







一、GeoHash特点
首先,GeoHash用一个字符串表示经度和纬度两个坐标。某些情况下无法在两列上同时应用索引(例如MySQL 4之前的版本,Google App Engine的数据层等),利用GeoHash。只需要在一列上应用索引即可。
其次,GeoHash表示的并不是一个点,而是一个矩形区域。比如编码wx4g0ec19,它表示的是一个矩形区域。使用者可以发布地址编码,既能表明自己位于北海公园附近,又不至于暴露自己的精确坐标,有助于隐私保护。
第三,编码的前缀可以表示更大的区域。例如,wx4g0ec1,它的前缀wx4g0e表示包含编码wx4g0ec1在内的更大范围。这个特性可以用于附近地点搜索。首先根据用户当前坐标计算GeoHash(例如wx4g0ec1),然后取其前缀进行查询(SELECT * FROM place WHERE geohash LIKE 'wx4g0e%'),即可查询附近的所有地点。
GeoHash比直接用经纬度的高效很多。
二、GeoHash的原理
GeoHash的最简单的解释就是:将一个经纬度信息,转换成一个可以排序,可以比较的字符串编码。
首先将纬度范围(-90, 90)平分成两个区间(-90, 0)和(0, 90),如果目标维度位于前一个区间,则编码为0,否则编码为1。
由于39.92324属于(0, 90),所以取编码为1。
然后再将(0, 90)分成(0, 45)和(45, 90)两个区间,而39.92324位于(0, 45),所以编码为0。
以此类推,直到精度符合要求为止,得到纬度编码为1011 1000 1100 0111 1001。
| 纬度范围 | 划分区间0 | 划分区间1 | 39.92324所属区间 |
| (-90, 90) | (-90, 0.0) | (0.0, 90) | 1 |
| (0.0, 90) | (0.0, 45.0) | (45.0, 90) | 0 |
| (0.0, 45.0) | (0.0, 22.5) | (22.5, 45.0) | 1 |
| (22.5, 45.0) | (22.5, 33.75) | (33.75, 45.0) | 1 |
| (33.75, 45.0) | (33.75, 39.375) | (39.375, 45.0) | 1 |
| (39.375, 45.0) | (39.375, 42.1875) | (42.1875, 45.0) | 0 |
| (39.375, 42.1875) | (39.375, 40.7812) | (40.7812, 42.1875) | 0 |
| (39.375, 40.7812) | (39.375, 40.0781) | (40.0781, 40.7812) | 0 |
| (39.375, 40.0781) | (39.375, 39.7265) | (39.7265, 40.0781) | 1 |
| (39.7265, 40.0781) | (39.7265, 39.9023) | (39.9023, 40.0781) | 1 |
| (39.9023, 40.0781) | (39.9023, 39.9902) | (39.9902, 40.0781) | 0 |
| (39.9023, 39.9902) | (39.9023, 39.9462) | (39.9462, 39.9902) | 0 |
| (39.9023, 39.9462) | (39.9023, 39.9243) | (39.9243, 39.9462) | 0 |
| (39.9023, 39.9243) | (39.9023, 39.9133) | (39.9133, 39.9243) | 1 |
| (39.9133, 39.9243) | (39.9133, 39.9188) | (39.9188, 39.9243) | 1 |
| (39.9188, 39.9243) | (39.9188, 39.9215) | (39.9215, 39.9243) | 1 |
| 经度范围 | 划分区间0 | 划分区间1 | 116.3906所属区间 |
| (-180, 180) | (-180, 0.0) | (0.0, 180) | 1 |
| (0.0, 180) | (0.0, 90.0) | (90.0, 180) | 1 |
| (90.0, 180) | (90.0, 135.0) | (135.0, 180) | 0 |
| (90.0, 135.0) | (90.0, 112.5) | (112.5, 135.0) | 1 |
| (112.5, 135.0) | (112.5, 123.75) | (123.75, 135.0) | 0 |
| (112.5, 123.75) | (112.5, 118.125) | (118.125, 123.75) | 0 |
| (112.5, 118.125) | (112.5, 115.312) | (115.312, 118.125) | 1 |
| (115.312, 118.125) | (115.312, 116.718) | (116.718, 118.125) | 0 |
| (115.312, 116.718) | (115.312, 116.015) | (116.015, 116.718) | 1 |
| (116.015, 116.718) | (116.015, 116.367) | (116.367, 116.718) | 1 |
| (116.367, 116.718) | (116.367, 116.542) | (116.542, 116.718) | 0 |
| (116.367, 116.542) | (116.367, 116.455) | (116.455, 116.542) | 0 |
| (116.367, 116.455) | (116.367, 116.411) | (116.411, 116.455) | 0 |
| (116.367, 116.411) | (116.367, 116.389) | (116.389, 116.411) | 1 |
| (116.389, 116.411) | (116.389, 116.400) | (116.400, 116.411) | 0 |
| (116.389, 116.400) | (116.389, 116.394) | (116.394, 116.400) | 0 |
最后,用0-9、b-z(去掉a, i, l, o)这32个字符进行base32编码,得到(39.92324, 116.3906)的编码为wx4g0ec1。
| 十进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| base32 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g |
| 十进制 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| base32 | h | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
三、实现代码(Java)
package al.geohash;
import java.util.BitSet;
import java.util.HashMap;
public class GeoHash {
private static int numbits = 6 * 5;
final static char[] digits = {'0', '1', '2', '3', '4', '5', '6', '7',
'8', '9', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'j', 'k', 'm', 'n', 'p', 'q', 'r',
's', 't', 'u', 'v', 'w', 'x', 'y', 'z'};
final static HashMap<Character, Integer> lookup = new HashMap<Character, Integer>();
static {
int i = 0;
for(char c : digits)
lookup.put(c, i++);
}
public double[] decode(String geoHash) {
StringBuilder buffer = new StringBuilder();
for(char c : geoHash.toCharArray()) {
int i = lookup.get(c) + 32;
buffer.append(Integer.toString(i, 2).substring(1));
}
BitSet lonset = new BitSet();
BitSet latset = new BitSet();
// even bits
int j = 0;
for(int i = 0; i < numbits*2; i += 2) {
boolean isSet = false;
if(i < buffer.length())
isSet = buffer.charAt(i) == '1';
lonset.set(j++, isSet);
}
// odd bits
j = 0;
for(int i = 1; i < numbits*2; i += 2) {
boolean isSet = false;
if(i < buffer.length())
isSet = buffer.charAt(i) == '1';
latset.set(j++, isSet);
}
double lon = decode(lonset, -180, 180);
double lat = decode(latset, -90, 90);
return new double[] {lat, lon};
}
private double decode(BitSet bs, double floor, double ceiling) {
double mid = 0;
for(int i = 0; i < bs.length(); i++) {
mid = (floor + ceiling) / 2;
if(bs.get(i))
floor = mid;
else
ceiling = mid;
}
return mid;
}
public String encode(double lat, double lon) {
BitSet latbits = getBits(lat, -90, 90);
BitSet lonbits = getBits(lon, -180, 180);
StringBuilder buffer = new StringBuilder();
for(int i = 0; i < numbits; i++) {
buffer.append(lonbits.get(i) ? '1' : '0');
buffer.append(latbits.get(i) ? '1' : '0');
}
return base32(Long.parseLong(buffer.toString(), 2));
}
private BitSet getBits(double d, double floor, double ceiling) {
BitSet buffer = new BitSet(numbits);
for(int i = 0; i < numbits; i++) {
double mid = (floor + ceiling) / 2;
if(d >= mid) {
buffer.set(i);
floor = mid;
} else {
ceiling = mid;
}
}
return buffer;
}
private static String base32(long i) {
char[] buf = new char[65];
int charPos = 64;
boolean negative = (i < 0);
if(!negative)
i = -i;
while(i <= -32) {
buf[charPos--] = digits[(int) (-(i % 32))];
i /= 32;
}
buf[charPos] = digits[(int) (-i)];
if(negative)
buf[--charPos] = '-';
return new String(buf, charPos, (65 - charPos));
}
public static void main(String[] args) {
System.out.println(new GeoHash().encode(39.92324, 116.3906));
//输出:wx4g0ec19x3d
}
}
四、观点讨论
上文讲解了GeoHash的计算步骤,还是非常简单的。但是为什么分别对经纬度细分并编码就可以找到附近的点呢?下来我们尝试说明一下。
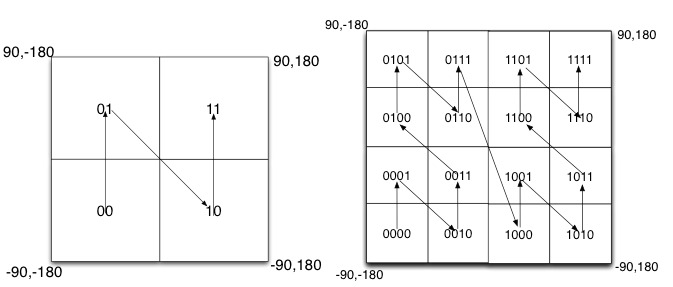
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下角10,右上角11,也就是类似于竖放的Z字曲线,当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子块也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离相近,但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
五、使用注意点
1)由于GeoHash是将区域划分为一个个规则矩形,并对每个矩形进行编码,这样在查询附近POI信息时会导致以下问题,比如红色的点是我们的位置,绿色的两个点分别是附近的两个餐馆,但是在查询的时候会发现距离较远餐馆的GeoHash编码与我们一样(因为在同一个GeoHash区域块上),而较近餐馆的GeoHash编码与我们不一致。这个问题往往产生在边界处。
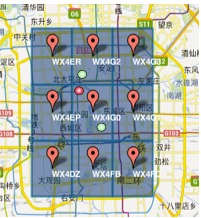
解决的思路很简单,我们查询时,除了使用定位点的GeoHash编码进行匹配外,还使用周围8个区域的GeoHash编码,这样可以避免这个问题。
2)我们已经知道了现有的GeoHash算法使用的是Peano空间填充线,这种曲线会产生突变,造成了编码虽然相似但距离可能相差很大的问题,因此在查询附近餐馆的时候,首先筛选GeoHash编码相似的POI点,然后进行实际距离计算。
六、参考
http://blog.jobbole.com/80633
http://http://www.cnblogs.com/dengxinglin/archive/2012/12/14/2817761.html















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









