







近日,Hai Liang Wang 和胡小夕在 GitHub 开放了一个中文近义词工具包 Synonyms,它可用于如文本对齐、推荐算法、相似度计算、语义偏移、关键字提取、概念提取、自动摘要、搜索引擎等很多 NLP 任务。该工具包目前能搜索近义词和比较语句相似度等任务,且词汇量达到了 125,792。机器之心也尝试使用 Synonyms 搜索一段中文的近义词,并有非常不错的反馈。
项目地址:https://github.com/huyingxi/Synonyms
该中文近义词工具包采用的基本技术是 Word2vec,因此在介绍该工具的同时我们会简要介绍词嵌入方法。此外,Synonyms 的安装十分便捷,我们可以直接使用命令 pip install -U synonyms 完成。该工具包兼容 Python 2 和 Python 3,且目前的稳定版为 v2.0,以下是使用 Synonyms 工具的效果:
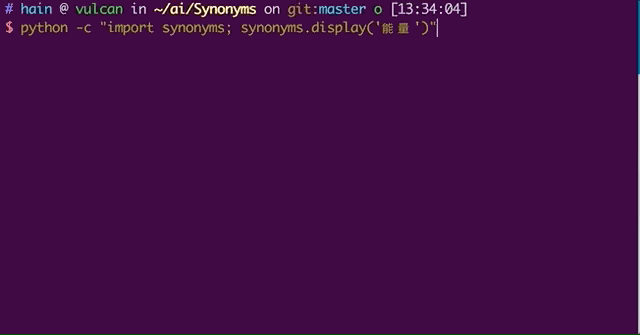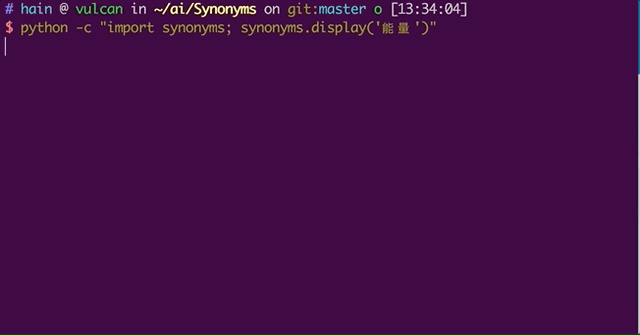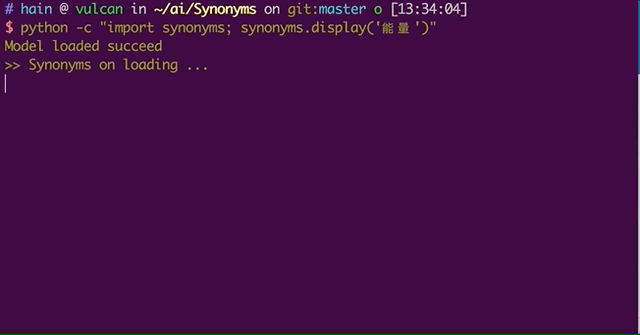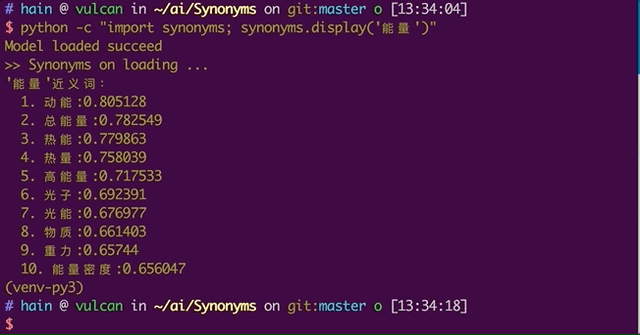
如果我们想把单词输入机器学习模型,除非使用基于树的方法,否则需要把单词转换成一些数值向量。一种直接的方法是使用「one-hot encoding」方法将单词转换为稀疏表示,如下所示向量中只有一个元素设置为 1,其余为 0。

这种方法的缺点在于一个词的向量长度等于词汇表的大小,且非常稀疏。不仅如此,这种方法剥离了单词的所有局部语境,我们不能通过向量表示这个词的概念。因此,我们需要使用更高效的方法表示文本数据,而这种方法可以保存单词的上下文的信息。这是 Word2Vec 方法的初衷。
一般来说,Word2Vec 方法由两部分组成。首先是将高维 one-hot 形式表示的单词映射成低维向量。例如将 10,000 列的矩阵转换为 300 列的矩阵,这一过程被称为词嵌入。第二个目标是在保留单词上下文的同时,从一定程度上保留其意义。Word2Vec 实现这两个目标的方法有 skip-gram 和 CBOW 等,skip-gram 会输入一个词,然后尝试估计其它词出现在该词附近的概率。还有一种与此相反的被称为连续词袋模型(Continuous Bag Of Words,CBOW),它将一些上下文词语作为输入,并通过评估概率找出最适合(概率最大)该上下文的词。
对于连续词袋模型而言,Mikolov 等人运用目标词前面和后面的 n 个词来同时预测这个词。他们称这个模型为连续的词袋(CBOW),因为它用连续空间来表示词,而且这些词的先后顺序并不重要。

连续的词袋(Mikolov 等人,2013 年)
CBOW 可以看作一个具有先知的语言模型,而 skip-gram 模型则完全改变将语言模型的目标:它不像 CBOW 一样从周围的词预测中间的词;恰恰相反,它用中心语去预测周围的词:

Skip-gram(Mikolov 等人,2013)
在加载 Synonyms 中,我们可以看到会打印出「loaded (125796, 100) matrix from...」,因此 Synonyms 采用的词向量维度为 100。
用法
输出近义词向量:
import synonyms
print("人脸: %s" % (synonyms.nearby("人脸")))
print("识别: %s" % (synonyms.nearby("识别")))
print("NOT_EXIST: %s" % (synonyms.nearby("NOT_EXIST")))
synonyms.nearby(WORD) 会返回一个包含两项的列表:
[[nearby_words], [nearby_words_score]],nearby_words 是 WORD 的近义词向量,也以列表的方式存储,并且按照距离的长度由近及远排列,nearby_words_score 是 nearby_words 中对应词的距离分数,分数在 (0-1) 区间内,越接近于 1,代表越相近。比如:
synonyms.nearby(人脸) = [
["图片", "图像", "通过观察", "数字图像", "几何图形", "脸部", "图象", "放大镜", "面孔", "Mii"],
[0.597284, 0.580373, 0.568486, 0.535674, 0.531835, 0.530
095, 0.525344, 0.524009, 0.523101, 0.516046]]
在出现集外词的情况下,返回 [[], []],目前的字典大小: 125,792。
机器之心尝试将一整段关于 Word2vec 的中文分割为一个个单词,再使用 Synonyms 工具对分词的结果取近义词,以下是试验结果:
Word2Vec : [[], []]
方法 : [['方式', '手段', '新方法', '原理', '工具', '步骤', '算法', '分析方法', '演算法', '方法有'], [0.770168, 0.698663, 0.696657, 0.693642, 0.690686, 0.687199, 0.675024, 0.673502, 0.657432, 0.656965]]
由 : [[], []]
两 : [[], []]
部分 : [['部份', '大部分', '一小', '其余部分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3771
3771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









