







HashMap
HashMap概述
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
HashMap数据结构
java.lang.Object
↳ java.util.AbstractMap<K, V>
↳ java.util.HashMap<K, V>
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable { }
从图中可以看出:
1. HashMap继承于AbstractMap类,实现了Map接口。Map是”key-value键值对”接口,AbstractMap实现了”键值对”的通用函数接口。
2. HashMap是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值=”容量*加载因子”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的。
fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件(http://www.cnblogs.com/skywang12345/p/3308762.html)
HashMap的构造函数
HashMap共有4个构造函数
// 默认构造函数。
HashMap()
// 指定“容量大小”的构造函数
HashMap(int capacity)
// 指定“容量大小”和“加载因子”的构造函数
HashMap(int capacity, float loadFactor)
// 包含“子Map”的构造函数
HashMap(Map<? extends K, ? extends V> map)HashMap的API
void clear()
Object clone()
boolean containsKey(Object key)
boolean containsValue(Object value)
Set<Entry<K, V>> entrySet()
V get(Object key)
boolean isEmpty()
Set<K> keySet()
V put(K key, V value)
void putAll(Map<? extends K, ? extends V> map)
V remove(Object key)
int size()
Collection<V> values()HashMap源码解析
http://www.cnblogs.com/skywang12345/p/3310835.html
为了更了解HashMap的原理,下面对HashMap源码代码作出分析。
在阅读源码时,建议参考后面的说明来建立对HashMap的整体认识,这样更容易理解HashMap
package java.util;
import java.io.*;
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
// 默认的初始容量是16,必须是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 最大容量(必须是2的幂且小于2的30次方,传入容量过大将被这个值替换)
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 存储数据的Entry数组,长度是2的幂。
// HashMap是采用拉链法实现的,每一个Entry本质上是一个单向链表
transient Entry[] table;
// HashMap的大小,它是HashMap保存的键值对的数量
transient int size;
// HashMap的阈值,用于判断是否需要调整HashMap的容量(threshold = 容量*加载因子)
int threshold;
// 加载因子实际大小
final float loadFactor;
// HashMap被改变的次数
transient volatile int modCount;
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// HashMap的最大容量只能是MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 找出“大于initialCapacity”的最小的2的幂
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// 设置“加载因子”
this.loadFactor = loadFactor;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(capacity * loadFactor);
// 创建Entry数组,用来保存数据
table = new Entry[capacity];
init();
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 默认构造函数。
public HashMap() {
// 设置“加载因子”
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// 创建Entry数组,用来保存数据
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
// 包含“子Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 将m中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// 返回索引值
// h & (length-1)保证返回值的小于length
static int indexFor(int h, int length) {
return h & (length-1);
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
// 获取key对应的value
public V get(Object key) {
if (key == null)
return getForNullKey();
// 获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
// 获取“key为null”的元素的值
// HashMap将“key为null”的元素存储在table[0]位置!
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
// HashMap是否包含key
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
// 返回“键为key”的键值对
final Entry<K,V> getEntry(Object key) {
// 获取哈希值
// HashMap将“key为null”的元素存储在table[0]位置,“key不为null”的则调用hash()计算哈希值
int hash = (key == null) ? 0 : hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
addEntry(hash, key, value, i);
return null;
}
// putForNullKey()的作用是将“key为null”键值对添加到table[0]位置
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 这里的完全不会被执行到!
modCount++;
addEntry(0, null, value, 0);
return null;
}
// 创建HashMap对应的“添加方法”,
// 它和put()不同。putForCreate()是内部方法,它被构造函数等调用,用来创建HashMap
// 而put()是对外提供的往HashMap中添加元素的方法。
private void putForCreate(K key, V value) {
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
// 若该HashMap表中存在“键值等于key”的元素,则替换该元素的value值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
e.value = value;
return;
}
}
// 若该HashMap表中不存在“键值等于key”的元素,则将该key-value添加到HashMap中
createEntry(hash, key, value, i);
}
// 将“m”中的全部元素都添加到HashMap中。
// 该方法被内部的构造HashMap的方法所调用。
private void putAllForCreate(Map<? extends K, ? extends V> m) {
// 利用迭代器将元素逐个添加到HashMap中
for (Iterator<? extends Map.Entry<? extends K, ? extends V>> i = m.entrySet().iterator(); i.hasNext(); ) {
Map.Entry<? extends K, ? extends V> e = i.next();
putForCreate(e.getKey(), e.getValue());
}
}
// 重新调整HashMap的大小,newCapacity是调整后的单位
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中,
// 然后,将“新HashMap”赋值给“旧HashMap”。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
// 将HashMap中的全部元素都添加到newTable中
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
// 将"m"的全部元素都添加到HashMap中
public void putAll(Map<? extends K, ? extends V> m) {
// 有效性判断
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
// 计算容量是否足够,
// 若“当前实际容量 < 需要的容量”,则将容量x2。
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
// 通过迭代器,将“m”中的元素逐个添加到HashMap中。
for (Iterator<? extends Map.Entry<? extends K, ? extends V>> i = m.entrySet().iterator(); i.hasNext(); ) {
Map.Entry<? extends K, ? extends V> e = i.next();
put(e.getKey(), e.getValue());
}
}
// 删除“键为key”元素
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
// 删除“键为key”的元素
final Entry<K,V> removeEntryForKey(Object key) {
// 获取哈希值。若key为null,则哈希值为0;否则调用hash()进行计算
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 删除链表中“键为key”的元素
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
// 删除“键值对”
final Entry<K,V> removeMapping(Object o) {
if (!(o instanceof Map.Entry))
return null;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
Object key = entry.getKey();
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 删除链表中的“键值对e”
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
if (e.hash == hash && e.equals(entry)) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
// 清空HashMap,将所有的元素设为null
public void clear() {
modCount++;
Entry[] tab = table;
for (int i = 0; i < tab.length; i++)
tab[i] = null;
size = 0;
}
// 是否包含“值为value”的元素
public boolean containsValue(Object value) {
// 若“value为null”,则调用containsNullValue()查找
if (value == null)
return containsNullValue();
// 若“value不为null”,则查找HashMap中是否有值为value的节点。
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
// 是否包含null值
private boolean containsNullValue() {
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (e.value == null)
return true;
return false;
}
// 克隆一个HashMap,并返回Object对象
public Object clone() {
HashMap<K,V> result = null;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
// assert false;
}
result.table = new Entry[table.length];
result.entrySet = null;
result.modCount = 0;
result.size = 0;
result.init();
// 调用putAllForCreate()将全部元素添加到HashMap中
result.putAllForCreate(this);
return result;
}
// Entry是单向链表。
// 它是 “HashMap链式存储法”对应的链表。
// 它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
// 指向下一个节点
Entry<K,V> next;
final int hash;
// 构造函数。
// 输入参数包括"哈希值(h)", "键(k)", "值(v)", "下一节点(n)"
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断两个Entry是否相等
// 若两个Entry的“key”和“value”都相等,则返回true。
// 否则,返回false
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 实现hashCode()
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
// 当向HashMap中添加元素时,绘调用recordAccess()。
// 这里不做任何处理
void recordAccess(HashMap<K,V> m) {
}
// 当从HashMap中删除元素时,绘调用recordRemoval()。
// 这里不做任何处理
void recordRemoval(HashMap<K,V> m) {
}
}
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}
// 创建Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
// 它和addEntry的区别是:
// (01) addEntry()一般用在 新增Entry可能导致“HashMap的实际容量”超过“阈值”的情况下。
// 例如,我们新建一个HashMap,然后不断通过put()向HashMap中添加元素;
// put()是通过addEntry()新增Entry的。
// 在这种情况下,我们不知道何时“HashMap的实际容量”会超过“阈值”;
// 因此,需要调用addEntry()
// (02) createEntry() 一般用在 新增Entry不会导致“HashMap的实际容量”超过“阈值”的情况下。
// 例如,我们调用HashMap“带有Map”的构造函数,它绘将Map的全部元素添加到HashMap中;
// 但在添加之前,我们已经计算好“HashMap的容量和阈值”。也就是,可以确定“即使将Map中
// 的全部元素添加到HashMap中,都不会超过HashMap的阈值”。
// 此时,调用createEntry()即可。
void createEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
size++;
}
// HashIterator是HashMap迭代器的抽象出来的父类,实现了公共了函数。
// 它包含“key迭代器(KeyIterator)”、“Value迭代器(ValueIterator)”和“Entry迭代器(EntryIterator)”3个子类。
private abstract class HashIterator<E> implements Iterator<E> {
// 下一个元素
Entry<K,V> next;
// expectedModCount用于实现fast-fail机制。
int expectedModCount;
// 当前索引
int index;
// 当前元素
Entry<K,V> current;
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
// 将next指向table中第一个不为null的元素。
// 这里利用了index的初始值为0,从0开始依次向后遍历,直到找到不为null的元素就退出循环。
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
// 获取下一个元素
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
// 注意!!!
// 一个Entry就是一个单向链表
// 若该Entry的下一个节点不为空,就将next指向下一个节点;
// 否则,将next指向下一个链表(也是下一个Entry)的不为null的节点。
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
// 删除当前元素
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}
// value的迭代器
private final class ValueIterator extends HashIterator<V> {
public V next() {
return nextEntry().value;
}
}
// key的迭代器
private final class KeyIterator extends HashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
// Entry的迭代器
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
// 返回一个“key迭代器”
Iterator<K> newKeyIterator() {
return new KeyIterator();
}
// 返回一个“value迭代器”
Iterator<V> newValueIterator() {
return new ValueIterator();
}
// 返回一个“entry迭代器”
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
// HashMap的Entry对应的集合
private transient Set<Map.Entry<K,V>> entrySet = null;
// 返回“key的集合”,实际上返回一个“KeySet对象”
public Set<K> keySet() {
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
// Key对应的集合
// KeySet继承于AbstractSet,说明该集合中没有重复的Key。
private final class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return HashMap.this.removeEntryForKey(o) != null;
}
public void clear() {
HashMap.this.clear();
}
}
// 返回“value集合”,实际上返回的是一个Values对象
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null ? vs : (values = new Values()));
}
// “value集合”
// Values继承于AbstractCollection,不同于“KeySet继承于AbstractSet”,
// Values中的元素能够重复。因为不同的key可以指向相同的value。
private final class Values extends AbstractCollection<V> {
public Iterator<V> iterator() {
return newValueIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
HashMap.this.clear();
}
}
// 返回“HashMap的Entry集合”
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
// 返回“HashMap的Entry集合”,它实际是返回一个EntrySet对象
private Set<Map.Entry<K,V>> entrySet0() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
// EntrySet对应的集合
// EntrySet继承于AbstractSet,说明该集合中没有重复的EntrySet。
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator();
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> e = (Map.Entry<K,V>) o;
Entry<K,V> candidate = getEntry(e.getKey());
return candidate != null && candidate.equals(e);
}
public boolean remove(Object o) {
return removeMapping(o) != null;
}
public int size() {
return size;
}
public void clear() {
HashMap.this.clear();
}
}
// java.io.Serializable的写入函数
// 将HashMap的“总的容量,实际容量,所有的Entry”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws IOException
{
Iterator<Map.Entry<K,V>> i =
(size > 0) ? entrySet0().iterator() : null;
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
// Write out number of buckets
s.writeInt(table.length);
// Write out size (number of Mappings)
s.writeInt(size);
// Write out keys and values (alternating)
if (i != null) {
while (i.hasNext()) {
Map.Entry<K,V> e = i.next();
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
}
}
private static final long serialVersionUID = 362498820763181265L;
// java.io.Serializable的读取函数:根据写入方式读出
// 将HashMap的“总的容量,实际容量,所有的Entry”依次读出
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the threshold, loadfactor, and any hidden stuff
s.defaultReadObject();
// Read in number of buckets and allocate the bucket array;
int numBuckets = s.readInt();
table = new Entry[numBuckets];
init(); // Give subclass a chance to do its thing.
// Read in size (number of Mappings)
int size = s.readInt();
// Read the keys and values, and put the mappings in the HashMap
for (int i=0; i<size; i++) {
K key = (K) s.readObject();
V value = (V) s.readObject();
putForCreate(key, value);
}
}
// 返回“HashMap总的容量”
int capacity() { return table.length; }
// 返回“HashMap的加载因子”
float loadFactor() { return loadFactor; }
}说明:
在详细介绍HashMap的代码之前,我们需要了解:HashMap就是一个散列表,它是通过“拉链法”解决哈希冲突的。
还需要再补充说明的一点是影响HashMap性能的有两个参数:初始容量(initialCapacity) 和加载因子(loadFactor)。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
* HashMap的“拉链法”相关内容*
HashMap数据存储数组
transient Entry[] table;HashMap中的key-value都是存储在Entry数组中的。
数据节点Entry的数据结构
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
// 指向下一个节点
Entry<K,V> next;
final int hash;
// 构造函数。
// 输入参数包括"哈希值(h)", "键(k)", "值(v)", "下一节点(n)"
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断两个Entry是否相等
// 若两个Entry的“key”和“value”都相等,则返回true。
// 否则,返回false
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 实现hashCode()
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
// 当向HashMap中添加元素时,绘调用recordAccess()。
// 这里不做任何处理
void recordAccess(HashMap<K,V> m) {
}
// 当从HashMap中删除元素时,绘调用recordRemoval()。
// 这里不做任何处理
void recordRemoval(HashMap<K,V> m) {
}
}从中,我们可以看出 Entry 实际上就是一个单向链表。这也是为什么我们说HashMap是通过拉链法解决哈希冲突的。
Entry 实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数。这些都是基本的读取/修改key、value值的函数。
HashMap的构造函数
// 默认构造函数。
public HashMap() {
// 设置“加载因子”
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// 创建Entry数组,用来保存数据
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// HashMap的最大容量只能是MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// 设置“加载因子”
this.loadFactor = loadFactor;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(capacity * loadFactor);
// 创建Entry数组,用来保存数据
table = new Entry[capacity];
init();
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 包含“子Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 将m中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}HashMap的遍历
遍历HashMap的键值对
第一步:根据entrySet()获取HashMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
推荐的遍历方式:
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
Integer integ = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}遍历HashMap的键
第一步:根据keySet()获取HashMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
String key = null;
Integer integ = null;
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)map.get(key);
}遍历HashMap的值
第一步:根据value()获取HashMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
Integer value = null;
Collection c = map.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}HashMap示例
public class Test {
public static void main(String[] args) {
testHashMapAPIs();
}
private static void testHashMapAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建HashMap
HashMap<String,Integer> map = new HashMap<String,Integer>();
// 添加操作
map.put("one", r.nextInt(10));
map.put("two", r.nextInt(10));
map.put("three", r.nextInt(10));
// 打印出map
System.out.println("map:"+map );
// 通过Iterator遍历key-value
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
System.out.println("next : "+ entry.getKey() +" - "+entry.getValue());
}
// HashMap的键值对个数
System.out.println("size:"+map.size());
// containsKey(Object key) :是否包含键key
System.out.println("contains key two : "+map.containsKey("two"));
System.out.println("contains key five : "+map.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.println("contains value 0 : "+map.containsValue(Integer.valueOf(0)));
// remove(Object key) : 删除键key对应的键值对
map.remove("three");
System.out.println("map:"+map );
// clear() : 清空HashMap
map.clear();
// isEmpty() : HashMap是否为空
System.out.println((map.isEmpty()?"map is empty":"map is not empty") );
}
}
/*
输出:
map:{two=6, one=5, three=5}
two : 6
one : 5
three : 5
size:3
contains key two : true
contains key five : false
contains value 0 : false
map:{two=6, one=5}
map is empty
*/HashTable
HashTable概述
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。一个类只能继承一个类,可以实现多个接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
* Hashtable数据结构*
Hashtable的继承关系
java.lang.Object
↳ java.util.Dictionary<K, V>
↳ java.util.Hashtable<K, V>
public class Hashtable<K,V> extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { }Hashtable与Map关系如下图:
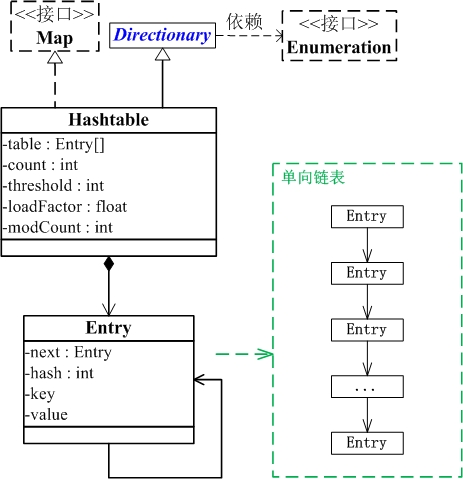
从图中可以看出:
1. Hashtable继承于Dictionary类,实现了Map接口。Map是”key-value键值对”接口,Dictionary是声明了操作”键值对”函数接口的抽象类。
2. Hashtable是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
count是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值=”容量*加载因子”。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
Hashtable的构造函数
// 默认构造函数。
public Hashtable()
// 指定“容量大小”的构造函数
public Hashtable(int initialCapacity)
// 指定“容量大小”和“加载因子”的构造函数
public Hashtable(int initialCapacity, float loadFactor)
// 包含“子Map”的构造函数
public Hashtable(Map<? extends K, ? extends V> t)Hashtable的API
synchronized void clear()
synchronized Object clone()
boolean contains(Object value)
synchronized boolean containsKey(Object key)
synchronized boolean containsValue(Object value)
synchronized Enumeration<V> elements()
synchronized Set<Entry<K, V>> entrySet()
synchronized boolean equals(Object object)
synchronized V get(Object key)
synchronized int hashCode()
synchronized boolean isEmpty()
synchronized Set<K> keySet()
synchronized Enumeration<K> keys()
synchronized V put(K key, V value)
synchronized void putAll(Map<? extends K, ? extends V> map)
synchronized V remove(Object key)
synchronized int size()
synchronized String toString()
synchronized Collection<V> values()Hashtable源码解析(基于JDK1.6.0_45)
http://www.cnblogs.com/skywang12345/p/3310887.html
Hashtable实现的Cloneable接口
Hashtable实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个Hashtable对象并返回。
Hashtable实现的Serializable接口
Hashtable实现java.io.Serializable,分别实现了串行读取、写入功能。
串行写入函数就是将Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中
串行读取函数:根据写入方式读出将Hashtable的“总的容量,实际容量,所有的Entry”依次读出
Hashtable遍历方式
1 遍历Hashtable的键值对
第一步:根据entrySet()获取Hashtable的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
Integer integ = null;
Iterator iter = table.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}2 通过Iterator遍历Hashtable的键
第一步:根据keySet()获取Hashtable的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
String key = null;
Integer integ = null;
Iterator iter = table.keySet().iterator();
while (iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)table.get(key);
}4.3 通过Iterator遍历Hashtable的值
第一步:根据value()获取Hashtable的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
Integer value = null;
Collection c = table.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}4.4 通过Enumeration遍历Hashtable的键
第一步:根据keys()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
4.5 通过Enumeration遍历Hashtable的值
第一步:根据elements()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
Enumeration enu = table.elements();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}Hashtable示例
public class Test {
public static void main(String[] args) {
testHashtableAPIs();
}
private static void testHashtableAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建Hashtable
Hashtable table = new Hashtable();
// 添加操作
table.put("one", r.nextInt(10));
table.put("two", r.nextInt(10));
table.put("three", r.nextInt(10));
// 打印出table
System.out.println("table:"+table );
// 通过Iterator遍历key-value
Iterator iter = table.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
System.out.println( entry.getKey() +" : "+entry.getValue());
}
// Hashtable的键值对个数
System.out.println("size:"+table.size());
// containsKey(Object key) :是否包含键key
System.out.println("contains key two : "+table.containsKey("two"));
System.out.println("contains key five : "+table.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.println("contains value 0 : "+table.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
table.remove("three");
System.out.println("table:"+table );
// clear() : 清空Hashtable
table.clear();
// isEmpty() : Hashtable是否为空
System.out.println((table.isEmpty()?"table is empty":"table is not empty") );
}
}
/*
输出:
table:{two=5, one=6, three=9}
two : 5
one : 6
three : 9
size:3
contains key two : true
contains key five : false
contains value 0 : false
table:{two=5, one=6}
table is empty
*/TreeMap
TreeMap 简介
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
TreeMap数据结构
TreeMap的继承关系
java.lang.Object
↳ java.util.AbstractMap<K, V>
↳ java.util.TreeMap<K, V>
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {}TreeMap与Map关系如下图:
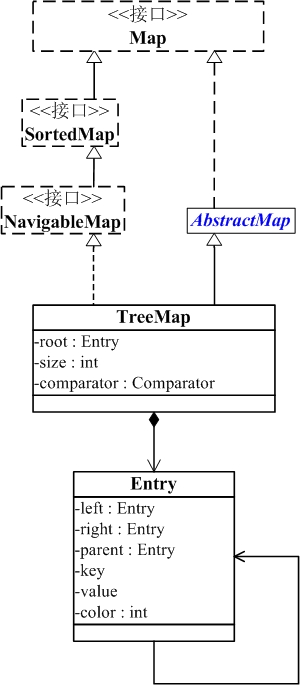
从图中可以看出:
1. TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
2. TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
size是红黑数中节点的个数。
红黑树(一)之 原理和算法详细介绍http://www.cnblogs.com/skywang12345/p/3245399.html
TreeMap的构造函数
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。
TreeMap()
// 创建的TreeMap包含Map
TreeMap(Map<? extends K, ? extends V> copyFrom)
// 指定Tree的比较器
TreeMap(Comparator<? super K> comparator)
// 创建的TreeSet包含copyFrom
TreeMap(SortedMap<K, ? extends V> copyFrom)TreeMap的API
Entry<K, V> ceilingEntry(K key)
K ceilingKey(K key)
void clear()
Object clone()
Comparator<? super K> comparator()
boolean containsKey(Object key)
NavigableSet<K> descendingKeySet()
NavigableMap<K, V> descendingMap()
Set<Entry<K, V>> entrySet()
Entry<K, V> firstEntry()
K firstKey()
Entry<K, V> floorEntry(K key)
K floorKey(K key)
V get(Object key)
NavigableMap<K, V> headMap(K to, boolean inclusive)
SortedMap<K, V> headMap(K toExclusive)
Entry<K, V> higherEntry(K key)
K higherKey(K key)
boolean isEmpty()
Set<K> keySet()
Entry<K, V> lastEntry()
K lastKey()
Entry<K, V> lowerEntry(K key)
K lowerKey(K key)
NavigableSet<K> navigableKeySet()
Entry<K, V> pollFirstEntry()
Entry<K, V> pollLastEntry()
V put(K key, V value)
V remove(Object key)
int size()
SortedMap<K, V> subMap(K fromInclusive, K toExclusive)
NavigableMap<K, V> subMap(K from, boolean fromInclusive, K to, boolean toInclusive)
NavigableMap<K, V> tailMap(K from, boolean inclusive)
SortedMap<K, V> tailMap(K fromInclusive)TreeMap源码解析
为了更了解TreeMap的原理,下面对TreeMap源码代码作出分析。我们先给出源码内容,后面再对源码进行详细说明,当然,源码内容中也包含了详细的代码注释。读者阅读的时候,建议先看后面的说明,先建立一个整体印象;之后再阅读源码。
package java.util;
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
// 比较器。用来给TreeMap排序
private final Comparator<? super K> comparator;
// TreeMap是红黑树实现的,root是红黑书的根节点
private transient Entry<K,V> root = null;
// 红黑树的节点总数
private transient int size = 0;
// 记录红黑树的修改次数
private transient int modCount = 0;
// 默认构造函数
public TreeMap() {
comparator = null;
}
// 带比较器的构造函数
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
// 带Map的构造函数,Map会成为TreeMap的子集
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
// 带SortedMap的构造函数,SortedMap会成为TreeMap的子集
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
public int size() {
return size;
}
// 返回TreeMap中是否保护“键(key)”
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
// 返回TreeMap中是否保护"值(value)"
public boolean containsValue(Object value) {
// getFirstEntry() 是返回红黑树的第一个节点
// successor(e) 是获取节点e的后继节点
for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e))
if (valEquals(value, e.value))
return true;
return false;
}
// 获取“键(key)”对应的“值(value)”
public V get(Object key) {
// 获取“键”为key的节点(p)
Entry<K,V> p = getEntry(key);
// 若节点(p)为null,返回null;否则,返回节点对应的值
return (p==null ? null : p.value);
}
public Comparator<? super K> comparator() {
return comparator;
}
// 获取第一个节点对应的key
public K firstKey() {
return key(getFirstEntry());
}
// 获取最后一个节点对应的key
public K lastKey() {
return key(getLastEntry());
}
// 将map中的全部节点添加到TreeMap中
public void putAll(Map<? extends K, ? extends V> map) {
// 获取map的大小
int mapSize = map.size();
// 如果TreeMap的大小是0,且map的大小不是0,且map是已排序的“key-value对”
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator c = ((SortedMap)map).comparator();
// 如果TreeMap和map的比较器相等;
// 则将map的元素全部拷贝到TreeMap中,然后返回!
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
// 调用AbstractMap中的putAll();
// AbstractMap中的putAll()又会调用到TreeMap的put()
super.putAll(map);
}
// 获取TreeMap中“键”为key的节点
final Entry<K,V> getEntry(Object key) {
// 若“比较器”为null,则通过getEntryUsingComparator()获取“键”为key的节点
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
// 将p设为根节点
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
// 若“p的key” < key,则p=“p的左孩子”
if (cmp < 0)
p = p.left;
// 若“p的key” > key,则p=“p的左孩子”
else if (cmp > 0)
p = p.right;
// 若“p的key” = key,则返回节点p
else
return p;
}
return null;
}
// 获取TreeMap中“键”为key的节点(对应TreeMap的比较器不是null的情况)
final Entry<K,V> getEntryUsingComparator(Object key) {
K k = (K) key;
Comparator<? super K> cpr = comparator;
if (cpr != null) {
// 将p设为根节点
Entry<K,V> p = root;
while (p != null) {
int cmp = cpr.compare(k, p.key);
// 若“p的key” < key,则p=“p的左孩子”
if (cmp < 0)
p = p.left;
// 若“p的key” > key,则p=“p的左孩子”
else if (cmp > 0)
p = p.right;
// 若“p的key” = key,则返回节点p
else
return p;
}
}
return null;
}
// 获取TreeMap中不小于key的最小的节点;
// 若不存在(即TreeMap中所有节点的键都比key大),就返回null
final Entry<K,V> getCeilingEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
// 情况一:若“p的key” > key。
// 若 p 存在左孩子,则设 p=“p的左孩子”;
// 否则,返回p
if (cmp < 0) {
if (p.left != null)
p = p.left;
else
return p;
// 情况二:若“p的key” < key。
} else if (cmp > 0) {
// 若 p 存在右孩子,则设 p=“p的右孩子”
if (p.right != null) {
p = p.right;
} else {
// 若 p 不存在右孩子,则找出 p 的后继节点,并返回
// 注意:这里返回的 “p的后继节点”有2种可能性:第一,null;第二,TreeMap中大于key的最小的节点。
// 理解这一点的核心是,getCeilingEntry是从root开始遍历的。
// 若getCeilingEntry能走到这一步,那么,它之前“已经遍历过的节点的key”都 > key。
// 能理解上面所说的,那么就很容易明白,为什么“p的后继节点”又2种可能性了。
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
// 情况三:若“p的key” = key。
} else
return p;
}
return null;
}
// 获取TreeMap中不大于key的最大的节点;
// 若不存在(即TreeMap中所有节点的键都比key小),就返回null
// getFloorEntry的原理和getCeilingEntry类似,这里不再多说。
final Entry<K,V> getFloorEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp > 0) {
if (p.right != null)
p = p.right;
else
return p;
} else if (cmp < 0) {
if (p.left != null) {
p = p.left;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.left) {
ch = parent;
parent = parent.parent;
}
return parent;
}
} else
return p;
}
return null;
}
// 获取TreeMap中大于key的最小的节点。
// 若不存在,就返回null。
// 请参照getCeilingEntry来对getHigherEntry进行理解。
final Entry<K,V> getHigherEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp < 0) {
if (p.left != null)
p = p.left;
else
return p;
} else {
if (p.right != null) {
p = p.right;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
}
}
return null;
}
// 获取TreeMap中小于key的最大的节点。
// 若不存在,就返回null。
// 请参照getCeilingEntry来对getLowerEntry进行理解。
final Entry<K,V> getLowerEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp > 0) {
if (p.right != null)
p = p.right;
else
return p;
} else {
if (p.left != null) {
p = p.left;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.left) {
ch = parent;
parent = parent.parent;
}
return parent;
}
}
}
return null;
}
// 将“key, value”添加到TreeMap中
// 理解TreeMap的前提是掌握“红黑树”。
// 若理解“红黑树中添加节点”的算法,则很容易理解put。
public V put(K key, V value) {
Entry<K,V> t = root;
// 若红黑树为空,则插入根节点
if (t == null) {
// TBD:
// 5045147: (coll) Adding null to an empty TreeSet should
// throw NullPointerException
//
// compare(key, key); // type check
root = new Entry<K,V>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
// 在二叉树(红黑树是特殊的二叉树)中,找到(key, value)的插入位置。
// 红黑树是以key来进行排序的,所以这里以key来进行查找。
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 新建红黑树的节点(e)
Entry<K,V> e = new Entry<K,V>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 红黑树插入节点后,不再是一颗红黑树;
// 这里通过fixAfterInsertion的处理,来恢复红黑树的特性。
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
// 删除TreeMap中的键为key的节点,并返回节点的值
public V remove(Object key) {
// 找到键为key的节点
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
// 保存节点的值
V oldValue = p.value;
// 删除节点
deleteEntry(p);
return oldValue;
}
// 清空红黑树
public void clear() {
modCount++;
size = 0;
root = null;
}
// 克隆一个TreeMap,并返回Object对象
public Object clone() {
TreeMap<K,V> clone = null;
try {
clone = (TreeMap<K,V>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
// Put clone into "virgin" state (except for comparator)
clone.root = null;
clone.size = 0;
clone.modCount = 0;
clone.entrySet = null;
clone.navigableKeySet = null;
clone.descendingMap = null;
// Initialize clone with our mappings
try {
clone.buildFromSorted(size, entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return clone;
}
// 获取第一个节点(对外接口)。
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
}
// 获取最后一个节点(对外接口)。
public Map.Entry<K,V> lastEntry() {
return exportEntry(getLastEntry());
}
// 获取第一个节点,并将改节点从TreeMap中删除。
public Map.Entry<K,V> pollFirstEntry() {
// 获取第一个节点
Entry<K,V> p = getFirstEntry();
Map.Entry<K,V> result = exportEntry(p);
// 删除第一个节点
if (p != null)
deleteEntry(p);
return result;
}
// 获取最后一个节点,并将改节点从TreeMap中删除。
public Map.Entry<K,V> pollLastEntry() {
// 获取最后一个节点
Entry<K,V> p = getLastEntry();
Map.Entry<K,V> result = exportEntry(p);
// 删除最后一个节点
if (p != null)
deleteEntry(p);
return result;
}
// 返回小于key的最大的键值对,没有的话返回null
public Map.Entry<K,V> lowerEntry(K key) {
return exportEntry(getLowerEntry(key));
}
// 返回小于key的最大的键值对所对应的KEY,没有的话返回null
public K lowerKey(K key) {
return keyOrNull(getLowerEntry(key));
}
// 返回不大于key的最大的键值对,没有的话返回null
public Map.Entry<K,V> floorEntry(K key) {
return exportEntry(getFloorEntry(key));
}
// 返回不大于key的最大的键值对所对应的KEY,没有的话返回null
public K floorKey(K key) {
return keyOrNull(getFloorEntry(key));
}
// 返回不小于key的最小的键值对,没有的话返回null
public Map.Entry<K,V> ceilingEntry(K key) {
return exportEntry(getCeilingEntry(key));
}
// 返回不小于key的最小的键值对所对应的KEY,没有的话返回null
public K ceilingKey(K key) {
return keyOrNull(getCeilingEntry(key));
}
// 返回大于key的最小的键值对,没有的话返回null
public Map.Entry<K,V> higherEntry(K key) {
return exportEntry(getHigherEntry(key));
}
// 返回大于key的最小的键值对所对应的KEY,没有的话返回null
public K higherKey(K key) {
return keyOrNull(getHigherEntry(key));
}
// TreeMap的红黑树节点对应的集合
private transient EntrySet entrySet = null;
// KeySet为KeySet导航类
private transient KeySet<K> navigableKeySet = null;
// descendingMap为键值对的倒序“映射”
private transient NavigableMap<K,V> descendingMap = null;
// 返回TreeMap的“键的集合”
public Set<K> keySet() {
return navigableKeySet();
}
// 获取“可导航”的Key的集合
// 实际上是返回KeySet类的对象。
public NavigableSet<K> navigableKeySet() {
KeySet<K> nks = navigableKeySet;
return (nks != null) ? nks : (navigableKeySet = new KeySet(this));
}
// 返回“TreeMap的值对应的集合”
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null) ? vs : (values = new Values());
}
// 获取TreeMap的Entry的集合,实际上是返回EntrySet类的对象。
public Set<Map.Entry<K,V>> entrySet() {
EntrySet es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet());
}
// 获取TreeMap的降序Map
// 实际上是返回DescendingSubMap类的对象
public NavigableMap<K, V> descendingMap() {
NavigableMap<K, V> km = descendingMap;
return (km != null) ? km :
(descendingMap = new DescendingSubMap(this,
true, null, true,
true, null, true));
}
// 获取TreeMap的子Map
// 范围是从fromKey 到 toKey;fromInclusive是是否包含fromKey的标记,toInclusive是是否包含toKey的标记
public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive) {
return new AscendingSubMap(this,
false, fromKey, fromInclusive,
false, toKey, toInclusive);
}
// 获取“Map的头部”
// 范围从第一个节点 到 toKey, inclusive是是否包含toKey的标记
public NavigableMap<K,V> headMap(K toKey, boolean inclusive) {
return new AscendingSubMap(this,
true, null, true,
false, toKey, inclusive);
}
// 获取“Map的尾部”。
// 范围是从 fromKey 到 最后一个节点,inclusive是是否包含fromKey的标记
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive) {
return new AscendingSubMap(this,
false, fromKey, inclusive,
true, null, true);
}
// 获取“子Map”。
// 范围是从fromKey(包括) 到 toKey(不包括)
public SortedMap<K,V> subMap(K fromKey, K toKey) {
return subMap(fromKey, true, toKey, false);
}
// 获取“Map的头部”。
// 范围从第一个节点 到 toKey(不包括)
public SortedMap<K,V> headMap(K toKey) {
return headMap(toKey, false);
}
// 获取“Map的尾部”。
// 范围是从 fromKey(包括) 到 最后一个节点
public SortedMap<K,V> tailMap(K fromKey) {
return tailMap(fromKey, true);
}
// ”TreeMap的值的集合“对应的类,它集成于AbstractCollection
class Values extends AbstractCollection<V> {
// 返回迭代器
public Iterator<V> iterator() {
return new ValueIterator(getFirstEntry());
}
// 返回个数
public int size() {
return TreeMap.this.size();
}
// "TreeMap的值的集合"中是否包含"对象o"
public boolean contains(Object o) {
return TreeMap.this.containsValue(o);
}
// 删除"TreeMap的值的集合"中的"对象o"
public boolean remove(Object o) {
for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e)) {
if (valEquals(e.getValue(), o)) {
deleteEntry(e);
return true;
}
}
return false;
}
// 清空删除"TreeMap的值的集合"
public void clear() {
TreeMap.this.clear();
}
}
// EntrySet是“TreeMap的所有键值对组成的集合”,
// EntrySet集合的单位是单个“键值对”。
class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator(getFirstEntry());
}
// EntrySet中是否包含“键值对Object”
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
V value = entry.getValue();
Entry<K,V> p = getEntry(entry.getKey());
return p != null && valEquals(p.getValue(), value);
}
// 删除EntrySet中的“键值对Object”
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
V value = entry.getValue();
Entry<K,V> p = getEntry(entry.getKey());
if (p != null && valEquals(p.getValue(), value)) {
deleteEntry(p);
return true;
}
return false;
}
// 返回EntrySet中元素个数
public int size() {
return TreeMap.this.size();
}
// 清空EntrySet
public void clear() {
TreeMap.this.clear();
}
}
// 返回“TreeMap的KEY组成的迭代器(顺序)”
Iterator<K> keyIterator() {
return new KeyIterator(getFirstEntry());
}
// 返回“TreeMap的KEY组成的迭代器(逆序)”
Iterator<K> descendingKeyIterator() {
return new DescendingKeyIterator(getLastEntry());
}
// KeySet是“TreeMap中所有的KEY组成的集合”
// KeySet继承于AbstractSet,而且实现了NavigableSet接口。
static final class KeySet<E> extends AbstractSet<E> implements NavigableSet<E> {
// NavigableMap成员,KeySet是通过NavigableMap实现的
private final NavigableMap<E, Object> m;
KeySet(NavigableMap<E,Object> map) { m = map; }
// 升序迭代器
public Iterator<E> iterator() {
// 若是TreeMap对象,则调用TreeMap的迭代器keyIterator()
// 否则,调用TreeMap子类NavigableSubMap的迭代器keyIterator()
if (m instanceof TreeMap)
return ((TreeMap<E,Object>)m).keyIterator();
else
return (Iterator<E>)(((TreeMap.NavigableSubMap)m).keyIterator());
}
// 降序迭代器
public Iterator<E> descendingIterator() {
// 若是TreeMap对象,则调用TreeMap的迭代器descendingKeyIterator()
// 否则,调用TreeMap子类NavigableSubMap的迭代器descendingKeyIterator()
if (m instanceof TreeMap)
return ((TreeMap<E,Object>)m).descendingKeyIterator();
else
return (Iterator<E>)(((TreeMap.NavigableSubMap)m).descendingKeyIterator());
}
public int size() { return m.size(); }
public boolean isEmpty() { return m.isEmpty(); }
public boolean contains(Object o) { return m.containsKey(o); }
public void clear() { m.clear(); }
public E lower(E e) { return m.lowerKey(e); }
public E floor(E e) { return m.floorKey(e); }
public E ceiling(E e) { return m.ceilingKey(e); }
public E higher(E e) { return m.higherKey(e); }
public E first() { return m.firstKey(); }
public E last() { return m.lastKey(); }
public Comparator<? super E> comparator() { return m.comparator(); }
public E pollFirst() {
Map.Entry<E,Object> e = m.pollFirstEntry();
return e == null? null : e.getKey();
}
public E pollLast() {
Map.Entry<E,Object> e = m.pollLastEntry();
return e == null? null : e.getKey();
}
public boolean remove(Object o) {
int oldSize = size();
m.remove(o);
return size() != oldSize;
}
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new TreeSet<E>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive));
}
public NavigableSet<E> headSet(E toElement, boolean inclusive) {
return new TreeSet<E>(m.headMap(toElement, inclusive));
}
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<E>(m.tailMap(fromElement, inclusive));
}
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
}
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false);
}
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
}
public NavigableSet<E> descendingSet() {
return new TreeSet(m.descendingMap());
}
}
// 它是TreeMap中的一个抽象迭代器,实现了一些通用的接口。
abstract class PrivateEntryIterator<T> implements Iterator<T> {
// 下一个元素
Entry<K,V> next;
// 上一次返回元素
Entry<K,V> lastReturned;
// 期望的修改次数,用于实现fast-fail机制
int expectedModCount;
PrivateEntryIterator(Entry<K,V> first) {
expectedModCount = modCount;
lastReturned = null;
next = first;
}
public final boolean hasNext() {
return next != null;
}
// 获取下一个节点
final Entry<K,V> nextEntry() {
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = successor(e);
lastReturned = e;
return e;
}
// 获取上一个节点
final Entry<K,V> prevEntry() {
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = predecessor(e);
lastReturned = e;
return e;
}
// 删除当前节点
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
// 这里重点强调一下“为什么当lastReturned的左右孩子都不为空时,要将其赋值给next”。
// 目的是为了“删除lastReturned节点之后,next节点指向的仍然是下一个节点”。
// 根据“红黑树”的特性可知:
// 当被删除节点有两个儿子时。那么,首先把“它的后继节点的内容”复制给“该节点的内容”;之后,删除“它的后继节点”。
// 这意味着“当被删除节点有两个儿子时,删除当前节点之后,'新的当前节点'实际上是‘原有的后继节点(即下一个节点)’”。
// 而此时next仍然指向"新的当前节点"。也就是说next是仍然是指向下一个节点;能继续遍历红黑树。
if (lastReturned.left != null && lastReturned.right != null)
next = lastReturned;
deleteEntry(lastReturned);
expectedModCount = modCount;
lastReturned = null;
}
}
// TreeMap的Entry对应的迭代器
final class EntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> {
EntryIterator(Entry<K,V> first) {
super(first);
}
public Map.Entry<K,V> next() {
return nextEntry();
}
}
// TreeMap的Value对应的迭代器
final class ValueIterator extends PrivateEntryIterator<V> {
ValueIterator(Entry<K,V> first) {
super(first);
}
public V next() {
return nextEntry().value;
}
}
// reeMap的KEY组成的迭代器(顺序)
final class KeyIterator extends PrivateEntryIterator<K> {
KeyIterator(Entry<K,V> first) {
super(first);
}
public K next() {
return nextEntry().key;
}
}
// TreeMap的KEY组成的迭代器(逆序)
final class DescendingKeyIterator extends PrivateEntryIterator<K> {
DescendingKeyIterator(Entry<K,V> first) {
super(first);
}
public K next() {
return prevEntry().key;
}
}
// 比较两个对象的大小
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2)
: comparator.compare((K)k1, (K)k2);
}
// 判断两个对象是否相等
final static boolean valEquals(Object o1, Object o2) {
return (o1==null ? o2==null : o1.equals(o2));
}
// 返回“Key-Value键值对”的一个简单拷贝(AbstractMap.SimpleImmutableEntry<K,V>对象)
// 可用来读取“键值对”的值
static <K,V> Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) {
return e == null? null :
new AbstractMap.SimpleImmutableEntry<K,V>(e);
}
// 若“键值对”不为null,则返回KEY;否则,返回null
static <K,V> K keyOrNull(TreeMap.Entry<K,V> e) {
return e == null? null : e.key;
}
// 若“键值对”不为null,则返回KEY;否则,抛出异常
static <K> K key(Entry<K,?> e) {
if (e==null)
throw new NoSuchElementException();
return e.key;
}
// TreeMap的SubMap,它一个抽象类,实现了公共操作。
// 它包括了"(升序)AscendingSubMap"和"(降序)DescendingSubMap"两个子类。
static abstract class NavigableSubMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, java.io.Serializable {
// TreeMap的拷贝
final TreeMap<K,V> m;
// lo是“子Map范围的最小值”,hi是“子Map范围的最大值”;
// loInclusive是“是否包含lo的标记”,hiInclusive是“是否包含hi的标记”
// fromStart是“表示是否从第一个节点开始计算”,
// toEnd是“表示是否计算到最后一个节点 ”
final K lo, hi;
final boolean fromStart, toEnd;
final boolean loInclusive, hiInclusive;
// 构造函数
NavigableSubMap(TreeMap<K,V> m,
boolean fromStart, K lo, boolean loInclusive,
boolean toEnd, K hi, boolean hiInclusive) {
if (!fromStart && !toEnd) {
if (m.compare(lo, hi) > 0)
throw new IllegalArgumentException("fromKey > toKey");
} else {
if (!fromStart) // type check
m.compare(lo, lo);
if (!toEnd)
m.compare(hi, hi);
}
this.m = m;
this.fromStart = fromStart;
this.lo = lo;
this.loInclusive = loInclusive;
this.toEnd = toEnd;
this.hi = hi;
this.hiInclusive = hiInclusive;
}
// 判断key是否太小
final boolean tooLow(Object key) {
// 若该SubMap不包括“起始节点”,
// 并且,“key小于最小键(lo)”或者“key等于最小键(lo),但最小键却没包括在该SubMap内”
// 则判断key太小。其余情况都不是太小!
if (!fromStart) {
int c = m.compare(key, lo);
if (c < 0 || (c == 0 && !loInclusive))
return true;
}
return false;
}
// 判断key是否太大
final boolean tooHigh(Object key) {
// 若该SubMap不包括“结束节点”,
// 并且,“key大于最大键(hi)”或者“key等于最大键(hi),但最大键却没包括在该SubMap内”
// 则判断key太大。其余情况都不是太大!
if (!toEnd) {
int c = m.compare(key, hi);
if (c > 0 || (c == 0 && !hiInclusive))
return true;
}
return false;
}
// 判断key是否在“lo和hi”开区间范围内
final boolean inRange(Object key) {
return !tooLow(key) && !tooHigh(key);
}
// 判断key是否在封闭区间内
final boolean inClosedRange(Object key) {
return (fromStart || m.compare(key, lo) >= 0)
&& (toEnd || m.compare(hi, key) >= 0);
}
// 判断key是否在区间内, inclusive是区间开关标志
final boolean inRange(Object key, boolean inclusive) {
return inclusive ? inRange(key) : inClosedRange(key);
}
// 返回最低的Entry
final TreeMap.Entry<K,V> absLowest() {
// 若“包含起始节点”,则调用getFirstEntry()返回第一个节点
// 否则的话,若包括lo,则调用getCeilingEntry(lo)获取大于/等于lo的最小的Entry;
// 否则,调用getHigherEntry(lo)获取大于lo的最小Entry
TreeMap.Entry<K,V> e =
(fromStart ? m.getFirstEntry() :
(loInclusive ? m.getCeilingEntry(lo) :
m.getHigherEntry(lo)));
return (e == null || tooHigh(e.key)) ? null : e;
}
// 返回最高的Entry
final TreeMap.Entry<K,V> absHighest() {
// 若“包含结束节点”,则调用getLastEntry()返回最后一个节点
// 否则的话,若包括hi,则调用getFloorEntry(hi)获取小于/等于hi的最大的Entry;
// 否则,调用getLowerEntry(hi)获取大于hi的最大Entry
TreeMap.Entry<K,V> e =
TreeMap.Entry<K,V> e =
(toEnd ? m.getLastEntry() :
(hiInclusive ? m.getFloorEntry(hi) :
m.getLowerEntry(hi)));
return (e == null || tooLow(e.key)) ? null : e;
}
// 返回"大于/等于key的最小的Entry"
final TreeMap.Entry<K,V> absCeiling(K key) {
// 只有在“key太小”的情况下,absLowest()返回的Entry才是“大于/等于key的最小Entry”
// 其它情况下不行。例如,当包含“起始节点”时,absLowest()返回的是最小Entry了!
if (tooLow(key))
return absLowest();
// 获取“大于/等于key的最小Entry”
TreeMap.Entry<K,V> e = m.getCeilingEntry(key);
return (e == null || tooHigh(e.key)) ? null : e;
}
// 返回"大于key的最小的Entry"
final TreeMap.Entry<K,V> absHigher(K key) {
// 只有在“key太小”的情况下,absLowest()返回的Entry才是“大于key的最小Entry”
// 其它情况下不行。例如,当包含“起始节点”时,absLowest()返回的是最小Entry了,而不一定是“大于key的最小Entry”!
if (tooLow(key))
return absLowest();
// 获取“大于key的最小Entry”
TreeMap.Entry<K,V> e = m.getHigherEntry(key);
return (e == null || tooHigh(e.key)) ? null : e;
}
// 返回"小于/等于key的最大的Entry"
final TreeMap.Entry<K,V> absFloor(K key) {
// 只有在“key太大”的情况下,(absHighest)返回的Entry才是“小于/等于key的最大Entry”
// 其它情况下不行。例如,当包含“结束节点”时,absHighest()返回的是最大Entry了!
if (tooHigh(key))
return absHighest();
// 获取"小于/等于key的最大的Entry"
TreeMap.Entry<K,V> e = m.getFloorEntry(key);
return (e == null || tooLow(e.key)) ? null : e;
}
// 返回"小于key的最大的Entry"
final TreeMap.Entry<K,V> absLower(K key) {
// 只有在“key太大”的情况下,(absHighest)返回的Entry才是“小于key的最大Entry”
// 其它情况下不行。例如,当包含“结束节点”时,absHighest()返回的是最大Entry了,而不一定是“小于key的最大Entry”!
if (tooHigh(key))
return absHighest();
// 获取"小于key的最大的Entry"
TreeMap.Entry<K,V> e = m.getLowerEntry(key);
return (e == null || tooLow(e.key)) ? null : e;
}
// 返回“大于最大节点中的最小节点”,不存在的话,返回null
final TreeMap.Entry<K,V> absHighFence() {
return (toEnd ? null : (hiInclusive ?
m.getHigherEntry(hi) :
m.getCeilingEntry(hi)));
}
// 返回“小于最小节点中的最大节点”,不存在的话,返回null
final TreeMap.Entry<K,V> absLowFence() {
return (fromStart ? null : (loInclusive ?
m.getLowerEntry(lo) :
m.getFloorEntry(lo)));
}
// 下面几个abstract方法是需要NavigableSubMap的实现类实现的方法
abstract TreeMap.Entry<K,V> subLowest();
abstract TreeMap.Entry<K,V> subHighest();
abstract TreeMap.Entry<K,V> subCeiling(K key);
abstract TreeMap.Entry<K,V> subHigher(K key);
abstract TreeMap.Entry<K,V> subFloor(K key);
abstract TreeMap.Entry<K,V> subLower(K key);
// 返回“顺序”的键迭代器
abstract Iterator<K> keyIterator();
// 返回“逆序”的键迭代器
abstract Iterator<K> descendingKeyIterator();
// 返回SubMap是否为空。空的话,返回true,否则返回false
public boolean isEmpty() {
return (fromStart && toEnd) ? m.isEmpty() : entrySet().isEmpty();
}
// 返回SubMap的大小
public int size() {
return (fromStart && toEnd) ? m.size() : entrySet().size();
}
// 返回SubMap是否包含键key
public final boolean containsKey(Object key) {
return inRange(key) && m.containsKey(key);
}
// 将key-value 插入SubMap中
public final V put(K key, V value) {
if (!inRange(key))
throw new IllegalArgumentException("key out of range");
return m.put(key, value);
}
// 获取key对应值
public final V get(Object key) {
return !inRange(key)? null : m.get(key);
}
// 删除key对应的键值对
public final V remove(Object key) {
return !inRange(key)? null : m.remove(key);
}
// 获取“大于/等于key的最小键值对”
public final Map.Entry<K,V> ceilingEntry(K key) {
return exportEntry(subCeiling(key));
}
// 获取“大于/等于key的最小键”
public final K ceilingKey(K key) {
return keyOrNull(subCeiling(key));
}
// 获取“大于key的最小键值对”
public final Map.Entry<K,V> higherEntry(K key) {
return exportEntry(subHigher(key));
}
// 获取“大于key的最小键”
public final K higherKey(K key) {
return keyOrNull(subHigher(key));
}
// 获取“小于/等于key的最大键值对”
public final Map.Entry<K,V> floorEntry(K key) {
return exportEntry(subFloor(key));
}
// 获取“小于/等于key的最大键”
public final K floorKey(K key) {
return keyOrNull(subFloor(key));
}
// 获取“小于key的最大键值对”
public final Map.Entry<K,V> lowerEntry(K key) {
return exportEntry(subLower(key));
}
// 获取“小于key的最大键”
public final K lowerKey(K key) {
return keyOrNull(subLower(key));
}
// 获取"SubMap的第一个键"
public final K firstKey() {
return key(subLowest());
}
// 获取"SubMap的最后一个键"
public final K lastKey() {
return key(subHighest());
}
// 获取"SubMap的第一个键值对"
public final Map.Entry<K,V> firstEntry() {
return exportEntry(subLowest());
}
// 获取"SubMap的最后一个键值对"
public final Map.Entry<K,V> lastEntry() {
return exportEntry(subHighest());
}
// 返回"SubMap的第一个键值对",并从SubMap中删除改键值对
public final Map.Entry<K,V> pollFirstEntry() {
TreeMap.Entry<K,V> e = subLowest();
Map.Entry<K,V> result = exportEntry(e);
if (e != null)
m.deleteEntry(e);
return result;
}
// 返回"SubMap的最后一个键值对",并从SubMap中删除改键值对
public final Map.Entry<K,V> pollLastEntry() {
TreeMap.Entry<K,V> e = subHighest();
Map.Entry<K,V> result = exportEntry(e);
if (e != null)
m.deleteEntry(e);
return result;
}
// Views
transient NavigableMap<K,V> descendingMapView = null;
transient EntrySetView entrySetView = null;
transient KeySet<K> navigableKeySetView = null;
// 返回NavigableSet对象,实际上返回的是当前对象的"Key集合"。
public final NavigableSet<K> navigableKeySet() {
KeySet<K> nksv = navigableKeySetView;
return (nksv != null) ? nksv :
(navigableKeySetView = new TreeMap.KeySet(this));
}
// 返回"Key集合"对象
public final Set<K> keySet() {
return navigableKeySet();
}
// 返回“逆序”的Key集合
public NavigableSet<K> descendingKeySet() {
return descendingMap().navigableKeySet();
}
// 排列fromKey(包含) 到 toKey(不包含) 的子map
public final SortedMap<K,V> subMap(K fromKey, K toKey) {
return subMap(fromKey, true, toKey, false);
}
// 返回当前Map的头部(从第一个节点 到 toKey, 不包括toKey)
public final SortedMap<K,V> headMap(K toKey) {
return headMap(toKey, false);
}
// 返回当前Map的尾部[从 fromKey(包括fromKeyKey) 到 最后一个节点]
public final SortedMap<K,V> tailMap(K fromKey) {
return tailMap(fromKey, true);
}
// Map的Entry的集合
abstract class EntrySetView extends AbstractSet<Map.Entry<K,V>> {
private transient int size = -1, sizeModCount;
// 获取EntrySet的大小
public int size() {
// 若SubMap是从“开始节点”到“结尾节点”,则SubMap大小就是原TreeMap的大小
if (fromStart && toEnd)
return m.size();
// 若SubMap不是从“开始节点”到“结尾节点”,则调用iterator()遍历EntrySetView中的元素
if (size == -1 || sizeModCount != m.modCount) {
sizeModCount = m.modCount;
size = 0;
Iterator i = iterator();
while (i.hasNext()) {
size++;
i.next();
}
}
return size;
}
// 判断EntrySetView是否为空
public boolean isEmpty() {
TreeMap.Entry<K,V> n = absLowest();
return n == null || tooHigh(n.key);
}
// 判断EntrySetView是否包含Object
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
K key = entry.getKey();
if (!inRange(key))
return false;
TreeMap.Entry node = m.getEntry(key);
return node != null &&
valEquals(node.getValue(), entry.getValue());
}
// 从EntrySetView中删除Object
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
K key = entry.getKey();
if (!inRange(key))
return false;
TreeMap.Entry<K,V> node = m.getEntry(key);
if (node!=null && valEquals(node.getValue(),entry.getValue())){
m.deleteEntry(node);
return true;
}
return false;
}
}
// SubMap的迭代器
abstract class SubMapIterator<T> implements Iterator<T> {
// 上一次被返回的Entry
TreeMap.Entry<K,V> lastReturned;
// 指向下一个Entry
TreeMap.Entry<K,V> next;
// “栅栏key”。根据SubMap是“升序”还是“降序”具有不同的意义
final K fenceKey;
int expectedModCount;
// 构造函数
SubMapIterator(TreeMap.Entry<K,V> first,
TreeMap.Entry<K,V> fence) {
// 每创建一个SubMapIterator时,保存修改次数
// 若后面发现expectedModCount和modCount不相等,则抛出ConcurrentModificationException异常。
// 这就是所说的fast-fail机制的原理!
expectedModCount = m.modCount;
lastReturned = null;
next = first;
fenceKey = fence == null ? null : fence.key;
}
// 是否存在下一个Entry
public final boolean hasNext() {
return next != null && next.key != fenceKey;
}
// 返回下一个Entry
final TreeMap.Entry<K,V> nextEntry() {
TreeMap.Entry<K,V> e = next;
if (e == null || e.key == fenceKey)
throw new NoSuchElementException();
if (m.modCount != expectedModCount)
throw new ConcurrentModificationException();
// next指向e的后继节点
next = successor(e);
lastReturned = e;
return e;
}
// 返回上一个Entry
final TreeMap.Entry<K,V> prevEntry() {
TreeMap.Entry<K,V> e = next;
if (e == null || e.key == fenceKey)
throw new NoSuchElementException();
if (m.modCount != expectedModCount)
throw new ConcurrentModificationException();
// next指向e的前继节点
next = predecessor(e);
lastReturned = e;
return e;
}
// 删除当前节点(用于“升序的SubMap”)。
// 删除之后,可以继续升序遍历;红黑树特性没变。
final void removeAscending() {
if (lastReturned == null)
throw new IllegalStateException();
if (m.modCount != expectedModCount)
throw new ConcurrentModificationException();
// 这里重点强调一下“为什么当lastReturned的左右孩子都不为空时,要将其赋值给next”。
// 目的是为了“删除lastReturned节点之后,next节点指向的仍然是下一个节点”。
// 根据“红黑树”的特性可知:
// 当被删除节点有两个儿子时。那么,首先把“它的后继节点的内容”复制给“该节点的内容”;之后,删除“它的后继节点”。
// 这意味着“当被删除节点有两个儿子时,删除当前节点之后,'新的当前节点'实际上是‘原有的后继节点(即下一个节点)’”。
// 而此时next仍然指向"新的当前节点"。也就是说next是仍然是指向下一个节点;能继续遍历红黑树。
if (lastReturned.left != null && lastReturned.right != null)
next = lastReturned;
m.deleteEntry(lastReturned);
lastReturned = null;
expectedModCount = m.modCount;
}
// 删除当前节点(用于“降序的SubMap”)。
// 删除之后,可以继续降序遍历;红黑树特性没变。
final void removeDescending() {
if (lastReturned == null)
throw new IllegalStateException();
if (m.modCount != expectedModCount)
throw new ConcurrentModificationException();
m.deleteEntry(lastReturned);
lastReturned = null;
expectedModCount = m.modCount;
}
}
// SubMap的Entry迭代器,它只支持升序操作,继承于SubMapIterator
final class SubMapEntryIterator extends SubMapIterator<Map.Entry<K,V>> {
SubMapEntryIterator(TreeMap.Entry<K,V> first,
TreeMap.Entry<K,V> fence) {
super(first, fence);
}
// 获取下一个节点(升序)
public Map.Entry<K,V> next() {
return nextEntry();
}
// 删除当前节点(升序)
public void remove() {
removeAscending();
}
}
// SubMap的Key迭代器,它只支持升序操作,继承于SubMapIterator
final class SubMapKeyIterator extends SubMapIterator<K> {
SubMapKeyIterator(TreeMap.Entry<K,V> first,
TreeMap.Entry<K,V> fence) {
super(first, fence);
}
// 获取下一个节点(升序)
public K next() {
return nextEntry().key;
}
// 删除当前节点(升序)
public void remove() {
removeAscending();
}
}
// 降序SubMap的Entry迭代器,它只支持降序操作,继承于SubMapIterator
final class DescendingSubMapEntryIterator extends SubMapIterator<Map.Entry<K,V>> {
DescendingSubMapEntryIterator(TreeMap.Entry<K,V> last,
TreeMap.Entry<K,V> fence) {
super(last, fence);
}
// 获取下一个节点(降序)
public Map.Entry<K,V> next() {
return prevEntry();
}
// 删除当前节点(降序)
public void remove() {
removeDescending();
}
}
// 降序SubMap的Key迭代器,它只支持降序操作,继承于SubMapIterator
final class DescendingSubMapKeyIterator extends SubMapIterator<K> {
DescendingSubMapKeyIterator(TreeMap.Entry<K,V> last,
TreeMap.Entry<K,V> fence) {
super(last, fence);
}
// 获取下一个节点(降序)
public K next() {
return prevEntry().key;
}
// 删除当前节点(降序)
public void remove() {
removeDescending();
}
}
}
// 升序的SubMap,继承于NavigableSubMap
static final class AscendingSubMap<K,V> extends NavigableSubMap<K,V> {
private static final long serialVersionUID = 912986545866124060L;
// 构造函数
AscendingSubMap(TreeMap<K,V> m,
boolean fromStart, K lo, boolean loInclusive,
boolean toEnd, K hi, boolean hiInclusive) {
super(m, fromStart, lo, loInclusive, toEnd, hi, hiInclusive);
}
// 比较器
public Comparator<? super K> comparator() {
return m.comparator();
}
// 获取“子Map”。
// 范围是从fromKey 到 toKey;fromInclusive是是否包含fromKey的标记,toInclusive是是否包含toKey的标记
public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive) {
if (!inRange(fromKey, fromInclusive))
throw new IllegalArgumentException("fromKey out of range");
if (!inRange(toKey, toInclusive))
throw new IllegalArgumentException("toKey out of range");
return new AscendingSubMap(m,
false, fromKey, fromInclusive,
false, toKey, toInclusive);
}
// 获取“Map的头部”。
// 范围从第一个节点 到 toKey, inclusive是是否包含toKey的标记
public NavigableMap<K,V> headMap(K toKey, boolean inclusive) {
if (!inRange(toKey, inclusive))
throw new IllegalArgumentException("toKey out of range");
return new AscendingSubMap(m,
fromStart, lo, loInclusive,
false, toKey, inclusive);
}
// 获取“Map的尾部”。
// 范围是从 fromKey 到 最后一个节点,inclusive是是否包含fromKey的标记
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive){
if (!inRange(fromKey, inclusive))
throw new IllegalArgumentException("fromKey out of range");
return new AscendingSubMap(m,
false, fromKey, inclusive,
toEnd, hi, hiInclusive);
}
// 获取对应的降序Map
public NavigableMap<K,V> descendingMap() {
NavigableMap<K,V> mv = descendingMapView;
return (mv != null) ? mv :
(descendingMapView =
new DescendingSubMap(m,
fromStart, lo, loInclusive,
toEnd, hi, hiInclusive));
}
// 返回“升序Key迭代器”
Iterator<K> keyIterator() {
return new SubMapKeyIterator(absLowest(), absHighFence());
}
// 返回“降序Key迭代器”
Iterator<K> descendingKeyIterator() {
return new DescendingSubMapKeyIterator(absHighest(), absLowFence());
}
// “升序EntrySet集合”类
// 实现了iterator()
final class AscendingEntrySetView extends EntrySetView {
public Iterator<Map.Entry<K,V>> iterator() {
return new SubMapEntryIterator(absLowest(), absHighFence());
}
}
// 返回“升序EntrySet集合”
public Set<Map.Entry<K,V>> entrySet() {
EntrySetView es = entrySetView;
return (es != null) ? es : new AscendingEntrySetView();
}
TreeMap.Entry<K,V> subLowest() { return absLowest(); }
TreeMap.Entry<K,V> subHighest() { return absHighest(); }
TreeMap.Entry<K,V> subCeiling(K key) { return absCeiling(key); }
TreeMap.Entry<K,V> subHigher(K key) { return absHigher(key); }
TreeMap.Entry<K,V> subFloor(K key) { return absFloor(key); }
TreeMap.Entry<K,V> subLower(K key) { return absLower(key); }
}
// 降序的SubMap,继承于NavigableSubMap
// 相比于升序SubMap,它的实现机制是将“SubMap的比较器反转”!
static final class DescendingSubMap<K,V> extends NavigableSubMap<K,V> {
private static final long serialVersionUID = 912986545866120460L;
DescendingSubMap(TreeMap<K,V> m,
boolean fromStart, K lo, boolean loInclusive,
boolean toEnd, K hi, boolean hiInclusive) {
super(m, fromStart, lo, loInclusive, toEnd, hi, hiInclusive);
}
// 反转的比较器:是将原始比较器反转得到的。
private final Comparator<? super K> reverseComparator =
Collections.reverseOrder(m.comparator);
// 获取反转比较器
public Comparator<? super K> comparator() {
return reverseComparator;
}
// 获取“子Map”。
// 范围是从fromKey 到 toKey;fromInclusive是是否包含fromKey的标记,toInclusive是是否包含toKey的标记
public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive) {
if (!inRange(fromKey, fromInclusive))
throw new IllegalArgumentException("fromKey out of range");
if (!inRange(toKey, toInclusive))
throw new IllegalArgumentException("toKey out of range");
return new DescendingSubMap(m,
false, toKey, toInclusive,
false, fromKey, fromInclusive);
}
// 获取“Map的头部”。
// 范围从第一个节点 到 toKey, inclusive是是否包含toKey的标记
public NavigableMap<K,V> headMap(K toKey, boolean inclusive) {
if (!inRange(toKey, inclusive))
throw new IllegalArgumentException("toKey out of range");
return new DescendingSubMap(m,
false, toKey, inclusive,
toEnd, hi, hiInclusive);
}
// 获取“Map的尾部”。
// 范围是从 fromKey 到 最后一个节点,inclusive是是否包含fromKey的标记
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive){
if (!inRange(fromKey, inclusive))
throw new IllegalArgumentException("fromKey out of range");
return new DescendingSubMap(m,
fromStart, lo, loInclusive,
false, fromKey, inclusive);
}
// 获取对应的降序Map
public NavigableMap<K,V> descendingMap() {
NavigableMap<K,V> mv = descendingMapView;
return (mv != null) ? mv :
(descendingMapView =
new AscendingSubMap(m,
fromStart, lo, loInclusive,
toEnd, hi, hiInclusive));
}
// 返回“升序Key迭代器”
Iterator<K> keyIterator() {
return new DescendingSubMapKeyIterator(absHighest(), absLowFence());
}
// 返回“降序Key迭代器”
Iterator<K> descendingKeyIterator() {
return new SubMapKeyIterator(absLowest(), absHighFence());
}
// “降序EntrySet集合”类
// 实现了iterator()
final class DescendingEntrySetView extends EntrySetView {
public Iterator<Map.Entry<K,V>> iterator() {
return new DescendingSubMapEntryIterator(absHighest(), absLowFence());
}
}
// 返回“降序EntrySet集合”
public Set<Map.Entry<K,V>> entrySet() {
EntrySetView es = entrySetView;
return (es != null) ? es : new DescendingEntrySetView();
}
TreeMap.Entry<K,V> subLowest() { return absHighest(); }
TreeMap.Entry<K,V> subHighest() { return absLowest(); }
TreeMap.Entry<K,V> subCeiling(K key) { return absFloor(key); }
TreeMap.Entry<K,V> subHigher(K key) { return absLower(key); }
TreeMap.Entry<K,V> subFloor(K key) { return absCeiling(key); }
TreeMap.Entry<K,V> subLower(K key) { return absHigher(key); }
}
// SubMap是旧版本的类,新的Java中没有用到。
private class SubMap extends AbstractMap<K,V>
implements SortedMap<K,V>, java.io.Serializable {
private static final long serialVersionUID = -6520786458950516097L;
private boolean fromStart = false, toEnd = false;
private K fromKey, toKey;
private Object readResolve() {
return new AscendingSubMap(TreeMap.this,
fromStart, fromKey, true,
toEnd, toKey, false);
}
public Set<Map.Entry<K,V>> entrySet() { throw new InternalError(); }
public K lastKey() { throw new InternalError(); }
public K firstKey() { throw new InternalError(); }
public SortedMap<K,V> subMap(K fromKey, K toKey) { throw new InternalError(); }
public SortedMap<K,V> headMap(K toKey) { throw new InternalError(); }
public SortedMap<K,V> tailMap(K fromKey) { throw new InternalError(); }
public Comparator<? super K> comparator() { throw new InternalError(); }
}
// 红黑树的节点颜色--红色
private static final boolean RED = false;
// 红黑树的节点颜色--黑色
private static final boolean BLACK = true;
// “红黑树的节点”对应的类。
// 包含了 key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)
static final class Entry<K,V> implements Map.Entry<K,V> {
// 键
K key;
// 值
V value;
// 左孩子
Entry<K,V> left = null;
// 右孩子
Entry<K,V> right = null;
// 父节点
Entry<K,V> parent;
// 当前节点颜色
boolean color = BLACK;
// 构造函数
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
// 返回“键”
public K getKey() {
return key;
}
// 返回“值”
public V getValue() {
return value;
}
// 更新“值”,返回旧的值
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
// 判断两个节点是否相等的函数,覆盖equals()函数。
// 若两个节点的“key相等”并且“value相等”,则两个节点相等
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return valEquals(key,e.getKey()) && valEquals(value,e.getValue());
}
// 覆盖hashCode函数。
public int hashCode() {
int keyHash = (key==null ? 0 : key.hashCode());
int valueHash = (value==null ? 0 : value.hashCode());
return keyHash ^ valueHash;
}
// 覆盖toString()函数。
public String toString() {
return key + "=" + value;
}
}
// 返回“红黑树的第一个节点”
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
// 返回“红黑树的最后一个节点”
final Entry<K,V> getLastEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.right != null)
p = p.right;
return p;
}
// 返回“节点t的后继节点”
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.right != null) {
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
// 返回“节点t的前继节点”
static <K,V> Entry<K,V> predecessor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.left != null) {
Entry<K,V> p = t.left;
while (p.right != null)
p = p.right;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.left) {
ch = p;
p = p.parent;
}
return p;
}
}
// 返回“节点p的颜色”
// 根据“红黑树的特性”可知:空节点颜色是黑色。
private static <K,V> boolean colorOf(Entry<K,V> p) {
return (p == null ? BLACK : p.color);
}
// 返回“节点p的父节点”
private static <K,V> Entry<K,V> parentOf(Entry<K,V> p) {
return (p == null ? null: p.parent);
}
// 设置“节点p的颜色为c”
private static <K,V> void setColor(Entry<K,V> p, boolean c) {
if (p != null)
p.color = c;
}
// 设置“节点p的左孩子”
private static <K,V> Entry<K,V> leftOf(Entry<K,V> p) {
return (p == null) ? null: p.left;
}
// 设置“节点p的右孩子”
private static <K,V> Entry<K,V> rightOf(Entry<K,V> p) {
return (p == null) ? null: p.right;
}
// 对节点p执行“左旋”操作
private void rotateLeft(Entry<K,V> p) {
if (p != null) {
Entry<K,V> r = p.right;
p.right = r.left;
if (r.left != null)
r.left.parent = p;
r.parent = p.parent;
if (p.parent == null)
root = r;
else if (p.parent.left == p)
p.parent.left = r;
else
p.parent.right = r;
r.left = p;
p.parent = r;
}
}
// 对节点p执行“右旋”操作
private void rotateRight(Entry<K,V> p) {
if (p != null) {
Entry<K,V> l = p.left;
p.left = l.right;
if (l.right != null) l.right.parent = p;
l.parent = p.parent;
if (p.parent == null)
root = l;
else if (p.parent.right == p)
p.parent.right = l;
else p.parent.left = l;
l.right = p;
p.parent = l;
}
}
// 插入之后的修正操作。
// 目的是保证:红黑树插入节点之后,仍然是一颗红黑树
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
// 删除“红黑树的节点p”
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {
Entry<K,V> s = successor (p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// Link replacement to parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// Fix replacement
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
// 删除之后的修正操作。
// 目的是保证:红黑树删除节点之后,仍然是一颗红黑树
private void fixAfterDeletion(Entry<K,V> x) {
while (x != root && colorOf(x) == BLACK) {
if (x == leftOf(parentOf(x))) {
Entry<K,V> sib = rightOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateLeft(parentOf(x));
sib = rightOf(parentOf(x));
}
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK);
setColor(sib, RED);
rotateRight(sib);
sib = rightOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(rightOf(sib), BLACK);
rotateLeft(parentOf(x));
x = root;
}
} else { // symmetric
Entry<K,V> sib = leftOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateRight(parentOf(x));
sib = leftOf(parentOf(x));
}
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(leftOf(sib)) == BLACK) {
setColor(rightOf(sib), BLACK);
setColor(sib, RED);
rotateLeft(sib);
sib = leftOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(leftOf(sib), BLACK);
rotateRight(parentOf(x));
x = root;
}
}
}
setColor(x, BLACK);
}
private static final long serialVersionUID = 919286545866124006L;
// java.io.Serializable的写入函数
// 将TreeMap的“容量,所有的Entry”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out the Comparator and any hidden stuff
s.defaultWriteObject();
// Write out size (number of Mappings)
s.writeInt(size);
// Write out keys and values (alternating)
for (Iterator<Map.Entry<K,V>> i = entrySet().iterator(); i.hasNext(); ) {
Map.Entry<K,V> e = i.next();
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
}
// java.io.Serializable的读取函数:根据写入方式读出
// 先将TreeMap的“容量、所有的Entry”依次读出
private void readObject(final java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in the Comparator and any hidden stuff
s.defaultReadObject();
// Read in size
int size = s.readInt();
buildFromSorted(size, null, s, null);
}
// 根据已经一个排好序的map创建一个TreeMap
private void buildFromSorted(int size, Iterator it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
this.size = size;
root = buildFromSorted(0, 0, size-1, computeRedLevel(size),
it, str, defaultVal);
}
// 根据已经一个排好序的map创建一个TreeMap
// 将map中的元素逐个添加到TreeMap中,并返回map的中间元素作为根节点。
private final Entry<K,V> buildFromSorted(int level, int lo, int hi,
int redLevel,
Iterator it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
if (hi < lo) return null;
// 获取中间元素
int mid = (lo + hi) / 2;
Entry<K,V> left = null;
// 若lo小于mid,则递归调用获取(middel的)左孩子。
if (lo < mid)
left = buildFromSorted(level+1, lo, mid - 1, redLevel,
it, str, defaultVal);
// 获取middle节点对应的key和value
K key;
V value;
if (it != null) {
if (defaultVal==null) {
Map.Entry<K,V> entry = (Map.Entry<K,V>)it.next();
key = entry.getKey();
value = entry.getValue();
} else {
key = (K)it.next();
value = defaultVal;
}
} else { // use stream
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
}
// 创建middle节点
Entry<K,V> middle = new Entry<K,V>(key, value, null);
// 若当前节点的深度=红色节点的深度,则将节点着色为红色。
if (level == redLevel)
middle.color = RED;
// 设置middle为left的父亲,left为middle的左孩子
if (left != null) {
middle.left = left;
left.parent = middle;
}
if (mid < hi) {
// 递归调用获取(middel的)右孩子。
Entry<K,V> right = buildFromSorted(level+1, mid+1, hi, redLevel,
it, str, defaultVal);
// 设置middle为left的父亲,left为middle的左孩子
middle.right = right;
right.parent = middle;
}
return middle;
}
// 计算节点树为sz的最大深度,也是红色节点的深度值。
private static int computeRedLevel(int sz) {
int level = 0;
for (int m = sz - 1; m >= 0; m = m / 2 - 1)
level++;
return level;
}
}说明:
在详细介绍TreeMap的代码之前,我们先建立一个整体概念。
TreeMap是通过红黑树实现的,TreeMap存储的是key-value键值对,TreeMap的排序是基于对key的排序。
TreeMap提供了操作“key”、“key-value”、“value”等方法,也提供了对TreeMap这颗树进行整体操作的方法,如获取子树、反向树。
后面的解说内容分为几部分,
首先,介绍TreeMap的核心,即红黑树相关部分;
然后,介绍TreeMap的主要函数;
再次,介绍TreeMap实现的几个接口;
最后,补充介绍TreeMap的其它内容。
详细:http://www.cnblogs.com/skywang12345/p/3310928.html
TreeMap遍历方式
4.1 遍历TreeMap的键值对
第一步:根据entrySet()获取TreeMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
Integer integ = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}4.2 遍历TreeMap的键
第一步:根据keySet()获取TreeMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
String key = null;
Integer integ = null;
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)map.get(key);
}4.3 遍历TreeMap的值
第一步:根据value()获取TreeMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
Integer value = null;
Collection c = map.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}顺序遍历和逆序遍历
keyIterator()的作用是返回顺序的KEY的集合,
descendingKeyIterator()的作用是返回逆序的KEY的集合。
代码示例
import java.util.*;
/**
* @desc TreeMap测试程序
*
* @author skywang
*/
public class TreeMapTest {
public static void main(String[] args) {
// 测试常用的API
testTreeMapOridinaryAPIs();
// 测试TreeMap的导航函数
//testNavigableMapAPIs();
// 测试TreeMap的子Map函数
//testSubMapAPIs();
}
/**
* 测试常用的API
*/
private static void testTreeMapOridinaryAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建TreeMap
TreeMap tmap = new TreeMap();
// 添加操作
tmap.put("one", r.nextInt(10));
tmap.put("two", r.nextInt(10));
tmap.put("three", r.nextInt(10));
System.out.printf("\n ---- testTreeMapOridinaryAPIs ----\n");
// 打印出TreeMap
System.out.printf("%s\n",tmap );
// 通过Iterator遍历key-value
Iterator iter = tmap.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
System.out.printf("next : %s - %s\n", entry.getKey(), entry.getValue());
}
// TreeMap的键值对个数
System.out.printf("size: %s\n", tmap.size());
// containsKey(Object key) :是否包含键key
System.out.printf("contains key two : %s\n",tmap.containsKey("two"));
System.out.printf("contains key five : %s\n",tmap.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.printf("contains value 0 : %s\n",tmap.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
tmap.remove("three");
System.out.printf("tmap:%s\n",tmap );
// clear() : 清空TreeMap
tmap.clear();
// isEmpty() : TreeMap是否为空
System.out.printf("%s\n", (tmap.isEmpty()?"tmap is empty":"tmap is not empty") );
}
/**
* 测试TreeMap的子Map函数
*/
public static void testSubMapAPIs() {
// 新建TreeMap
TreeMap tmap = new TreeMap();
// 添加“键值对”
tmap.put("a", 101);
tmap.put("b", 102);
tmap.put("c", 103);
tmap.put("d", 104);
tmap.put("e", 105);
System.out.printf("\n ---- testSubMapAPIs ----\n");
// 打印出TreeMap
System.out.printf("tmap:\n\t%s\n", tmap);
// 测试 headMap(K toKey)
System.out.printf("tmap.headMap(\"c\"):\n\t%s\n", tmap.headMap("c"));
// 测试 headMap(K toKey, boolean inclusive)
System.out.printf("tmap.headMap(\"c\", true):\n\t%s\n", tmap.headMap("c", true));
System.out.printf("tmap.headMap(\"c\", false):\n\t%s\n", tmap.headMap("c", false));
// 测试 tailMap(K fromKey)
System.out.printf("tmap.tailMap(\"c\"):\n\t%s\n", tmap.tailMap("c"));
// 测试 tailMap(K fromKey, boolean inclusive)
System.out.printf("tmap.tailMap(\"c\", true):\n\t%s\n", tmap.tailMap("c", true));
System.out.printf("tmap.tailMap(\"c\", false):\n\t%s\n", tmap.tailMap("c", false));
// 测试 subMap(K fromKey, K toKey)
System.out.printf("tmap.subMap(\"a\", \"c\"):\n\t%s\n", tmap.subMap("a", "c"));
// 测试
System.out.printf("tmap.subMap(\"a\", true, \"c\", true):\n\t%s\n",
tmap.subMap("a", true, "c", true));
System.out.printf("tmap.subMap(\"a\", true, \"c\", false):\n\t%s\n",
tmap.subMap("a", true, "c", false));
System.out.printf("tmap.subMap(\"a\", false, \"c\", true):\n\t%s\n",
tmap.subMap("a", false, "c", true));
System.out.printf("tmap.subMap(\"a\", false, \"c\", false):\n\t%s\n",
tmap.subMap("a", false, "c", false));
// 测试 navigableKeySet()
System.out.printf("tmap.navigableKeySet():\n\t%s\n", tmap.navigableKeySet());
// 测试 descendingKeySet()
System.out.printf("tmap.descendingKeySet():\n\t%s\n", tmap.descendingKeySet());
}
/**
* 测试TreeMap的导航函数
*/
public static void testNavigableMapAPIs() {
// 新建TreeMap
NavigableMap nav = new TreeMap();
// 添加“键值对”
nav.put("aaa", 111);
nav.put("bbb", 222);
nav.put("eee", 333);
nav.put("ccc", 555);
nav.put("ddd", 444);
System.out.printf("\n ---- testNavigableMapAPIs ----\n");
// 打印出TreeMap
System.out.printf("Whole list:%s%n", nav);
// 获取第一个key、第一个Entry
System.out.printf("First key: %s\tFirst entry: %s%n",nav.firstKey(), nav.firstEntry());
// 获取最后一个key、最后一个Entry
System.out.printf("Last key: %s\tLast entry: %s%n",nav.lastKey(), nav.lastEntry());
// 获取“小于/等于bbb”的最大键值对
System.out.printf("Key floor before bbb: %s%n",nav.floorKey("bbb"));
// 获取“小于bbb”的最大键值对
System.out.printf("Key lower before bbb: %s%n", nav.lowerKey("bbb"));
// 获取“大于/等于bbb”的最小键值对
System.out.printf("Key ceiling after ccc: %s%n",nav.ceilingKey("ccc"));
// 获取“大于bbb”的最小键值对
System.out.printf("Key higher after ccc: %s%n\n",nav.higherKey("ccc"));
}
}
/*
---- testTreeMapOridinaryAPIs ----
{one=3, three=2, two=3}
next : one - 3
next : three - 2
next : two - 3
size: 3
contains key two : true
contains key five : false
contains value 0 : false
tmap:{one=3, two=3}
tmap is empty
*/WeakHashMap
WeakHashMap简介
WeakHashMap 继承于AbstractMap,实现了Map接口。
和HashMap一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和值都可以是null。
不过WeakHashMap的键是“弱键”。在 WeakHashMap 中,当某个键不再正常使用时,会被从WeakHashMap中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
这个“弱键”的原理呢?大致上就是,通过WeakReference和ReferenceQueue实现的。 WeakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的“弱键”。实现步骤是:
新建WeakHashMap,将“键值对”添加到WeakHashMap中。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到ReferenceQueue(queue)队列中。
这就是“弱键”如何被自动从WeakHashMap中删除的步骤了。
和HashMap一样,WeakHashMap**是不同步的。**可以使用 Collections.synchronizedMap 方法来构造同步的 WeakHashMap。
WeakHashMap数据结构
WeakHashMap的继承关系
java.lang.Object
↳ java.util.AbstractMap<K, V>
↳ java.util.WeakHashMap<K, V>
public class WeakHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V> {}WeakHashMap与Map关系
从图中可以看出:
1. WeakHashMap继承于AbstractMap,并且实现了Map接口。
2. WeakHashMap是哈希表,但是它的键是”弱键”。WeakHashMap中保护几个重要的成员变量:table, size, threshold, loadFactor, modCount, queue。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
size是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值=”容量*加载因子”。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
queue保存的是“已被GC清除”的“弱引用的键”。
WeakHashMap源码
package java.util;
import java.lang.ref.WeakReference;
import java.lang.ref.ReferenceQueue;
public class WeakHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V> {
// 默认的初始容量是16,必须是2的幂。
private static final int DEFAULT_INITIAL_CAPACITY = 16;
// 最大容量(必须是2的幂且小于2的30次方,传入容量过大将被这个值替换)
private static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认加载因子
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 存储数据的Entry数组,长度是2的幂。
// WeakHashMap是采用拉链法实现的,每一个Entry本质上是一个单向链表
private Entry[] table;
// WeakHashMap的大小,它是WeakHashMap保存的键值对的数量
private int size;
// WeakHashMap的阈值,用于判断是否需要调整WeakHashMap的容量(threshold = 容量*加载因子)
private int threshold;
// 加载因子实际大小
private final float loadFactor;
// queue保存的是“已被GC清除”的“弱引用的键”。
// 弱引用和ReferenceQueue 是联合使用的:如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中
private final ReferenceQueue<K> queue = new ReferenceQueue<K>();
// WeakHashMap被改变的次数
private volatile int modCount;
// 指定“容量大小”和“加载因子”的构造函数
public WeakHashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Initial Capacity: "+
initialCapacity);
// WeakHashMap的最大容量只能是MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load factor: "+
loadFactor);
// 找出“大于initialCapacity”的最小的2的幂
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// 创建Entry数组,用来保存数据
table = new Entry[capacity];
// 设置“加载因子”
this.loadFactor = loadFactor;
// 设置“WeakHashMap阈值”,当WeakHashMap中存储数据的数量达到threshold时,就需要将WeakHashMap的容量加倍。
threshold = (int)(capacity * loadFactor);
}
// 指定“容量大小”的构造函数
public WeakHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 默认构造函数。
public WeakHashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
}
// 包含“子Map”的构造函数
public WeakHashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1, 16),
DEFAULT_LOAD_FACTOR);
// 将m中的全部元素逐个添加到WeakHashMap中
putAll(m);
}
// 键为null的mask值。
// 因为WeakReference中允许“null的key”,若直接插入“null的key”,将其当作弱引用时,会被删除。
// 因此,这里对于“key为null”的清空,都统一替换为“key为NULL_KEY”,“NULL_KEY”是“静态的final常量”。
private static final Object NULL_KEY = new Object();
// 对“null的key”进行特殊处理
private static Object maskNull(Object key) {
return (key == null ? NULL_KEY : key);
}
// 还原对“null的key”的特殊处理
private static <K> K unmaskNull(Object key) {
return (K) (key == NULL_KEY ? null : key);
}
// 判断“x”和“y”是否相等
static boolean eq(Object x, Object y) {
return x == y || x.equals(y);
}
// 返回索引值
// h & (length-1)保证返回值的小于length
static int indexFor(int h, int length) {
return h & (length-1);
}
// 清空table中无用键值对。原理如下:
// (01) 当WeakHashMap中某个“弱引用的key”由于没有再被引用而被GC收回时,
// 被回收的“该弱引用key”也被会被添加到"ReferenceQueue(queue)"中。
// (02) 当我们执行expungeStaleEntries时,
// 就遍历"ReferenceQueue(queue)"中的所有key
// 然后就在“WeakReference的table”中删除与“ReferenceQueue(queue)中key”对应的键值对
private void expungeStaleEntries() {
Entry<K,V> e;
while ( (e = (Entry<K,V>) queue.poll()) != null) {
int h = e.hash;
int i = indexFor(h, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
while (p != null) {
Entry<K,V> next = p.next;
if (p == e) {
if (prev == e)
table[i] = next;
else
prev.next = next;
e.next = null; // Help GC
e.value = null; // " "
size--;
break;
}
prev = p;
p = next;
}
}
}
// 获取WeakHashMap的table(存放键值对的数组)
private Entry[] getTable() {
// 删除table中“已被GC回收的key对应的键值对”
expungeStaleEntries();
return table;
}
// 获取WeakHashMap的实际大小
public int size() {
if (size == 0)
return 0;
// 删除table中“已被GC回收的key对应的键值对”
expungeStaleEntries();
return size;
}
public boolean isEmpty() {
return size() == 0;
}
// 获取key对应的value
public V get(Object key) {
Object k = maskNull(key);
// 获取key的hash值。
int h = HashMap.hash(k.hashCode());
Entry[] tab = getTable();
int index = indexFor(h, tab.length);
Entry<K,V> e = tab[index];
// 在“该hash值对应的链表”上查找“键值等于key”的元素
while (e != null) {
if (e.hash == h && eq(k, e.get()))
return e.value;
e = e.next;
}
return null;
}
// WeakHashMap是否包含key
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
// 返回“键为key”的键值对
Entry<K,V> getEntry(Object key) {
Object k = maskNull(key);
int h = HashMap.hash(k.hashCode());
Entry[] tab = getTable();
int index = indexFor(h, tab.length);
Entry<K,V> e = tab[index];
while (e != null && !(e.hash == h && eq(k, e.get())))
e = e.next;
return e;
}
// 将“key-value”添加到WeakHashMap中
public V put(K key, V value) {
K k = (K) maskNull(key);
int h = HashMap.hash(k.hashCode());
Entry[] tab = getTable();
int i = indexFor(h, tab.length);
for (Entry<K,V> e = tab[i]; e != null; e = e.next) {
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (h == e.hash && eq(k, e.get())) {
V oldValue = e.value;
if (value != oldValue)
e.value = value;
return oldValue;
}
}
// 若“该key”对应的键值对不存在于WeakHashMap中,则将“key-value”添加到table中
modCount++;
Entry<K,V> e = tab[i];
tab[i] = new Entry<K,V>(k, value, queue, h, e);
if (++size >= threshold)
resize(tab.length * 2);
return null;
}
// 重新调整WeakHashMap的大小,newCapacity是调整后的单位
void resize(int newCapacity) {
Entry[] oldTable = getTable();
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建一个newTable,将“旧的table”的全部元素添加到“新的newTable”中,
// 然后,将“新的newTable”赋值给“旧的table”。
Entry[] newTable = new Entry[newCapacity];
transfer(oldTable, newTable);
table = newTable;
if (size >= threshold / 2) {
threshold = (int)(newCapacity * loadFactor);
} else {
// 删除table中“已被GC回收的key对应的键值对”
expungeStaleEntries();
transfer(newTable, oldTable);
table = oldTable;
}
}
// 将WeakHashMap中的全部元素都添加到newTable中
private void transfer(Entry[] src, Entry[] dest) {
for (int j = 0; j < src.length; ++j) {
Entry<K,V> e = src[j];
src[j] = null;
while (e != null) {
Entry<K,V> next = e.next;
Object key = e.get();
if (key == null) {
e.next = null; // Help GC
e.value = null; // " "
size--;
} else {
int i = indexFor(e.hash, dest.length);
e.next = dest[i];
dest[i] = e;
}
e = next;
}
}
}
// 将"m"的全部元素都添加到WeakHashMap中
public void putAll(Map<? extends K, ? extends V> m) {
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
// 计算容量是否足够,
// 若“当前实际容量 < 需要的容量”,则将容量x2。
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
// 将“m”中的元素逐个添加到WeakHashMap中。
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
// 删除“键为key”元素
public V remove(Object key) {
Object k = maskNull(key);
// 获取哈希值。
int h = HashMap.hash(k.hashCode());
Entry[] tab = getTable();
int i = indexFor(h, tab.length);
Entry<K,V> prev = tab[i];
Entry<K,V> e = prev;
// 删除链表中“键为key”的元素
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
if (h == e.hash && eq(k, e.get())) {
modCount++;
size--;
if (prev == e)
tab[i] = next;
else
prev.next = next;
return e.value;
}
prev = e;
e = next;
}
return null;
}
// 删除“键值对”
Entry<K,V> removeMapping(Object o) {
if (!(o instanceof Map.Entry))
return null;
Entry[] tab = getTable();
Map.Entry entry = (Map.Entry)o;
Object k = maskNull(entry.getKey());
int h = HashMap.hash(k.hashCode());
int i = indexFor(h, tab.length);
Entry<K,V> prev = tab[i];
Entry<K,V> e = prev;
// 删除链表中的“键值对e”
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
if (h == e.hash && e.equals(entry)) {
modCount++;
size--;
if (prev == e)
tab[i] = next;
else
prev.next = next;
return e;
}
prev = e;
e = next;
}
return null;
}
// 清空WeakHashMap,将所有的元素设为null
public void clear() {
while (queue.poll() != null)
;
modCount++;
Entry[] tab = table;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
size = 0;
while (queue.poll() != null)
;
}
// 是否包含“值为value”的元素
public boolean containsValue(Object value) {
// 若“value为null”,则调用containsNullValue()查找
if (value==null)
return containsNullValue();
// 若“value不为null”,则查找WeakHashMap中是否有值为value的节点。
Entry[] tab = getTable();
for (int i = tab.length ; i-- > 0 ;)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
// 是否包含null值
private boolean containsNullValue() {
Entry[] tab = getTable();
for (int i = tab.length ; i-- > 0 ;)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (e.value==null)
return true;
return false;
}
// Entry是单向链表。
// 它是 “WeakHashMap链式存储法”对应的链表。
// 它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数
private static class Entry<K,V> extends WeakReference<K> implements Map.Entry<K,V> {
private V value;
private final int hash;
// 指向下一个节点
private Entry<K,V> next;
// 构造函数。
Entry(K key, V value,
ReferenceQueue<K> queue,
int hash, Entry<K,V> next) {
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
public K getKey() {
return WeakHashMap.<K>unmaskNull(get());
}
public V getValue() {
return value;
}
public V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断两个Entry是否相等
// 若两个Entry的“key”和“value”都相等,则返回true。
// 否则,返回false
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 实现hashCode()
public int hashCode() {
Object k = getKey();
Object v = getValue();
return ((k==null ? 0 : k.hashCode()) ^
(v==null ? 0 : v.hashCode()));
}
public String toString() {
return getKey() + "=" + getValue();
}
}
// HashIterator是WeakHashMap迭代器的抽象出来的父类,实现了公共了函数。
// 它包含“key迭代器(KeyIterator)”、“Value迭代器(ValueIterator)”和“Entry迭代器(EntryIterator)”3个子类。
private abstract class HashIterator<T> implements Iterator<T> {
// 当前索引
int index;
// 当前元素
Entry<K,V> entry = null;
// 上一次返回元素
Entry<K,V> lastReturned = null;
// expectedModCount用于实现fast-fail机制。
int expectedModCount = modCount;
// 下一个键(强引用)
Object nextKey = null;
// 当前键(强引用)
Object currentKey = null;
// 构造函数
HashIterator() {
index = (size() != 0 ? table.length : 0);
}
// 是否存在下一个元素
public boolean hasNext() {
Entry[] t = table;
// 一个Entry就是一个单向链表
// 若该Entry的下一个节点不为空,就将next指向下一个节点;
// 否则,将next指向下一个链表(也是下一个Entry)的不为null的节点。
while (nextKey == null) {
Entry<K,V> e = entry;
int i = index;
while (e == null && i > 0)
e = t[--i];
entry = e;
index = i;
if (e == null) {
currentKey = null;
return false;
}
nextKey = e.get(); // hold on to key in strong ref
if (nextKey == null)
entry = entry.next;
}
return true;
}
// 获取下一个元素
protected Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextKey == null && !hasNext())
throw new NoSuchElementException();
lastReturned = entry;
entry = entry.next;
currentKey = nextKey;
nextKey = null;
return lastReturned;
}
// 删除当前元素
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
WeakHashMap.this.remove(currentKey);
expectedModCount = modCount;
lastReturned = null;
currentKey = null;
}
}
// value的迭代器
private class ValueIterator extends HashIterator<V> {
public V next() {
return nextEntry().value;
}
}
// key的迭代器
private class KeyIterator extends HashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
// Entry的迭代器
private class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
// WeakHashMap的Entry对应的集合
private transient Set<Map.Entry<K,V>> entrySet = null;
// 返回“key的集合”,实际上返回一个“KeySet对象”
public Set<K> keySet() {
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
// Key对应的集合
// KeySet继承于AbstractSet,说明该集合中没有重复的Key。
private class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return new KeyIterator();
}
public int size() {
return WeakHashMap.this.size();
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
if (containsKey(o)) {
WeakHashMap.this.remove(o);
return true;
}
else
return false;
}
public void clear() {
WeakHashMap.this.clear();
}
}
// 返回“value集合”,实际上返回的是一个Values对象
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null ? vs : (values = new Values()));
}
// “value集合”
// Values继承于AbstractCollection,不同于“KeySet继承于AbstractSet”,
// Values中的元素能够重复。因为不同的key可以指向相同的value。
private class Values extends AbstractCollection<V> {
public Iterator<V> iterator() {
return new ValueIterator();
}
public int size() {
return WeakHashMap.this.size();
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
WeakHashMap.this.clear();
}
}
// 返回“WeakHashMap的Entry集合”
// 它实际是返回一个EntrySet对象
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
// EntrySet对应的集合
// EntrySet继承于AbstractSet,说明该集合中没有重复的EntrySet。
private class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator();
}
// 是否包含“值(o)”
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k = e.getKey();
Entry candidate = getEntry(e.getKey());
return candidate != null && candidate.equals(e);
}
// 删除“值(o)”
public boolean remove(Object o) {
return removeMapping(o) != null;
}
// 返回WeakHashMap的大小
public int size() {
return WeakHashMap.this.size();
}
// 清空WeakHashMap
public void clear() {
WeakHashMap.this.clear();
}
// 拷贝函数。将WeakHashMap中的全部元素都拷贝到List中
private List<Map.Entry<K,V>> deepCopy() {
List<Map.Entry<K,V>> list = new ArrayList<Map.Entry<K,V>>(size());
for (Map.Entry<K,V> e : this)
list.add(new AbstractMap.SimpleEntry<K,V>(e));
return list;
}
// 返回Entry对应的Object[]数组
public Object[] toArray() {
return deepCopy().toArray();
}
// 返回Entry对应的T[]数组(T[]我们新建数组时,定义的数组类型)
public <T> T[] toArray(T[] a) {
return deepCopy().toArray(a);
}
}
}说明:
WeakHashMap和HashMap都是通过”拉链法”实现的散列表。它们的源码绝大部分内容都一样,这里就只是对它们不同的部分就是说明。
WeakReference是“弱键”实现的哈希表。它这个“弱键”的目的就是:实现对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
“弱键”是一个“弱引用(WeakReference)”,在Java中,WeakReference和ReferenceQueue 是联合使用的。在WeakHashMap中亦是如此:如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。 接着,WeakHashMap会根据“引用队列”,来删除“WeakHashMap中已被GC回收的‘弱键’对应的键值对”。
另外,理解上面思想的重点是通过 expungeStaleEntries() 函数去理解。
WeakHashMap遍历方式
4.1 遍历WeakHashMap的键值对
第一步:根据entrySet()获取WeakHashMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是WeakHashMap对象
// map中的key是String类型,value是Integer类型
Integer integ = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}4.2 遍历WeakHashMap的键
第一步:根据keySet()获取WeakHashMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是WeakHashMap对象
// map中的key是String类型,value是Integer类型
String key = null;
Integer integ = null;
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)map.get(key);
}
4.3 遍历WeakHashMap的值
第一步:根据value()获取WeakHashMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是WeakHashMap对象
// map中的key是String类型,value是Integer类型
Integer value = null;
Collection c = map.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}WeakHashMap示例
import java.util.Iterator;
import java.util.Map;
import java.util.WeakHashMap;
import java.util.Date;
import java.lang.ref.WeakReference;
/**
* @desc WeakHashMap测试程序
*
* @author skywang
* @email kuiwu-wang@163.com
*/
public class WeakHashMapTest {
public static void main(String[] args) throws Exception {
testWeakHashMapAPIs();
}
private static void testWeakHashMapAPIs() {
// 初始化3个“弱键”
String w1 = new String("one");
String w2 = new String("two");
String w3 = new String("three");
// 新建WeakHashMap
Map wmap = new WeakHashMap();
// 添加键值对
wmap.put(w1, "w1");
wmap.put(w2, "w2");
wmap.put(w3, "w3");
// 打印出wmap
System.out.printf("\nwmap:%s\n",wmap );
// containsKey(Object key) :是否包含键key
System.out.printf("contains key two : %s\n",wmap.containsKey("two"));
System.out.printf("contains key five : %s\n",wmap.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.printf("contains value 0 : %s\n",wmap.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
wmap.remove("three");
System.out.printf("wmap: %s\n",wmap );
// ---- 测试 WeakHashMap 的自动回收特性 ----
// 将w1设置null。
// 这意味着“弱键”w1再没有被其它对象引用,调用gc时会回收WeakHashMap中与“w1”对应的键值对
w1 = null;
// 内存回收。这里,会回收WeakHashMap中与“w1”对应的键值对
System.gc();
// 遍历WeakHashMap
Iterator iter = wmap.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry en = (Map.Entry)iter.next();
System.out.printf("next : %s - %s\n",en.getKey(),en.getValue());
}
// 打印WeakHashMap的实际大小
System.out.printf(" after gc WeakHashMap size:%s\n", wmap.size());
}
}
/*
wmap:{three=w3, one=w1, two=w2}
contains key two : true
contains key five : false
contains value 0 : false
wmap: {one=w1, two=w2}
next : two - w2
after gc WeakHashMap size:1
*/Map总结
Map框架
Map的框架图。

Map概括
- Map 是“键值对”映射的抽象接口。
- AbstractMap 实现了Map中的绝大部分函数接口。它减少了“Map的实现类”的重复编码。
- SortedMap 有序的“键值对”映射接口。
- NavigableMap 是继承于SortedMap的,支持导航函数的接口
- HashMap, Hashtable, TreeMap, WeakHashMap这4个类是“键值对”映射的实现类。它们各有区别!
HashMap 是基于“拉链法”实现的散列表。一般用于单线程程序中。
Hashtable也是基于“拉链法”实现的散列表。它一般用于多线程程序中。
WeakHashMap 也是基于“拉链法”实现的散列表,它一般也用于单线程程序中。相比HashMap,WeakHashMap中的键是“弱键”,当“弱键”被GC回收时,它对应的键值对也会被从WeakHashMap中删除;而HashMap中的键是强键。
TreeMap 是有序的散列表,它是通过红黑树实现的。它一般用于单线程中存储有序的映射。
HashMap和Hashtable异同
相同点
HashMap和Hashtable都是存储“键值对(key-value)”的散列表,而且都是采用拉链法实现的。
存储的思想都是:通过table数组存储,数组的每一个元素都是一个Entry;而一个Entry就是一个单向链表,Entry链表中的每一个节点就保存了key-value键值对数据。
添加key-value键值对:首先,根据key值计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据数组索引找到Entry(即,单向链表),再遍历单向链表,将key和链表中的每一个节点的key进行对比。若key已经存在Entry链表中,则用该value值取代旧的value值;若key不存在Entry链表中,则新建一个key-value节点,并将该节点插入Entry链表的表头位置。
删除key-value键值对:删除键值对,相比于“添加键值对”来说,简单很多。首先,还是根据key计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据索引找出Entry(即,单向链表)。若节点key-value存在与链表Entry中,则删除链表中的节点即可。
上面介绍了HashMap和Hashtable的相同点。正是由于它们都是散列表,我们关注更多的是“它们的区别,以及它们分别适合在什么情况下使用”。那接下来,我们先看看它们的区别。
* 不同点*
1 继承和实现方式不同
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
HashMap的定义:
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable { ... }Hashtable的定义:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { ... }从中,我们可以看出:
1.1 HashMap和Hashtable都实现了Map、Cloneable、java.io.Serializable接口。
实现了Map接口,意味着它们都支持key-value键值对操作。支持“添加key-value键值对”、“获取key”、“获取value”、“获取map大小”、“清空map”等基本的key-value键值对操作。
实现了Cloneable接口,意味着它能被克隆。
实现了java.io.Serializable接口,意味着它们支持序列化,能通过序列化去传输。
1.2 HashMap继承于AbstractMap,而Hashtable继承于Dictionary
Dictionary是一个抽象类,它直接继承于Object类,没有实现任何接口。Dictionary类是JDK 1.0的引入的。虽然Dictionary也支持“添加key-value键值对”、“获取value”、“获取大小”等基本操作,但它的API函数比Map少;而且 Dictionary一般是通过Enumeration(枚举类)去遍历,Map则是通过Iterator(迭代器)去遍历。 然而‘由于Hashtable也实现了Map接口,所以,它即支持Enumeration遍历,也支持Iterator遍历。关于这点,后面还会进一步说明。
AbstractMap是一个抽象类,它实现了Map接口的绝大部分API函数;为Map的具体实现类提供了极大的便利。它是JDK 1.2新增的类。
2 线程安全不同
Hashtable的几乎所有函数都是同步的,即它是线程安全的,支持多线程。
而HashMap的函数则是非同步的,它不是线程安全的。若要在多线程中使用HashMap,需要我们额外的进行同步处理。 对HashMap的同步处理可以使用Collections类提供的synchronizedMap静态方法,或者直接使用JDK 5.0之后提供的java.util.concurrent包里的ConcurrentHashMap类。
3 对null值的处理不同
HashMap的key、value都可以为null。当HashMap的key为null时,HashMap会将其固定的插入table[0]位置(即HashMap散列表的第一个位置);而且table[0]处只会容纳一个key为null的值,当有多个key为null的值插入的时候,table[0]会保留最后插入的value
Hashtable的key、value都不可以为null。否则,会抛出异常NullPointerException。
4 支持的遍历种类不同
HashMap只支持Iterator(迭代器)遍历。
而Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。
Enumeration 是JDK 1.0添加的接口,只有hasMoreElements(), nextElement() 两个API接口,不能通过Enumeration()对元素进行修改 。
而Iterator 是JDK 1.2才添加的接口,支持hasNext(), next(), remove() 三个API接口。HashMap也是JDK 1.2版本才添加的,所以用Iterator取代Enumeration,HashMap只支持Iterator遍历。
5 通过Iterator迭代器遍历时,遍历的顺序不同
HashMap是“从前向后”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
Hashtable是“从后往前”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
HashMap 和Hashtable 遍历”key-value集合”的方式是:(01) 通过entrySet()获取“Map.Entry集合”。 (02) 通过iterator()获取“Map.Entry集合”的迭代器,再进行遍历。
HashMap的实现方式:先“从前向后”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
// 返回“HashMap的Entry集合”
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
// 返回“HashMap的Entry集合”,它实际是返回一个EntrySet对象
private Set<Map.Entry<K,V>> entrySet0() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
// EntrySet对应的集合
// EntrySet继承于AbstractSet,说明该集合中没有重复的EntrySet。
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
...
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator();
}
...
}
// 返回一个“entry迭代器”
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
// Entry的迭代器
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
private abstract class HashIterator<E> implements Iterator<E> {
// 下一个元素
Entry<K,V> next;
// expectedModCount用于实现fail-fast机制。
int expectedModCount;
// 当前索引
int index;
// 当前元素
Entry<K,V> current;
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
// 将next指向table中第一个不为null的元素。
// 这里利用了index的初始值为0,从0开始依次向后遍历,直到找到不为null的元素就退出循环。
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
// 获取下一个元素
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
// 注意!!!
// 一个Entry就是一个单向链表
// 若该Entry的下一个节点不为空,就将next指向下一个节点;
// 否则,将next指向下一个链表(也是下一个Entry)的不为null的节点。
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
...
}Hashtable的实现方式:先从“后向往前”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
public Set<Map.Entry<K,V>> entrySet() {
if (entrySet==null)
entrySet = Collections.synchronizedSet(new EntrySet(), this);
return entrySet;
}
private class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return getIterator(ENTRIES);
}
...
}
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
// 指向Hashtable的table
Entry[] table = Hashtable.this.table;
// Hashtable的总的大小
int index = table.length;
Entry<K,V> entry = null;
Entry<K,V> lastReturned = null;
int type;
// Enumerator是 “迭代器(Iterator)” 还是 “枚举类(Enumeration)”的标志
// iterator为true,表示它是迭代器;否则,是枚举类。
boolean iterator;
// 在将Enumerator当作迭代器使用时会用到,用来实现fail-fast机制。
protected int expectedModCount = modCount;
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
// 从遍历table的数组的末尾向前查找,直到找到不为null的Entry。
public boolean hasMoreElements() {
Entry<K,V> e = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
}
// 获取下一个元素
// 注意:从hasMoreElements() 和nextElement() 可以看出“Hashtable的elements()遍历方式”
// 首先,从后向前的遍历table数组。table数组的每个节点都是一个单向链表(Entry)。
// 然后,依次向后遍历单向链表Entry。
public T nextElement() {
Entry<K,V> et = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
Entry<K,V> e = lastReturned = entry;
entry = e.next;
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
// 迭代器Iterator的判断是否存在下一个元素
// 实际上,它是调用的hasMoreElements()
public boolean hasNext() {
return hasMoreElements();
}
// 迭代器获取下一个元素
// 实际上,它是调用的nextElement()
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
}
...
}6 容量的初始值 和 增加方式都不一样
HashMap默认的容量大小是16;增加容量时,每次将容量变为“原始容量x2”。
Hashtable默认的容量大小是11;增加容量时,每次将容量变为“原始容量x2 + 1”。
HashMap默认的“加载因子”是0.75, 默认的容量大小是16。
// 默认的初始容量是16,必须是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}当HashMap的 “实际容量” >= “阈值”时,(阈值 = 总的容量 * 加载因子),就将HashMap的容量翻倍。
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}Hashtable默认的“加载因子”是0.75, 默认的容量大小是11。
// 默认构造函数。
public Hashtable() {
// 默认构造函数,指定的容量大小是11;加载因子是0.75
this(11, 0.75f);
}当Hashtable的 “实际容量” >= “阈值”时,(阈值 = 总的容量 x 加载因子),就将变为“原始容量x2 + 1”。
// 调整Hashtable的长度,将长度变成原来的(2倍+1)
// (01) 将“旧的Entry数组”赋值给一个临时变量。
// (02) 创建一个“新的Entry数组”,并赋值给“旧的Entry数组”
// (03) 将“Hashtable”中的全部元素依次添加到“新的Entry数组”中
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
int newCapacity = oldCapacity * 2 + 1;
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)(newCapacity * loadFactor);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}7 添加key-value时的hash值算法不同
HashMap添加元素时,是使用自定义的哈希算法。
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
HashMap添加元素时,是使用自定义的哈希算法。
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
addEntry(hash, key, value, i);
return null;
}Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// (03) 将“Hashtable中index”位置的Entry(链表)保存到e中
Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
}8 部分API不同
Hashtable支持contains(Object value)方法,而且重写了toString()方法;
而HashMap不支持contains(Object value)方法,没有重写toString()方法。
最后,再说说“HashMap和Hashtable”使用的情景。
其实,若了解它们之间的不同之处后,可以很容易的区分根据情况进行取舍。例如:(01) 若在单线程中,我们往往会选择HashMap;而在多线程中,则会选择Hashtable。(02),若不能插入null元素,则选择Hashtable;否则,可以选择HashMap。
但这个不是绝对的标准。例如,在多线程中,我们可以自己对HashMap进行同步,也可以选择ConcurrentHashMap。当HashMap和Hashtable都不能满足自己的需求时,还可以考虑新定义一个类,继承或重新实现散列表;当然,一般情况下是不需要的了。
HashMap和WeakHashMap异同
相同点
- 它们都是散列表,存储的是“键值对”映射。
- 它们都继承于AbstractMap,并且实现Map基础。
- 它们的构造函数都一样。
- 它们都包括4个构造函数,而且函数的参数都一样。
- 默认的容量大小是16,默认的加载因子是0.75。
- 它们的“键”和“值”都允许为null。
- 它们都是“非同步的”。
不同点
1 HashMap实现了Cloneable和Serializable接口,而WeakHashMap没有。
HashMap实现Cloneable,意味着它能通过clone()克隆自己。
HashMap实现Serializable,意味着它支持序列化,能通过序列化去传输。
2 HashMap的“键”是“强引用(StrongReference)”,而WeakHashMap的键是“弱引用(WeakReference)”。
WeakReference的“弱键”能实现WeakReference对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
这个“弱键”实现的动态回收“键值对”的原理呢?其实,通过WeakReference(弱引用)和ReferenceQueue(引用队列)实现的。 首先,我们需要了解WeakHashMap中:
第一,“键”是WeakReference,即key是弱键。
第二,ReferenceQueue是一个引用队列,它是和WeakHashMap联合使用的。当弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。 WeakHashMap中的ReferenceQueue是queue。
第三,WeakHashMap是通过数组实现的,我们假设这个数组是table。
接下来,说说“动态回收”的步骤。
- 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
将“键值对”添加到WeakHashMap中时,添加的键都是弱键。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到queue队列中。
例如,当我们在将“弱键”key添加到WeakHashMap之后;后来将key设为null。这时,便没有外部外部对象再引用该了key。 接着,当Java虚拟机的GC回收内存时,会回收key的相关内存;同时,将key添加到queue队列中。当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的“弱键”;同步它们,就是删除table中被GC回收的“弱键”对应的键值对。
例如,当我们“读取WeakHashMap中的元素或获取WeakReference的大小时”,它会先同步table和queue,目的是“删除table中被GC回收的‘弱键’对应的键值对”。删除的方法就是逐个比较“table中元素的‘键’和queue中的‘键’”,若它们相当,则删除“table中的该键值对”。















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









