多标签,把数据和标签分开了,以前的单标签在data层数据和标签在一起的对应的(自己的理解)。所以第三和第四初标红的是test和train最后用于训练的lmdb数据和对应多维标签。这制作lmdb脚本文件我会放在我的博客资源上:
http://download.csdn.net/detail/xjz18298268521/9708564
你们可以根据自己的需求下载后自己修改,执行脚本文件后,相对应的路径下会生成对应的四个lmdb数据文件。到这里lmdb的数据制作完毕,后面的均值文件的制作和原来的是一样的。
2.修改训练网络模型train_val.prototxt

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
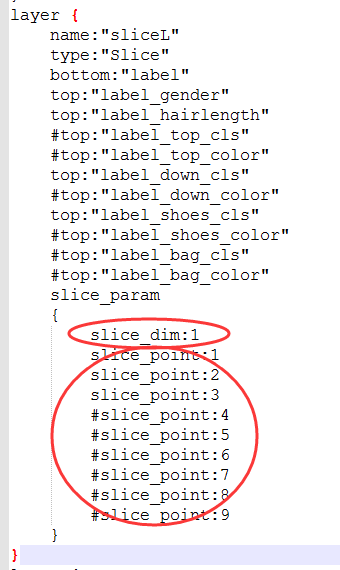
修改完网络模型的data层,后面需要将标签数据库中的内容进行切分,拆分成各个属性的标签,需要添加Slice层,Slice层是将一个输入层根据切割指标给定的维度(现在只有num和channel)切割成多个输出层,如下图所示。有几类标签就定义几类top并命名不同,用于连接最后的accuracy层。对于slice层的参数:
- slice_dim: 目标维度,0 for num and 1for channel,一般选1;
- slice_point:指定选定维数的索引(索引的数量必须等于blob数量减去一),我一共是4,所以减一为3。
3.最后的损失函数的设计
以前单标签的时候,只需要设计一个损失函数,现在是多标签分类需要设计多个损失函数层,使得每一大类别对应一个损失函数层,下图是一个类别的损失函数层和对应的test层:
对于Accuracy层中的两个bottom:第一个需要连接对应的全连接层,第二个需要连接前面用slice层切割对应的标签层。
对于softmaxwithloss层的两个bottom:第一个需要连接对应的全连接层,第二个需要连接前面用slice层切割对应的标签层。Loss_weight:需要填写这个损失函数的损失值在最终总的损失函数值中所占的权重值,一般的,建议所有任务的权重值相加为1,如果这个数值不设置,可能会导致网络收敛不稳定,这是因为多任务学习中对不同任务的梯度进行累加,导致梯度过大,甚至可能引发参数溢出错误导致网络训练失败。
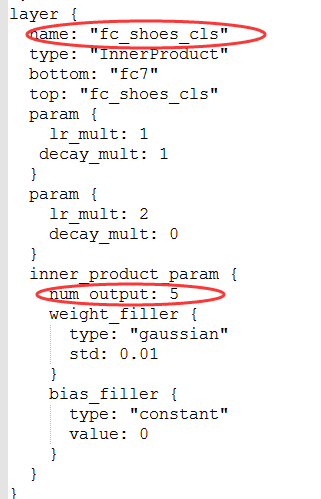
这里还有一个问题,就是以前单标签的时候,最后一层的全连接层fc8层的out_num是固定的,大小是根据单标签分类的类别数目来定的,而现在多标签中的每一个标签的类别属性大小是不同一的。所以这里在每一标签对应的损失函数前添加一个全连接层,对应的输出out_num大小等于对应标签的类别数目。添加的所有全连接层都连接到原来的第二个全连接层,即fc7层,如下图所示,到这里训练基本的都准备完毕,后面的训练的步骤和原来单标签的训练基本是一样的,接下来就可以训练了。
测试过程
修改deploy.prototxt文件,前面的网络层是不需要修改的,只需要修改对应的最后一层全连接层和损失函数层,修改的方式和前面训练trian_val.prototxt的是一样的,每一个标签类别需要一个属于自己的全连接层和损失函数层,如下图所示:


-
顶
- 3
-
踩














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









