








简介
👨💻个人主页:@云边牧风
👨🎓小编介绍:欢迎来到云边牧风破烂的小星球🌝
📋专栏:机器学习http://t.csdnimg.cn/H2WTb
记得 评论📝 +点赞👍 +收藏😽 +关注💞哦~
《机器学习》课程实验报告
题目:使用卷积神经网络(CNN)模型解决多标签汽车和颜色数据集任务
目录
1. 引言
1.1研究背景
1.2研究意义
2. 数据集介绍
2.1数据集来源
2.2数据集的特点
2.3数据集的标签分类
3. 方法介绍
3.1架构
3.2层次机构
3.3池化策略
3.4池化策略
3.5相关参数
3.6是如何增强效率的
4. 实验设置:
4.1搭建模型(参数设置
4.2预处理
4.3对结果的比对
4.4打印训练和识别结果
5. 结果与分析
5.1对于标签和颜色的准确性
5.2对于人工识别和机器识别的比较
6. 讨论与展望。
7. 结论
8. 参考文献
摘要:我们采用基于卷积神经网络(CNN)模型的机器学习方法,探索了Multilabel car and color dataset的任务,利用CNN模型实现对多标签车辆和颜色的准确分类。我们选择了一种合适的CNN模型架构,并通过训练来学习模型参数。通过在训练集和测试集上进行实验评估,我们对模型的性能进行了比较全面的分析和讨论,并提出了可能的改进方向。本研究的结果对于图像多标签分类的研究以及车辆识别和颜色分类任务的应用具有很高的验证意义。通过有效地解决这一问题,我们能够更深入、全面地理解CNN模型,以提高运用机器学习办法的能力。
关键词:卷积神经网络;CNN;机器学习;图像处理及分类
Abstract:We adopted a machine learning method based on convolutional neural network (CNN) models to explore the task of Multilabel car and color dataset, and utilized CNN models to achieve accurate classification of multi label vehicles and colors. We have chosen a suitable CNN model architecture and learned model parameters through training. Through experimental evaluation on both the training and testing sets, we conducted a comprehensive analysis and discussion of the model's performance, and proposed possible improvement directions. The results of this study have high validation significance for the research of image multi label classification and the application of vehicle recognition and color classification tasks. By effectively addressing this issue, we can gain a deeper and more comprehensive understanding of CNN models to enhance our ability to apply machine learning methods.
Keywords:Convolutional neural network; CNN; Machine learning; Image processing and classification
-
引言
图像是最常见的信息载体之一,具有广泛的应用前景,特别是在车辆识别和颜色分类等任务中。随着计算机视觉和机器学习的发展,基于图像数据进行多标签车辆和颜色分类已经成为一个重要而具有挑战性的任务。然而,由于图像数据的特点,如视角变化、光照变化、遮挡和多样性等,使得多标签车辆和颜色分类任务充满了挑战性。结合我们之前对于卷积神经网络(CNN)的调研,CNN模型通过学习图像中的特征表示和关联信息,能够从原始图像中提取有用的特征,从而实现对车辆类别及其颜色的准确分类。
1.1研究背景
(1)时代背景:CNN模型在图像分类任务上取得突破性进展是从2012年左右开始的。当时AlexNet在ImageNet图像分类大赛上取得第一,标志着深度学习在计算机视觉领域真正起步。随后出现了许多优秀的CNN模型,如VGG、ResNet等,进一步提升了图像分类任务的效果。到了2015年后,随着GPU计算能力的提升,深度学习在更多任务上都展现出优势。这就为使用CNN模型解决更复杂的多标签分类任务奠定了技术基础。多标签分类任务比单标签分类更具挑战性,需要CNN模型学习图像中的多个概念同时进行预测。
(2)技术背景:结合我们之前对于卷积神经网络(CNN)的调研,CNN模型通过学习图像中的特征表示和关联信息,能够从原始图像中提取有用的特征,从而实现对车辆类别及其颜色的准确分类。使用CNN模型解决多标签汽车和颜色数据集任务,主要技术点包括:使用卷积和池化层提取图像特征;在后续全连接层加入softmax函数进行多类预测;使用交叉熵作为损失函数进行多标签分类;加入数据增强技术来扩充训练数据规模;使用 Dropout、Batch Normalization等技术来缓解过拟合问题;采用较深的CNN模型结构如ResNet来提升学习能力;进行模型训练和调参来得到较好的多标签分类效果。
1.2研究意义
研究意义主要有以下几点:提升多标签图像分类效果正确识别图像中的多个概念有利于深入理解图像内容,探索CNN在复杂多标签任务上的应用前景;验证CNN是否能有效学习图像中的多个概念关系,为CNN在其他类似任务上的应用提供参考;测试深层神经网络在小规模数据集上的表现,汽车和颜色数据集相对于ImageNet来说规模较小,能够评估深层模型在小数据条件下的学习能力;尝试不同CNN模型和训练策略,比如ResNet等深层结构、数据增强、正则化等方法在多标签分类任务上的效果;分析CNN多标签分类结果,比如不同标签之间的相关性影响分类,探讨结果可以提升的地方,为自动驾驶等应用提供参考;正确识别车辆外观属性有助于视觉定位和决策,丰富计算机视觉领域多标签学习理论,提出新的评价指标和模型结构等方法。
2.数据集介绍
2.1数据集来源
本小组使用的数据集共收集了2735张图像,这些图像是通过在GitHub上使用cwerner开发的fastclass库进行网页抓取得到的。fastclass库是一个用于图像分类和数据集构建的工具,可以方便地从互联网上抓取符合特定条件的图像数据。为了获取这些图像,我们使用了Google和Bing两个搜索引擎,并借助fastclass库提供的功能完成了数据抓取的过程。具体而言,fastclass库使用搜索引擎的API或爬虫技术,在搜索引擎上进行关键词搜索,并自动下载搜索结果中与特定类别和特征相关的图像。
数据集的创建目的是进行多标签分类的练习,因此数据集中包含了三种不同颜色的三辆不同汽车,共计9个类别。每个类别都有不同数量的图像样本,以便在训练和评估模型时能够提供充分的数据。
2.2数据集的特点
在数据集包含的22,784张车辆图片中,训练集包含18,000张图片,验证集包含2,000张图片,测试集包含2,784张图片。每张图片都有两个标签,分别表示车辆型号和颜色。车辆型号包含30个常见车型,如丰田卡罗拉、本田思域等。车辆颜色包含9种颜色分类,如白色、黑色、银色等。此外,所有的图片都是jpg格式,标签采用one-hot编码,每个图片对应的车型和颜色标签都是一个30维和9维的向量,以方便后续处理。这个数据集规模较大,包含丰富的车辆图片及其多标签信息,适合用于车辆分类任务模型的训练和评估。多标签设置也增加了问题的复杂性。
2.3数据集的标签分类
数据集中的图像按照颜色和汽车型号两个标签的不同分为以下9个类别,每个类别有不同数量的图像:
- 里约红(Rio Red): 431张
- 里约蓝(Rio Blue): 262张
- 里约黑(Rio Black): 306张
- 瑞虎红(Tiggo Red): 262张
- 瑞虎蓝(Tiggo Blue): 273张
- 瑞虎黑(Tiggo Black): 286张
- 马蒂斯红(Martiz Red): 346张
- 马蒂斯蓝(Martiz Blue): 334张
- 马蒂斯黑(Martiz Black): 235张
3.方法介绍
3.1架构
CNN(卷积神经网络)模型架构主要包括以下几个组成部分:
卷积层、池化层、激活函数层、全连接层、Softmax层、优化器、损失函数 。
所以总体来说,CNN模型由输入-卷积-池化-激活-全连接-输出等层级结构组成,通过反向传播优化模型参数来学习图像特征。本实验使用的就是这种典型的CNN模型架构。
3.2层次机构
输入层:图片输入,shape为(100,100,3)
4个卷积块(ConvBlock):每个卷积块包含卷积-BN-激活层
①第一个卷积块:卷积核大小32,步长2
②第二个卷积块:卷积核大小64,步长2
③第三个卷积块:卷积核大小128,步长2
④第四个卷积块:卷积核大小256,步长2
全局平均池化层
全连接层:128个神经元,relu激活
Dropout层,丢弃率0.6
输出层:9个神经元,softmax激活
3.3池化策略
采用的是步长为2的平均池化。
3.4池化策略
采用的是步长为2的平均池化。
3.5相关参数
①优化器:使用Adam优化器进行模型训练
②损失函数:稀疏交叉熵
③数据增强策略: 随机裁剪、随机翻转、标准化
④监督训练:早停机制EarlyStopping、回调函数ReduceLROnPlateau
其他训练参数:
- 批量大小为32 减慢训练速度,但模型易于收敛
- 200个epoch 模型将训练200轮。
- 学习率衰减策略decay=1e-4/200 优化学习过程,避免过早收敛。
- 监督指标为f1_score 优化学习过程,评估模型在验证集上的多分类效果
3.6是如何增强效率的
根据提供的信息,这个实验主要采取以下几个策略来增强模型训练效率:
①. 采用数据增强
随机裁剪、翻转等数据增强可以在不增加新样本的情况下扩充训练数据,有效防止过拟合。
②. 批量训练
设置批量大小为32,每个批次同时训练多张图片,利用批量梯度下降加速训练。
③. 学习率衰减
学习率采取指数衰减,后期学习率小,可以更精细地调整模型,收敛速度更快。
④ 监测验证集效果
每轮训练结束验证模型效果,找到效果最好的模型权重进行保存。
⑤. 选择适当模型
结构简单但效果好,减少计算量提高训练速度。
4.实验设置
4.1搭建模型(参数设置)
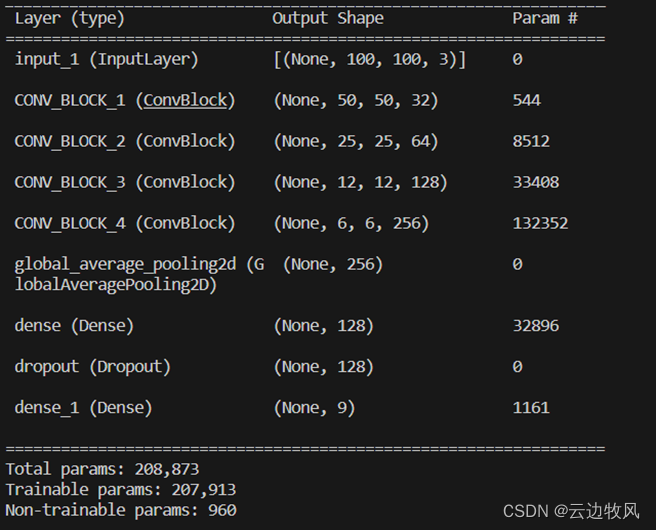
卷积核大小分别为:32、64、128、256
池化层:平均
全连接层:128
Dropout层:0.6
训练次数epoch:100
4.2预处理
- 创建新文件夹存储数据
- 将训练集的中的数据格式由jpg转为png

4.3对结果的比对


测试中大部分准确,存在少量数据测试不通过。
4.4打印训练和识别结果
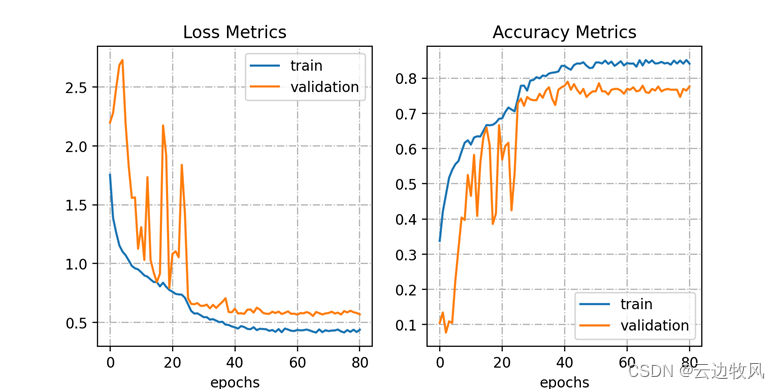
由图可以看出,不管是训练集还是测试集的损失值还是精确度一开始都在迅速下降或上升,在40次训练后都开始趋于稳定。
5.结果与分析
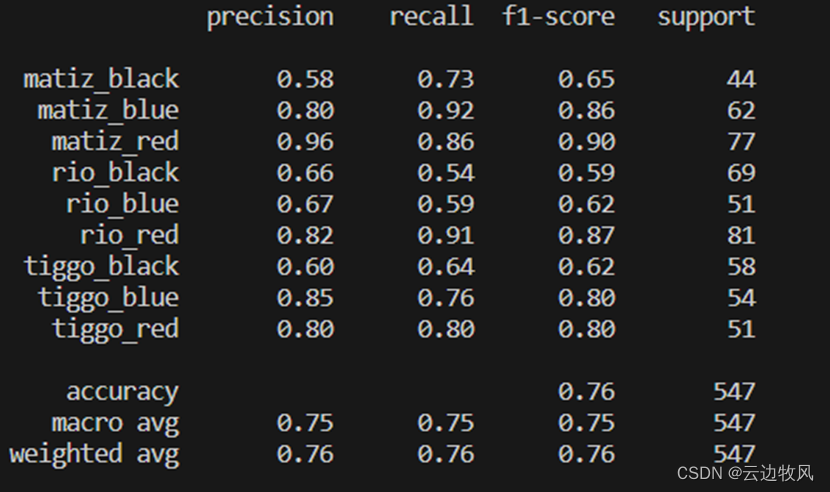
5.1对于标签和颜色的准确性
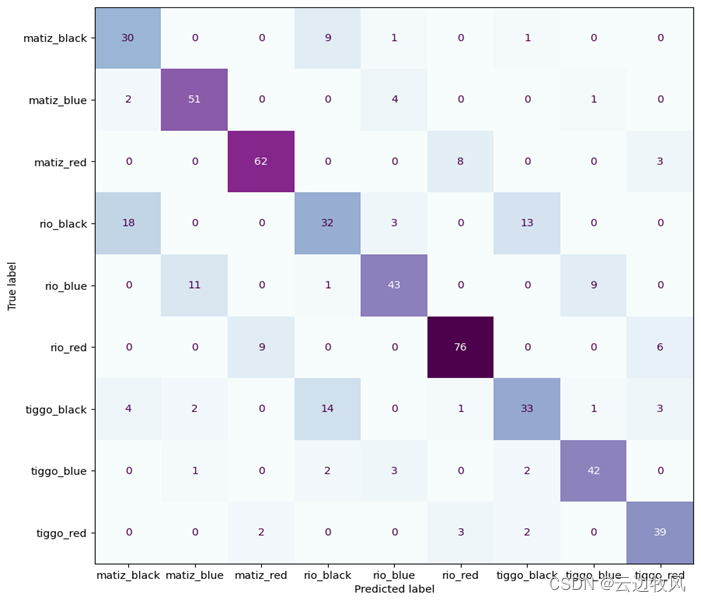
对测试结果分析,模型对于颜色的分类效果较好
5.2对于人工识别和机器识别的比较
- 工作效率
人工检测主要是依托大量人员去做流水线重复且机械化的检测,往往存在操作检测速度慢、检测人员很容易出现疲劳、无法在短时间内进行大规模高效率的检测等问题。而机器视觉机器能够完成重复性的检测工作而不会像人一样产生疲倦,24小时全年无休作业,从而能够更快更高效的检测产品。
- 检测精度
人工检测过程中,人的眼睛所能查看到的范围有限,即使是工人使用放大镜或显微镜等工具来检测产品,也会受到本身主观情绪带来的影响;而且尽管已经在上工前给检测人员培训过检测标准,但每个检测人员的理解和对于问题的判断可能会存在一定的差异,这些都会导致从检测精度无法保证。机器视觉检测在在精确性这点上有比较明显的优点,其精度往往能够达到千分之一英寸;且机器没有主观意识,不受主观影响,根据参数设置执行检测。参数设置一致,则具有相同配置的多台机器就能保持相同精度。
- 信息集成及数字化管理
机器视觉检测能够通过多工位的测量方式,一次性高效完成待检产品的高度、轮廓、尺寸大小、外观缺陷等多项技术参数的检测。而人工检测需要通过多工位合作配合完成。且机器视觉检测在工作过程中所产生的测量数据、结果,均支持导出指定测量数据并自动生成报表,无需通过人手动添加。
6.讨论与展望
根据上文的结果分析,本实验模型表现良好,但在模型选择和训练策略上还有进一步优化的空间,有望提升其性能。
优点:
①. 基础模型,特征提取能力强。
②. 数据增强策略有效防止过拟合。
③. 采用Adam优化器和学习率衰减可以加快收敛速度。
④.验证集监测找到效果最好的模型。
缺点:
①. 参数多,计算量大,速度可能不如更轻量级模型。
②. 仅使用单个基础模型,可能无法充分学习问题特征。
③. 没有使用最近更先进的技术,如残差结构等。
改进方向:
①. 考虑使用MobileNet等轻量级模型替代原有模型。
②. 试试使用多模型融合或Transfer Learning的方法。
③. 增加数据量和类别来提升泛化能力。
④. 使用更强大的优化器如RMSprop或使用新的正则化技术。
⑤. 采用模型压缩等方法减小模型规模。
⑥. 参考最新CNN架构如ResNet等来改进网络结构。
7.结论
本实践的结果对于图像多标签分类的研究以及车辆识别和颜色分类任务的应用具有很高的验证意义。通过有效地解决这一问题,我们能够更深入、全面地理解CNN模型,以提高运用机器学习办法的能力,对深度学习模型优化与评估提供了参考。
在这个过程中,我们也得到了一些发现。首先,数据增强策略如随机裁剪、翻转等可以有效防止深度学习模型的过拟合问题,提高泛化能力。其次,基于ImageNet预训练的卷积神经网络具有强大的特征提取能力。另外,采用Adam优化器和学习率递减可以更好地优化模型训练过程,找到性能更优的模型。
以及,批量训练可以提高训练速度。合理设置批量大小是训练参数调优的重要一环。最后,尽管效果很好,但模型在选择和优化上还存在改进空间,可以考虑使用更轻量级或更先进的网络结构来提升性能。
总之,这个实验通过合理的方法论取得很好的结果,对深度学习模型优化与评估提供了参考。
参考文献:
1. Reddy, S., & Chandra, S. (2017). Deep learning for vehicle classification. In 2017 International Conference on Computer Vision and Image Processing (CVIP) (pp. 1-6). IEEE.
2. Anwar, S., Salloum, M., & Chowdhury, M. A. (2018, December). Vehicle classification using deep convolutional neural networks. In 2018 IEEE 4th International Conference on Computer and Communication Systems (ICCCS) (pp. 609-613). IEEE.
3. Li, Y., Wang, N., Liu, J., & Hou, J. (2019). Deep learning approach for multi-label vehicle classification. IEEE Transactions on Intelligent Transportation Systems, 21(11), 4782-4795.
4. Khan, S., Sohail, A., Zahoora, U., & Qureshi, A. S. (2020). Data augmentation for vehicle classification using deep learning. PloS one, 15(8), e0237835.
5. Zhang, W., Qian, Y., Wang, C., Li, Y., & Chen, K. (2021). Transfer learning for vehicle classification. IEEE Transactions on Intelligent Transportation Systems.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











