








0、引入
哈希表支持一种最有效的检索方法:散列。从根本上来说,一个哈希表包含一个数组,通过特殊的索引值(键)来访问数组中的元素。哈希表的主要思想是通过一个哈希函数,在所有可能的键与槽位之间建立一张映射表。哈希函数每次接受一个键将返回与键相对应的哈希编码或哈希值。键的数据类型可能多种多样,但哈希值的类型只能是整型。
由于计算哈希值和在数组中进行索引都只消耗固定的时间,因此哈希表的最大亮点在于它是一种运行时间在常量级的检索方法。当哈希函数能够保证不同的键生成的哈希值互不相同时,就说哈希表能直接寻址想要的结果。但这只是理想的状态,在实际运用过程中,能够直接寻址结果的情况非常少。例如,一个电话邮件系统,通过8个字符组成的名字作为键,来哈希得到系统中的用户信息。如果我们想依赖直接寻址,那么这个哈希表将会有超过26^8=2.09×10^11个条目,而这些条目中的绝大多数都是无用的,因为大多数的字符组合都不是姓名。
通过与各种各样的键相比,哈希表的条目数相应较少。因此,绝大多数哈希函数会将一些不同的键映射到表中相同的槽位上。当两个键映射到一个相同的槽位上时,它们就产生了冲突。一个好的哈希函数能最大限度地减少冲突,但冲突不可能完全消除,我们仍然要想办法处理这些冲突。
1、链式哈希表的描述
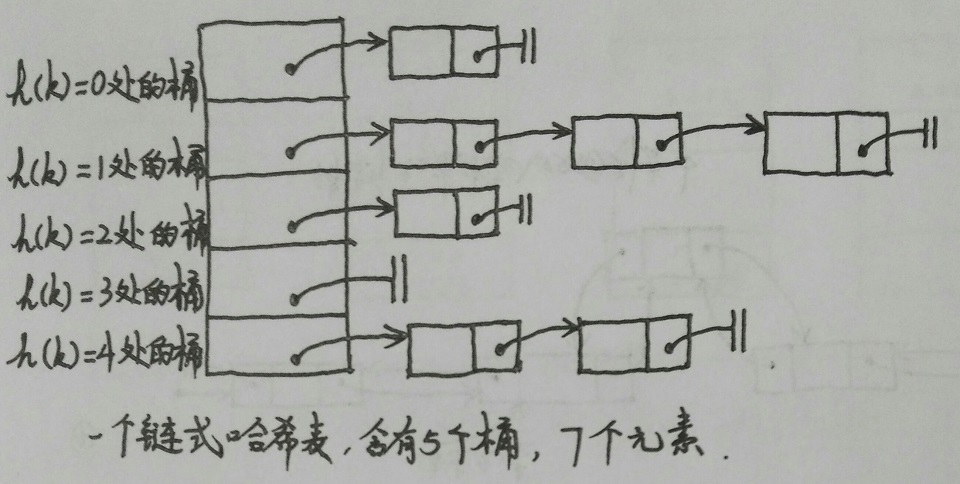
链式哈希表从根本上来说是由一组链表构成。每个链表都可以看做一个"桶",我们将所有的元素通过散列的方式放到具体的不同的桶中(见下图)。插入元素时,首先将其键传入一个哈希函数(该过程称为哈希键),函数通过散列的方式告知元素属于哪个"桶",然后在相应的链表头插入元素。查找或删除元素时,用同样的方式先找到元素的"桶",然后遍历相应的链表,直到发现我们想要查找的元素。因为每个"桶"都是一个链表,所以链式哈希表并不限制包含元素的个数。然而,如果表变得太大,它的性能将会降低。
解决冲突
当哈希表中两个键散列到一个相同的槽位时,这两个键之间将会产生冲突。链式哈希表解决冲突的方法非常简单:当冲突发生时,它就将元素放到已经准备好的"桶"中。但这同样会带来一个问题,当过多的冲突发生在同一槽位时,此位置的"桶"将会变得越来越深,从而造成访问这个位置的元素所需要的时间越来越多。
在理想情况下,我们希望所有"桶"以几乎同样的速度增长,这样它们就可以尽可能地保持小的容量和相同的大小。换句话说,我们的目标就是尽可能地均匀和随机地分配表中的元素,这种情况在理论上称为均匀散列,而在实际中,我们只能尽可能近似达到这种状态。
如果想插入表中的元素数量远大于表中"桶"的数量,那么即使是在一个均匀散列的过程中,表的性能也会迅速降低。在这种情况下,表中所有的"桶"都变得越来越深。因此,我们必须要特别注意一个哈希表的负载因子,其定义为:
α=n/m
其中,n是表中元素的个数,m是"桶"的个数。在均匀散列的情况下,链式哈希表的负载因子告诉我们表中的"桶"能装下元素个数的最大值。
例如,有一个链式哈希表,其"桶"的数量m=1599,元素的数量n=3198,其负载因子α=3198/1599=2。所以在这种情况下,当查找元素时,可能每个"桶"里面的元素不会超过两个。当有一个表的负载因子小于1时,这个表每个位置所包含的元素不超过一个。当然,由于均匀散列是一个理想的近似情况,因此在实际情况中我们往往多少会检索超过负载因子建议的数值。如何达到更接近于均匀散列的情况,最终取决于如何选择哈希函数。
选择哈希函数
一个好的哈希函数旨在近似均匀散列,也就是,尽可能以均匀和随机的方式散布一个哈希表中的元素。定义一个哈希函数f,它将键k映射到哈希表中的位置x。x称为k的哈希编码,正式的表述为:
h(k)=x
一般来说,大多数的散列方法都假设k为整数,这样k能够很容易地以数学方式修改,从而使得h能够更均匀地将元素分布在表中。当k不是一个整数时,我们也可以很容易地将它强制转换为整型。
如何强制转换一组键,很大程度上取决于键本身的特点。所以,在一个特定的应用中,尽可能地获取键的特性显得尤为重要。例如:如果我们想对程序中的标识符进行散列,会发现程序中有很多相似的前缀和后缀,假使开发人员倾向于将变量声明为类似sampleptr、simpleptr、sentryptr的名字。我们可以严格按照键的开头和结尾字符来强制转换,但这显然不是一个好的方法,因为对于一个k会有多个标识符与之对应。另一方面,我们不妨随机地从4个位置来选择字符,然后随机地改变它们的顺序,并将它们封装到一个4字节的整数中。要记住,无论用什么方法来强制转换键,目的都是尽可能选择一个能将键均匀、随机地分布到表中的哈希函数。
取余法
有一个整型键k,一种最简单地将k映射到m个槽位的散列方法是计算k除以m的所得到的余数。我们称之为取余法,正式的表述为:
h(k) = k mod m
如果表有m=1699个位置,而要散列的键k=25657,通过这种方法可以得到哈希编码为25657 mod 1699=172。通常情况下,要避免m的值为2的幂。这是因为假如m=2^p,那么h仅仅是k的p个最低阶位。通常我们选择的m会是一个素数,且不要太接近于2的幂,同时还要考虑存储空间的限制和负载因子。(使用取余法的一个经验是,通常m为小于或等于表长(最好接近表长)的最小质数或不包含小于20质因子的合数。)
例如,如果我们想往一个链式哈希表中插入n=4500个左右的元素,会选择m=1699(m是一个介于2^10~2^11之间的素数)。由此可以计算出它的负载因子α=4500/1699≈2.6,根据均匀散列表述,这说明表中每个"桶"大概能容纳2~3个元素。
乘法
与取余法不同的是乘法,它将整型键k乘以一个常数A(0<A<1);取结果的小数部分;然后乘以m取结果的整数部分。通常情况下,A取0.618,它由√5减1再除以2得到。这个方法称为乘法,正式的表述为:
h(k)=⌊m(kA mod 1)⌋,其中A=(√5 - 1)/2≈0.618
这种方法有个优点是,对于表中槽位个数m的选择并不需要像取余法中那么慎重。例如:如果表有m=2000个位置,散列的键k=6341,那么得到的哈希编码为2000×(6341×0.618 mod 1)=2000×(3918.738 mod 1)=2000×0.738=1476。
在链式哈希表中,如果期望插入的元素个数不超过n=4500个,可以让m=2250.这样得到的负载因子α=4500/2250=2,根据均匀散列的规则,在每个"桶"中存储的元素个数一般不超过两个。同时请注意,这个散列方法可以让我们更灵活地选择m,以便获取我们可以接受的最大"桶"深。
下面的代码列举了一个能够较好地处理字符串的哈希函数。它通过一系列的位操作将键强制转换为整数。最后结果是通过取余法来得到的。这个哈希函数针对哈希字符串执行得很好。(此函数改编自《Compilers: Principles, Techniques, and Tools》,是为编译器所写的一个哈希函数。)
// 一个适用于处理字符串的哈希函数
/* hashpjw.c */
#include "hashpjw.h"
/* hashpjw */
unsigned int hashpjw(const void *key)
{
const char *ptr;
unsigned int val;
/* Hash the key by performing a number of bit operations on it. */
val = 0;
ptr = key;
while(*ptr != '\0')
{
unsigned int tmp;
val = (val << 4) + (*ptr);
if(tmp = (val & 0xf0000000))
{
val = val ^ (tmp >> 24);
val = val ^ tmp;
}
ptr++;
}
/* In practice, replace PRIME_TBLSIZ with the actual table size. */
return val % PRIME_TBLSIZ;
}
2、链式哈希表的接口定义
chtbl_init
——————
int chtbl_init(CHTbl *htbl, int buckets, int (*h)(const void *key), int (*match)(const void *key1, const void *key2), void (*destroy)(void *data));
返回值:如果哈希表初始化成功,返回0;否则返回-1。
描述:初始化htbl指定的链式哈希表。在对链式哈希表进行其他操作之前必须首先调用初始化函数。哈希表中所分配的"桶"的个数将由buckets指定。函数指针h指向一个用户定义的哈希函数,此函数会将键进行散列。函数指针match指向一个用户定义的函数,此函数用于判断两个键是否匹配。如果key1等于key2,返回1;否则返回其他值。参数destroy是一个函数指针,通过在chtbl_destroy中调用来释放动态分配的内存空间。例如,一个哈希表包含使用malloc动态分配内存的数据,那么当销毁此哈希表时,destroy会调用free来释放内存空间。当结构化数据包含若干动态分配内存的数据成员时,destroy应该指向一个用户自定义的函数来释放每个动态分配的数据成员和结构本身的内存空间。如果哈希表中的数据不需要释放,那么destroy应该指向NULL。
复杂度:O(m),m是哈希表中"桶"的个数。
chtbl_destroy
——————
void chtbl_destroy(CHTbl *htbl);
返回值:无
描述:销毁htbl指定的链式哈希表。在调用chtbl_destroy之后不再允许进行其他操作,除非再次调用chtbl_init。chtbl_destroy会删除哈希表中的所有元素,并当参数destroy不为NULL时释放结构体中成员所占用的内存空间。
复杂度:O(m),m是哈希表中"桶"的个数。
chtbl_insert
——————
int chtbl_insert(CHTbl *htbl, const void *data);
返回值:如果插入元素成功,返回0;如果哈希表已经包含此元素,返回1;否则,返回-1。
描述:向htbl指定的链式哈希表中插入一个元素。新元素包含一个指向data的指针,只要元素仍然存在于哈希表中,此指针就一直有效。与data相关的内存空间将由函数的调用者来管理。
复杂度:O(1)
chtbl_remove
——————
int chtbl_remove(CHTbl *htbl, void **data);
返回值:如果删除元素成功,返回0;否则,返回-1。
描述:从htbl指定的链式哈希表中删除与data匹配的元素。返回时,data指向已删除元素中存储的数据。与data相关的内存空间将由函数的调用者来管理。
复杂度:O(1)
chtbl_lookup
——————
int chtbl_lookup(const CHTbl *htbl, void **data);
返回值:如果在哈希表中找到元素,返回0;否则,返回-1。
描述:查找htbl指定的链式哈希表中是否有与data相匹配的元素。如果找到,在函数返回时,data将指向哈希表中相匹配元素中的数据。
复杂度:O(1)
chtbl_size
——————
int chtbl_size(CHTbl *htbl);
返回值:哈希表中元素的个数。
描述:获取htbl指定的链式哈希表元素个数的宏。
复杂度:O(1)
3、链式哈希表的实现与分析
链式哈希表包含一组"桶",每个"桶"其实是一个链表,链表用来存储散列到表中某些槽位的元素。结构CHTbl是链式哈希表的数据结构。这个结构包含6个成员:buckets指明表中分配的"桶"的个数;h、match和destroy用于封装传入chtbl_init函数的函数;size指明表中现有元素的数量;table是存储"桶"的数组。
// 链式哈希表抽象数据类型的头文件
/* chtbl.h */
#ifndef CHTBL_H
#define CHTBL_H
#include <stdlib.h>
#include "list.h"
/* Define a structure for chained hash tables. */
typedef struct CHTbl_
{
int buckets;
int (*h)(const void *key);
int (*match)(const void *key1, const void *key2);
void (*destroy)(void *data);
int size;
List *table;
} CHTbl;
/* Public Interface */
int chtbl_init(CHTbl *htbl, int buckets, int (*h)(const void *key), int (*match)(const void *key1, const void *key2), void (*destroy)(void *data));
void chtbl_destroy(CHTbl *htbl);
int chtbl_insert(CHTbl *htbl, const void *data);
int chtbl_remove(CHTbl *htbl, void **data);
int chtbl_lookup(const CHTbl *htbl, void **data);
#define chtbl_size(htbl) ((htbl)->size)
#endif // CHTBL_H
// 链式哈希表的实现
/* chtbl.c */
#include <stdlib.h>
#include <string.h>
#include "list.h"
#include "chtbl.h"
/* chtbl_init */
int chtbl_init(CHTbl *htbl, int buckets, int (*h)(const void *key), int (*match)(const void *key1, const void *key2), void (*destroy)(void *data))
{
int i;
/* Allocate space for the hash table. */
if((htbl->table = (List *)malloc(buckets * sizeof(List))) == NULL)
return -1;
/* Initialize the buckets. */
htbl->buckets = buckets;
for(i = 0; i < htbl->buckets; i++)
list_init(&htbl->table[i], destroy);
/* Encapsulate the functions. */
htbl->h = h;
htbl->match = match;
htbl->destroy = destroy;
/* Initialize the number of elements in the table. */
htbl->size = 0;
return 0;
}
/* chtbl_destroy */
void chtbl_destroy(CHTbl *htbl)
{
int i;
/* Destroy each bucket. */
for(i = 0; i < htbl->buckets; i++)
{
list_destroy(&htbl->table[i]);
}
/* Free the storage allocated for the hash table. */
free(htbl->table);
/* No operations are allowed now, but clear the structure as a precaution. */
memset(htbl, 0, sizeof(CHTbl));
return;
}
/* chtbl_insert */
int chtbl_insert(CHTbl *htbl, const void *data)
{
void *temp;
int bucket, retval;
/* Do nothing if the data is already in the table. */
temp = (void *)data;
if(chtbl_lookup(htbl, &temp) == 0)
return 1;
/* Hash the key. */
bucket = htbl->h(data) % htbl->buckets;
/* Insert the data into the bucket. */
if((retval = list_ins_next(&htbl->table[bucket], NULL, data)) == 0)
htbl->size++;
return retval;
}
/* chtbl_remove */
int chtbl_remove(CHTbl *htbl, void **data)
{
ListElmt *element, *prev;
int bucket;
/* Hash the key. */
bucket = htbl->h(*data) % htbl->buckets;
/* Search for the data in the bucket. */
prev = NULL;
for(element = list_head(&htbl->table[bucket]); element != NULL; element = list_next(element))
{
if(htbl->match(*data, list_data(element)))
{
/* Remove the data from the bucket. */
if(list_rem_next(&htbl->table[bucket], prev, data) == 0)
{
htbl->size--;
return 0;
}
else
{
return -1;
}
}
prev = element;
}
/* Return that the data was not found. */
return -1;
}
/* chtbl_lookup */
int chtbl_lookup(const CHTbl *htbl, void **data)
{
ListElmt *element;
int bucket;
/* Hash the key. */
bucket = htbl->h(*data) % htbl->buckets;
/* Search for the data in the buckets. */
for(element = list_head(&htbl->table[bucket]); element != NULL; element = list_next(element))
{
if(htbl->match(*data, list_data(element)))
{
/* Pass back the data from the table. */
*data = list_data(element);
return 0;
}
}
/* Return that the data was not found. */
return -1;
}
chtbl_init
链式哈希表由chtbl_init初始化,经过初始化的哈希表才能进行其他操作。链式哈希表的初始化过程比较简单,其中,首先为"桶"分配空间;然后调用list_init初始化每个"桶";接着封装h、match和destroy函数;最后将size值设置为0。
chtbl_init的时间复杂度为O(m),其中m是表中"桶"的个数。这是由于复杂度为O(1)的操作list_init将为每个"桶"执行一次(桶的数量为m)。而剩下的初始化操作都能在固定的时间内完成。
chtbl_destroy
链式哈希表由chtbl_destroy进行销毁。函数的主要功能是删除每个"桶"中的元素,然后释放由chtbl_init分配的内存空间。如果传递给函数chtbl_init的参数destroy不为NULL的话,每当一个元素被移除时都要调用一次由destroy所指向的析构函数。
chtbl_destroy的时间复杂度为O(m),其中m是表中"桶"的个数。这是由于list_destroy操作将为每个"桶"执行一次。在每个桶中,我们希望移除元素的数量和哈希表本身的负载因子相同,这个负载因子通常是一个较小的常数。
chtbl_insert
链式哈希表由chtbl_insert向表中插入元素。因为哈希表不允许插入相同的键,所以在插入元素时通常会先调用chtbl_lookup来确保表中没有重复的元素。如果散列表中的元素没有重复的键,将新元素的键散列,然后根据哈希编码将元素插入哈希表中相应位置的"桶"中。如果整个插入过程成功,表的容量将增大。
假设我们尽量遵从均匀散列的方法,chtbl_insert的时间复杂度为O(1)。这是由于chtbl_insert散列键,并在链表头插入元素的操作都是运行固定时间的运算。
chtbl_remove
链式哈希表通过chtbl_remove删除表中的元素。为了删除元素,散列元素的键,查找与元素键相匹配的"桶",然后调用list_rem_next删除元素。根据list_rem_next的要求,在删除之前,prev必须维护一个指向待删除元素的前一个元素的指针。回想一下,在list_rem_next中,data用来指向从列表中删除的数据。如果在"桶"中没有找到匹配的键,那么表明哈希表中没有此元素。如果删除过程成功,将表的大小减一。
假设我们尽量遵从均匀散列的方法,chtbl_remove的时间复杂度为O(1)。这是因为,在每个"桶"中,我们希望查找与哈希表的负载因子相同数量的元素,这个值通常是一个较小的常量。
chtbl_lookup
链式哈希表通过chtbl_lookup查找元素,并返回一个指向对应数据的指针。此操作与chtbl_remove非常类似,只是在查找到元素后它不会执行删除操作。
假设我们尽量遵从均匀散列的方法,chtbl_lookup的时间复杂度为O(1)。这是因为我们期望查找的元素数量等于哈希表的负载因子,这样所用的代价会更小。
chtbl_size
获取链式哈希表的元素数量的宏定义。它通过结构CHTble的size成员来获取元素个数。
其时间复杂度为O(1),因为访问一个结构的一个成员是一个简单的任务,运行一段固定的时间即可完成。
4、链式哈希表的例子:符号表
哈希表的一个重要应用是在编译器中,用来维护程序中出现的符号信息。正规来说,就是编译器将一种编程语言写成程序(例如,源代码是用C语言写的)翻译成另外一种能够在机器上运行的机器编码,为了能够更加有效地管理程序中的符号信息,编译器通常使用一种叫做符号表的数据结构。符号表通常由哈希表来实现,这样就能够满足编译器快速存取符号信息的要求。
在编译的过程中,编译器访问符号表也分为几个阶段。其中一个部分称为词法分析器,用来插入符号。词法分析器是编译器的重要部分,它负责将源代码中有组织的字符转换为有意义的字符串,称为语义转换。这些转换后的字符串称为标记(token),然后传到解释器进行解析。解释器进行句法分析。送入词法分析器的符号通常是字符流,词法分析器将字符流分割出来存入符号表中。词法分析器存储两种重要的属性,一个是符号的语义,另一个是构成语义的标记类型(例如,字符是一个标识符还是一个操作符)。
这里介绍的例子是一个非常简单的词法分析器,它分析字符串中的字符,然后将字符分为两组不同类型的标记:一种只包含数字;另一种包含除了数字之外的字符。为了方便起见,假设标记由输入流中的一个空格分开。词法分析器用一个函数lex来实现,当需要产生标记时,lex就会调用解释器。
该函数首先调用next_token函数(这里没有列出此函数的实现方法)来从输入流istream中获取下一个空格分割的字符串。如果next_token为NULL,那么说明输入流中没有标记了。在这种情况下,该函数返回lexit来告诉解释器没有标记需要处理了。如果next_token找到一个字符串,那么将会执行一些简单的分析来确定字符串表示哪个标记。接下来,该函数会将包含语义和标记类型的结构Symbol插入符号表symtbl中,然后把标记类型返回给解释器。Symbol类型在symbol.h中定义,在该例子中并没有列举出来。
链式哈希表是一种用来实现符号表的好方法,因为除了它能高效地存放和检索信息之外,事实上它还能用来存储无限量的数据。对编译器来说这一点非常重要,因为在词法分析完成之前我们并不知道程序会包含多少个符号。
在next_token的运行时间为常量级时,lex的时间复杂度为O(1)。因为,lex只是简单地调用复杂度为O(1)的函数chtbl_insert。
// 词法分析器的头文件
/* lex.h */
#ifndef LEX_H
#define LEX_H
#include "chtbl.h"
/* Define the token types recognized by the lexical analyzer. */
typedef enum Token_ {lexit, error, digit, other} Token;
/* Public Interface */
Token lex(const char *istream, CHTbl *symbol);
#endif // LEX_H// 词法分析器的实现
/* lex.c */
#include <ctype.h>
#include <stdlib.h>
#include <string.h>
#include "chtbl.h"
#include "lex.h"
#include "symbol.h"
/* lex */
Token lex(const char *istream, CHTbl *symtbl)
{
Token token;
Symbol *symbol;
int length, retval, i;
/* Allocate space for a symbol. */
if((symbol = (Symbol *)malloc(sizeof(Symbol))) == NULL)
return error;
/* Process the next token. */
if((symbol->lexeme = next_token(istream)) == NULL)
{
/* Return that there is no more input. */
free(symbol);
return lexit;
}
else
{
/* Determine the token type. */
symbol->token = digit;
length = strlen(symbol->lexeme);
for(i = 0; i < length; i++)
{
if(!isdigit(symbol->lexeme[i]))
symbol->token = other;
}
memcpy(&token, &symbol->token, sizeof(Token));
/* Insert the symbol into the symbol table. */
if((retval = chtbl_insert(symtbl, symbol)) < 0)
{
free(symbol);
return error;
}
else if(retval == 1)
{
/* The symbol is already in the symbol table. */
free(symbol);
}
}
/* Return the token for the parser. */
return token;
}注:上述代码仅供理解,无法运行。
5、开地址哈希表的描述
在链式哈希表中,元素存放在每个地址的"桶"中。而在开地址哈希表中,元素存放在表本身中。这种特性对于某些依赖于固定大小表的应用来说非常有用。然而,因为在每个槽位上没有一个"桶"来存储冲突元素,所以开地址哈希表需要通过另一种方法来解决冲突。
冲突解决
鉴于链式哈希表自身就有能够解决冲突的机制,开地址哈希表必须以一种不同的方式来解决冲突。在开地址哈希表中解决冲突的方法就是探查这个表,直到找到一个可以放置元素的槽。例如,如果要插入一个元素,我们探查槽位直到找到一个空槽,然后将元素插入到此槽中。如果要删除或者找一个元素,我们探查槽位直到定位到该元素或直到找到一个空槽。如果在找到元素之前找到一个空槽或遍历完所有槽位,那么说明此元素在表中不存在。
当然,在进行操作时要尽可能地减少探查的次数。究竟进行过多少次探查后就停止探查主要取决于两件事:哈希表的负载因子和元素均匀分布的程度。回想一下,哈希表的负载因子α=n/m,其中n为元素的个数,m为可以散列元素的槽位的个数。要注意,根据开地址哈希表的定义,它所包含的元素不可能大于表中槽位的数量,所以开地址哈希表的负载因子通常小于或等于1。这是显而易见的,因为每个槽至多能够容纳一个元素。
假设进行均匀散列,我们能够在一个开地址哈希表中探查的槽位个数是:
1/(1-α)
例如,对于一个处于半满状态的开地址哈希表来说(负载系数为0.5),我们期望能够探查的槽位个数为1/(1-0.5)=2。下表显示了当哈希表的负载因子趋近于1(或100%,即表完全满)时,我们期望探查的槽位数量如何显著增大的。在一个对时间特别敏感的应用中,就可以通过增加哈希表的空间来提高探查的效率。
假设是均匀散列,期望探查次数变化随负载因子变化的规律 负载因子(%) 期望探查次数 <50 <1/(1-0.50)=2 80 1/(1-0.80)=5 90 1/(1-0.90)=10 95 1/(1-0.95)=20
哈希表的性能是否能够接近于表中所述的规律取决于我们是否能够近似均匀散列。与链式哈希表一样,这关键取决于如何选择哈希函数。然而,在一个开地址哈希表中,这也取决于当发生冲突时如何探查后续表的槽位。一般来说,在开地址哈希表中探查槽位的哈希函数定义为:
h(k, i)=x
其中,k是键,i是到目前为止探查的次数,x是得到的哈希编码。通常情况下,与链式哈希表一样,h会调用一个或多个具有相同属性的辅助哈希函数。但在开地址哈希表中,h必须具有一个额外的哈希属性:当i从0增加到m-1时(m为哈希表中槽位个数),在第二次访问任何槽位之前,表中所有的槽位都必须访问过一遍;否则,就说明不需要探查所有的槽位就能找到结果。
线性探查
开地址哈希表中一种简单的探查方法就是探查表中连续的槽位。正式地表述为,如果i大于0小于m-1(m为表中的槽位个数),那么一个线性探查方法的哈希函数定义为:
h(k, i)=(h'(k) + i) mod m
函数h'是一个辅助哈希函数,就像任何哈希函数的选择方法一样,它会尽可能地将元素随机和均匀地分布在表中。例如,可以采用取余法,这样h'(k)=k mod m。在这种情况下,如果将一个元素(键k=2998)散列到表(容量m=1000),所得到的哈希编码为(998+0) mod 1000 = 988(当i=0时),(998+1) mod 1000 = 999(当i=1时),(998+2) mod 1000 = 0(当i=2时),依此类推。所以,当要插入一个键k=2998的元素时,我们会寻找一个空的槽位,首先探查槽位998,然后槽位999,然后槽位0,依此类推。
线性探查的优点就是简单,可以保证所有的槽位最终都可能探查到。遗憾的是,线性探查并不能近似均匀散列。特别是当遇到一种称为基本聚集的情况时,基本聚集会产生很长的探查序列,从而使表变得越来越大。这种过度的探查会降低表的性能(见下图)。

双散列
最有效地探查开地址哈希表的方法之一,就是通过计算两个辅助哈希函数哈希编码的和来得到哈希编码。正式地表述为,如果i的大小在0和m之间(m为表中槽位个数),双散列的哈希函数定义为:
h(k, i) = (h1(k) + i*h2(k)) mod m
函数h1和h2是两个辅助哈希函数,它们与其他的哈希函数一样,也会尽可能地将元素随机和均匀散列到表中。然而,为了保证第二次访问任何一个槽之前其他所有槽都访问过了,我们必须遵循如下规则:一种方法是,m必须是2次幂,让h2返回一个奇数值;另一种方法是选择m为一个素数,h2返回的值在1≤h2(k)≤m-1之间。
通常情况下,令h1(k)=k mod m,h2(k)=1+(k mod m'),其中m'略小于m,类似等于m-1或m-2。例如,用这种方法,如果哈希表槽位数m=1699(一个素数),取m'=m-2=1697,要散列的键k=15385,探查到的槽位为(94+0×113) mod 1699 = 94(当i=0时),以及之后的每隔113个位置的槽位(随着i的增加)。
双散列的优点是,它能够在表中探查并产生较好的元素分布(见下图)。其缺点是,必须限制m的值,这样才能保证在一系列探查中访问表中所有槽之后才会再次探查任何槽。

6、开地址哈希函数的接口定义
ohtbl_init
——————
int ohtbl_init(OHTbl *htbl, int positions, int (*h1)(const void *key), int (*h2)(const void *key), int (*match)(const void *key1, const void *key2), void (*destroy)(void *data));
返回值:如果哈希表初始化成功,返回0;否则返回-1。
描述:初始化开地址哈希表htbl。在对哈希表进行其他操作之前必须首先调用初始化函数。表中槽位的个数将由positions指定。函数指针h1和h2用来指定用户定义的辅助哈希函数来完成双散列的过程。函数指针match指向一个用户定义的函数,此函数用于判断两个键是否匹配,其使用方法和chtbl_init中的match类似。参数destroy是一个函数指针,通过在ohtbl_destroy中调用destroy指定的函数来释放动态分配的内存空间,同样,它与chtbl_destroy中参数的使用方法类似。如果哈希表中的数据不需要释放,那么destroy应该指向NULL。
复杂度:O(m),m是哈希表中槽的个数。
ohtbl_destroy
——————
void ohtbl_destroy(OHTbl *htbl);
返回值:无
描述:销毁htbl指定的开地址哈希表。在调用ohtbl_destroy之后不再允许进行其他操作,除非再次调用ohtbl_init。ohtbl_destroy会删除哈希表中的所有元素,并当ohtbl_init中参数destroy不为NULL时,释放成员所占用的内存空间。
复杂度:O(m),m是哈希表中槽的个数。
ohtbl_insert
——————
int ohtbl_insert(OHTbl *htbl, const void *data);
返回值:如果插入元素成功,返回0;如果哈希表中已经包含此元素,返回1;否则,返回-1。
描述:向htbl指定的开地址哈希表中插入一个元素。新元素包含一个指向data的指针,因此,只要元素仍然存在于哈希表中,此指针就一直有效。与data相关的内存空间将由函数的调用者来管理。
复杂度:O(1)
ohtbl_remove
——————
int ohtbl_remove(OHTbl *htbl, void **data);
返回值:如果删除元素成功,返回0;否则,返回-1。
描述:从ohtbl指定的开地址哈希表中删除与data匹配的元素。返回时,data指向已删除元素中存储的数据。与data相关的内存空间将由函数的调用者来管理。
复杂度:O(1)
ohtbl_lookup
——————
int ohtbl_lookup(const OHTbl *htbl, void **data);
返回值:如果在表中找到元素,返回0;否则,返回-1。
描述:查找htbl指定的开地址哈希表中是否有与data相匹配的元素。如果找到,在函数返回时,data将指向哈希表中相匹配元素的数据。
复杂度:O(1)
ohtbl_size
——————
int ohtbl_size(const OHTbl *htbl);
返回值:哈希表中元素的个数。
描述:获取哈希表元素个数的宏。
复杂度:O(1)
7、开地址哈希表的实现与分析
一个开地址哈希表从本质上来说是由一个数组构成的。结构OHTbl是开地址哈希表的数据结构。这个结构包含8个成员:positions指明哈希表中分配的槽位数目;指针vacated将被初始化为指向一个特殊的地址空间,来指明这个特殊地址上曾经删除一个元素;h1、h2、match、destroy时打包传入ohtbl_init的函数指针;size指明表中现有元素的数量;table是存储元素的数组。
这里需要讨论一下指针vacated。它的存在主要是用来辅助删除元素。一个开地址哈希表的空槽通常包含一个空指针NULL。然而,当删除一个元素时,不能将删除元素的数据指向NULL。这是由于当查找接下来的元素时,NULL表明此槽位是空的,随之探查过程停止。这样一个或多个元素可能被插入之前删除过元素的槽中,但实际上槽中的元素还存在。
考虑到这一点,当删除元素时,将哈希表中数据的指针指向vacated成员。vacated的地址就像一个哨兵,用于指明新元素将要插入的槽位。这样当寻找一个元素时,就可以放心地认为NULL意味着停止探查。
// 开地址哈希表的头文件
/* ohtbl.h */
#ifndef OHTBL_H
#define OHTBL_H
#include <stdlib.h>
/* Define a structure for open-addressed hash tables. */
typedef struct OHTbl_
{
int positions;
void *vacated;
int (*h1)(const void *key);
int (*h2)(const void *key);
int (*match)(const void *key1, const void *key2);
void (*destroy)(void *data);
int size;
void **table;
} OHTbl;
/* Public Interface */
int ohtbl_init(OHTbl *htbl, int positions, int (*h1)(const void *key), int (*h2)(const void *key), int (*match)(const void *key1, const void *key2), void (*destroy)(void *data));
void ohtbl_destroy(OHTbl *htbl);
int ohtbl_insert(OHTbl *htbl, const void *data);
int ohtbl_remove(OHTbl *htbl, void **data);
int ohtbl_lookup(const OHTbl *htbl, void **data);
#define ohtbl_size(htbl) ((htbl)->size)
#endif // OHTBL_H
// 开地址哈希表抽象数据类型的实现
/* ohtbl.c */
#include <stdlib.h>
#include <string.h>
#include "ohtbl.h"
/* Reserve a sentinel memory address for vacated elements. */
static char vacated;
/* ohtbl_init */
int ohtbl_init(OHTbl *htbl, int positions, int (*h1)(const void *key), int (*h2)(const void *key), int (*match)(const void *key1, const void *key2), void (*destroy)(void *data))
{
int i;
/* Allocate space for the hash table. */
if((htbl->table = (void **)malloc(positions * sizeof(void *))) == NULL)
return -1;
/* Initialize each position. */
htbl->positions = positions;
for(i = 0; i < htbl->positions; i++)
htbl->table[i] = NULL;
/* Set the vacated member to the sentinel memory address reserved for this. */
htbl->vacated = vacated;
/* Encapsulate the functions. */
htbl->h1 = h1;
htbl->h2 = h2;
htbl->match = match;
htbl->destroy = destroy;
/* Initialize the number of elements in the table. */
htbl->size = 0;
return 0;
}
/* ohtbl_destroy */
void ohtbl_destroy(OHTbl *htbl)
{
int i;
if(htbl->destroy != NULL)
{
/* Call a user-defined function to free dynamically allocated data. */
for(i = 0; i < htbl->positions; i++)
{
if(htbl->table[i] != NULL && htbl->table[i] != htbl->vacated)
htbl->destroy(htbl->table[i]);
}
}
/* Free the storage allocated for the hash table. */
free(htbl->table);
/* No operations are allowed now, but clear the structure as a precaution. */
memset(htbl, 0, sizeof(OHTbl));
return;
}
/* ohtbl_insert */
int ohtbl_insert(OHTbl *htbl, const void *data)
{
void *temp;
int position, i;
/* Do not exceed the number of positions in the table. */
if(htbl->size == htbl->positions)
return -1;
/* Do nothing if the data is already in the table. */
temp = (void *)data;
if(ohtbl_lookup(htbl, &temp) == 0)
return 1;
/* Use double hashing to hash the key. */
for(i = 0; i < htbl->positions; i++)
{
position = (htbl->h1(data) + (i * htbl->h2(data))) % htbl->positions;
if(htbl->table[position] == NULL || htbl->table[position] == htbl->vacated)
{
/* Insert the data into the table. */
htbl->table[position] = (void *)data;
htbl->size++;
return 0;
}
}
/* Return that the hash functions were selected incorrectly. */
return -1;
}
/* ohtbl_remove */
int ohtbl_remove(OHTbl *htbl, void **data)
{
int position, i;
/* Use double hashing to hash the key. */
for(i = 0; i < htbl->positions; i++)
{
position = (htbl->h1(*data) + (i * htbl->h2(*data))) % htbl->positions;
if(htbl->table[position] == NULL)
{
/* Return that the data was not found. */
return -1;
}
else if(htbl->table[position] == htbl->vacated)
{
/* Search beyond vacated positions. */
continue;
}
else if(htbl->match(htbl->table[position], *data))
{
/* Pass back the data from the table. */
*data = htbl->table[position];
htbl->table[position] = htbl->vacated;
htbl->size--;
return 0;
}
}
/* Return that the data was not found. */
return -1;
}
/* ohtbl_lookup */
int ohtbl_lookup(const OHTbl *htbl, void **data)
{
int position, i;
/* Use double hashing to hash the key. */
for(i = 0; i < htbl->positions; i++)
{
position = (htbl->h1(*data) + (i * htbl->h2(*data))) % htbl->positions;
if(htbl->table[position] == NULL)
{
/* Return that the data was not found. */
return -1;
}
else if(htbl->match(htbl->table[position], *data))
{
/* Pass back the data from the table. */
*data = htbl->table[position];
return 0;
}
}
/* Return that the data was not found. */
return -1;
}
ohtbl_init
开地址哈希表由ohtbl_init初始化,经过初始化的哈希表才能进行其他操作。开地址哈希表的初始化过程比较简单,其中包括:为表分配空间;将每个槽的指针设置为NULL;封装h1、h2、match和destroy函数;初始化vacated,将它指向标志位地址;最后将size值置0。
ohtbl_init的时间复杂度为O(m),其中m是表中槽的个数。这是由于m个指向槽中数据的指针都必须初始化为NULL。而剩下的初始化操作都能在固定时间内完成。
ohtbl_destroy
开地址哈希表由ohtbl_destroy进行销毁。该函数的主要功能是释放由ohtbl_init分配的内存空间。如果传递给函数ohtbl_init的参数destroy不为NULL的话,每当移除一个元素时,都要调用一次由destroy所指向的析构函数。
ohtbl_destroy的时间复杂度为O(m),其中m是表中槽的个数。这是由于我们必须遍历哈希表中的所有的槽来判定哪个槽已占用。如果destroy指向NULL,那么ohtbl_destroy的复杂度为O(1)。
ohtbl_insert
开地址哈希表由ohtbl_insert向表中插入元素。因为开地址哈希表有固定的大小,所以在插入新元素之前必须保证有足够的空间来放置元素。而且,因为有相同的键不允许重复插入表中,所以在插入新元素时调用ohtbl_lookup来确保表中没有相同的元素存在。
一旦以上条件得到满足,就可以通过双散列法在表中寻找未占用的槽。如果一个槽的数据指向NULL或槽地址在vacated中(vacated是哈希表中特殊的数据结构,用来记录曾经删除过元素的槽地址),那么说明此槽是一个空槽。一旦在表中找到一个空槽,就将槽的指针指向待插入的数据。如果整个插入过程成功,就将表的容量增大。
考虑到我们尽量遵从了均匀散列的方法,而且哈希表的负载因子相对较小,ohtbl_insert的时间复杂度为O(1)。这是因为,为了找到一个能够插入元素的空槽,我们可能会探查1/(1-α)个槽,这是一个很小的常量。其中,α是哈希表的负载因子。
ohtbl_remove
开地址哈希表通过ohtbl_remove删除表中的元素。为了删除元素,我们像在ohtbl_insert中一样通过双散列法来定位要删除的元素,直到找到这个元素或查找到NULL。如果找到元素,将data指向正在删除的数据,然后将表的大小减1。同时,将槽在哈希表中的地址放到数据结构vacated中。
考虑到我们尽量遵从了均匀散列的方法,ohtbl_remove的时间复杂度为O(1)。这是因为,为了找到删除元素的槽位,我们会探查1/(1-α)个槽(其中α是自从调用ohtbl_init以来哈希表的最大负载因子),这个常数值很小。为什么删除操作的性能由最大负载因子决定,而且不会随着删除元素而减少,是因为我们仍然会去探查曾经删除过元素的槽。
ohtbl_lookup
开地址哈希表通过ohtbl_lookup查找元素,并返回一个指向查找到的数据的指针。此操作与ohtbl_remove非常类似,只是在查找到元素后它不会执行删除操作。
考虑到我们尽量遵从了均匀散列的方法,ohtbl_lookup的时间复杂度为O(1)。其原因与ohtbl_remove操作相同。这是因为我们希望探查1/(1-α)个槽位,这是一个很小的常数,其中α是自从调用ohtbl_init以来哈希表的最大负载因子。性能依赖于最大负载因子的原因同ohtbl_remove中一样。
ohtbl_size
获取开地址哈希表的元素数量的宏定义。它通过结构OHTbl的成员size来获取元素个数。
其时间复杂度为O(1)。因为获取过程是一个常量级别运算过程。














 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









