






C++应用程序开发中离不开预处理程序。预处理程序实际上是从C语言中继承而来。预处理程序在应用程序正式编译之前预先完成。C++编译器有专门内置的预处理器。本章将会就预处理相关的指令作详细介绍。
15.1 C++预处理简介
预处理指令并不属于C++语言中的语法关键字范畴。所有预处理指令定义都不需要以分号为结尾。预处理指令大多都以#符号开头。许多高级语言都不包含预处理器的实现,但C++作为一门优秀语言,包含了多种编程风格。它很好地吸收了C语言中的特色——预处理指令。
预处理指令由C++编译器中的预处理器模块处理。该预处理器可以识别应用程序中的#号开头的预处理指令,并在编译之前对其作出相应的处理。所有的预处理指令需要注意的是不能以分号为结尾,这是因为预处理指令不是C++语句。而配合预处理指令开头的#号用来区分普通应用程序语句与预处理指令语句。需要注意的是,预处理指令以#号开始,并且#号之前不允许有任何的空白字符。下面可以通过一个简单的预处理指令定义实例,了解基本预处理在应用程序中使用情况。
#define PI 3.1415926 //定义宏为PI,对应值为常量3.1415926
int main()
{
doubler; //定义double型变量,表示圆的半径
cout<<”Pleaseinput r:”<<endl; //提示从键盘输入圆半径
cin>>r; //输入圆半径变量
cout<<”Circlearea:”<<PI*r*r<<endl; //打印输出圆面积计算表达式的值
return0;
}
上述实例中使用宏预处理指令,定义PI值应用于圆面积的计算。预处理指令define用于定义PI之类的特殊符号,用以表示特定处理的数值。这样就可以避免在应用程序中使用时每次都需要编写一遍。这样,当需要修改对应的值时,只需要在预处理指令定义处修改一次。
上述#define预处理指令通过预处理器在应用程序编译之前先处理,即编译器编译程序前已经确定预处理中的指令处理,编译程序中调用时再自行展开即可。下面将会就预处理程序提供的各类处理指令作详细讲述。
15.2 C++预处理指令
预处理程序通过预处理器的内置功能对相应的指令进行预先处理。预处理指令提供了一系列的指令。通过归纳,这些提供的预处理指令分为文件包含、条件编译、布局控制与宏定义四种。下面将会就这四类指令作详细介绍。
15.2.1 预处理文件包含指令
C++预处理包含指令为#include。通常大型的软件应用程序不是由孤立的源文件组成。大部分都是以多文件并结合相应的代码管理最终协调运行。#include指令的出现,可以允许开发者包含使用C++标准库中提供的函数接口与类方法接口文件。另外,开发者也可以包含使用用户自定义库或者组件代码文件供实际模块程序使用。
#include预处理指令是在应用程序包含处将被包含的文件代码展开。大型软件系统的代码文件会分成多个。一般函数的声明、一些公用的常量、枚举、结构体、类的类型的定义等比较稳定。同时,有y经常有一些不需要经常修改的接口定义。这时,会将其放入后缀为.h的头文件中实现。而函数的定义,类中方法成员等具体实现放入源代码文件.cpp中。这样,头文件中包含了稳定不经常修改的代码,并且提供了接口的声明。在具体的包含源文件中可以包含该头文件定义实现具体接口或者直接调用,使得程序编译速度提高的同时又方便程序的管理。#include指令在C++应用程序中通常主要包含两类文件的包含。
q 一类是标准库提供的头文件。通常标准库对外提供的代码接口仅仅通过其头文件对外开放使用,具体源代码实现一般不需要开放,也不需要开发者关心。C++中标准库头文件为无任何后缀的代码文件。该文件中主要声明了供应用程序使用的方法接口,应用的开发者只需要将其头文件通过#include命令进行包含,另外也需要在程序编译时连接这些库。
q 第二类是用户自定义实现的库。一般参照标准库实现的方式,将用户的应用程序进行划分。同样提供的库代码也分为头文件和源文件两个部分,如用户程序中自定义的组件、功能库等。这类库的使用也是可以通过包含其头文件,连接到相应库上就可以在具体应用中操作。
在具体应用中,这两类#include指令可以包含多种形式,如下所示。
#include <iostream> //标准库IO处理头文件
#include <string> //标准库字符串string处理头文件
#include “MyString.h” //自定义字符串类头文件
#include “../test/MyString.h” //包含对应目录下的头文件
从上述几行代码中可以看出,包含标准库头文件与包含普通用户自定义头文件区别在于#include指令后的包含形式。一对尖括号表示所要包含的头文件在实际应用中需要从标准库提供的路径开始搜索查找起;引号之间包含的头文件则为用户自定义头文件,使用时需要在用户的工作目录下搜索。默认情况下,在用户当前工作目录下查找。另外当在不同目录下时,也可以直接指定包含该目录下的头文件。
#include包含指令在应用程序中可以多次包含。同时,包含的头文件中又可以包含其它的文件,即多重包含。预处理过程不会针对同一个头文件在展开时检查多次包含情况。此时,C++预处理指令提供了条件编译指令于设定编译时的条件。
15.2.2 预处理条件编译指令
对上一小节头文件被多次包含的情形,条件编译指令提供了很好的解决方法。#ifndef指令针对多次包含同一头文件情况作出限制,如下所示。
#ifndef MYSTRING_H_
#define MYSTRING_H_
class MyString
{
//类接口声明定义
};
#endif
上述实例中,将前面自定义封装字符串实例头文件运用条件编译指令限制多次被包含的情形。一旦#ifndef后的特殊符号已经被定义,则程序处理时可以忽略随后的代码内容不再包含处理。在上例中MyString类封装定义的头文件中加上条件编译指令,在使用MyString头文件时包含该头文件。每次包含使用时需要检测#ifndef后定义的特殊符号。如果该符号没有被定义,则随后定义该特殊符号,紧接着包含该头文件使用。如果已经定义了特殊符号,则会忽略随后的头文件代码处理。
#ifndef指令以#endif标注为结尾,其中则放入头文件代码定义的内容。多次包含同一文件时,检测到事先已经定义过的特殊符号MYSTRING_H_。随后就忽略从#ifndef到#endif之间的定义从而避免重复包含。
除了#ifdef和#endif指令,预处理条件编译指令还包含#if、#ifndef、#else与#elif 4种。使用这些条件编译指令,可以使得应用程序中某部分代码在一定的条件下被忽略或者被处理。所以,条件编译指令可以用于编写在多种操作系统上运行的程序代码。下面将会详细的介绍条件编译指令的应用情况。
1.#if指令
#if指令通常配合#elif、#else以及结束标识#endif灵活地控制是否需要编译其中的代码块。#if指令随后的表达式如果为非零,则对随后的代码进行编译。下面通过一个实际应用了解该指令运用情况。
#if expression1
… //代码块
#elif expression2
… //代码块
#else
… //代码块
#endif
上述代码小片段中首先判断#if指令后的条件表达式结果是否为真。例如,该指令后的表达式已经定义过则表明该条件表达式判断为真。随后#if后的代码块将会被包含入应用程序进行编译。如果#if指令后的条件表达式没有被定义,则表明该条件表达式判断结果为假。随后进入下一个判断即#elif。同样,如果elif指令后的条件表达式为真,则编译之后的代码块。直到前面条件表达式判断都为假的时候,则执行默认编译指令#else随后的代码块编译。
2.#ifdef
#ifdef指令不同之处在于其随后的标识符。#ifdef指令判断随后定义的标识符是否已经通过#define语句定义。如果已经定义,则将随后的代码块纳入程序编译的范围之内;否则,随后的代码块将会被忽略。上述定义实例方式使用#ifdef编译指令则如下所示。
#ifdef identifier1
… //代码块
#elif identifier2
… //代码块
#else
… //代码块
#endif
#ifdef与#if指令使用格式相同,同样是以#endif为结束标识。期间可以根据选择控制的判断情况将对应的代码块纳入应用程序编译范围中。与#if指令不同的是,#ifdef指令则是根据随后的标识符号是否定义来判断,从而将后续的代码块纳入应用程序中进行编译。上述实例中首先判断#ifdef指令后的标识符identifier1之前有没有定义。如果已经定义,则将随后的代码块纳入编译范围并直接转移至#endif之后。如果没有定义,则向下继续进行判断。最后如果前面判断条件都不成立,则将#else后的代码块直接纳入应用程序编译范围中。
与#ifdef编译指令相反的是,#ifndef编译指令则表明随后的标识符号如果没有被定义则将随后包含的代码块加入应用程序编译范围。如果之前标识符号已经被定义过则将忽略随后包含的代码块。#ifndef条件编译指令最常见得应用是解决同一头文件被多次包含的情况。一旦#ifndef随后的标识符号没有被定义过,则证明该头文件在本应用程序中首次被包含使用,需要纳入应用程序编译中。而如果随后的标识符号已经被定义过,即证明其头文件可能在之前已经被包含。
15.2.3 预处理指令:常量符号定义
C++语言继承了C语言中宏的使用概念,#define预处理指令也称为宏定义语句。它主要用于在应用程序中定义符号常量。C++中#define定义常量符号方式与本身该语言提供的const功能类似。通常,提倡使用const关键字定义常量,并加入应用程序使用。理由之一就是#define属于预处理器处理,不是语言提供的支持。很多时候,宏的复杂定义使用容易出错,而编译器不能很好的作出提示。但是#define宏指令的使用不仅仅针对常量符号,它有着更广阔的应用空间。在很多情况下,应用#define指令处理可以简化应用程序,提高程序的处理效率。
本小节主要讲述#define指令针对常量符号使用情况。更多宏的应用将会在后续章节介绍。下面通过一些基本的常量符号定义实例应用来了解#define指令的基本操作情况。
#define PI 3.14 //定义常量符号PI,表示圆周率
double area; //定义浮点型变量,表示圆面积
area = PI*r*r; //根据已经定义的PI常量计算圆面积
#define MAXLEN 100 //定义常量符号MAXLEN,表示数组定义最大长度
char array[MAXLEN]; //定义长度为MAXLEN长度的字符数组array
for(int i = 0;i < MAXLEN;i++) //根据数组最大长度作出相应循环处理
{
…
}
上述代码中,首先根据#define指令定义常量符号PI表示圆面积计算的圆周率。由于圆周率在现实计算应用中是保持不变的常量值,采用PI常量符号表示可以保持代码可读性。随后在应用程序中就可以应用PI常量符号,使用时直接展开使用对应的常量值替换即可。第二种使用方式应用于数组长度的表示。由于数组定义时,通常必须静态地确定其大小,从而让编译器静态分配内存空间。采用常量符号表示后,将通用的数组大小定义直接使用该符号来表示。例如,应用程序中处理数据需要的缓冲区定长设定,则可以采用#define预先定义常量符号表示其具体缓冲区大小。这样,在各处使用的缓冲区可以保持一致不易出错,同时修改也更加方便。
#define指令不仅可以定义常量符号,还可以定义常量表达式,即#define指令后常量符号对应的值可以是直接的常量数值,也可以是计算结果最终为常量数值的表达式。如下实例中,则定义常量表达式对应的符号。
#define symbol1 10
#define symbol2 100
#define symbol3 (symbol1*symbol2)
如上定义中symbol3直接为前两个常量符号计算结果的表示,并在应用程序中展开使用。下一节将会对宏定义带参数处理等更复杂的情形作详细的介绍。
15.3 宏定义
由于宏定义处理为C语言提供了一个功能强大的处理工具,C++语言中保留并支持了这一工具。这一方面是为了兼容更多现有的C程序,另一方面也是为了吸收了C语言相关处理的优点。前面小节已经就宏定义中常量符号的基本应用情况作了简单介绍,下面将会介绍宏定义处理中的复杂应用情形。
15.3.1 更多表达式宏定义
前面讲述#define指令时已经介绍过,宏定义的常量符号仅仅为其中一种应用。#define语句之后不仅仅可以定义对应的常量符号表示形式,另外也可以包含相应的表达式。表达式不仅可以是简单的常量表达式,也可以是为了实现某种基本功能而较为复杂的表达式。下面通过几个宏定义符号表示表达式情形的应用,了解宏定义中表达式表示操作的方式。
大型的生产系统中都会针对不同的业务模块处理制定相应的错误代码。这些代码用于标识不同的错误情况,便于程序出错时统一检查。错误代码通常可以根据需要划分为不同的段,每个段都有一个对应的起始错误号。以下代码首先定义ERROR_BASE符号表示框架文件中错误代码段的基数,随后根据不同的错误形式定义对应的常量符号表示。该常量符号所对应的即为常量表达式计算结果。上述实例中主要用于递增表示不同的错误类型代码。
#define ERROR_BASE 100 //宏定义错误代码中应用
#define E_SYSNOTIFY_STARTUP ERROR_BASE+1
#define EAPPFRM_SYSINIT ERROR_BASE+2
…
同时宏定义中可以使用有意义的标识符号来表示相应的运算符号。以下代码则为定义清晰的符号表示对应的运算符,参与实际应用程序处理。这里主要定义了三类逻辑运算符,在应用程序中可以直接使用表示符号,并在对应处直接展开所表示的运算符。
#define AND && //宏定义标识符表示运算符参与运算
#define OR ||
#define EQUAL ==
if(value1 AND value2)
{
… //代码块
}
if(value == 10 OR value == 100)
{
… //代码块
}
…
以下代码则直接将移位运算采用宏定义标识符号表示。<<10表示将操作数左移10位,实例中定义符号LEFT_DEVIATION_10表示该操作,随后在应用程序中value2LEFT_DEVIATION_10该语句运行时直接通过展开预定义左移10位的操作符参与运算,则表示将value2左移10位并给value1赋值。
#define LEFT_DEVIATION_10 <<10 //宏定义标识符表示移位运算
value1 = value2 LEFT_DEVIATION_10;
…
以下代码主要演示了宏定义中操作复杂表达式的情形。通常闰年的计算方式可以通过以下的表达式计算来判断相应的年份是否为闰年。由于闰年的计算算法为每四年一闰,其中百年不闰四百年再闰。即闰年年份应该为除尽4并且不能被100除尽;另外,能够被400除尽也表示闰年。上述实例采用宏定义常量符号LEAP_YEAR,表示随后复杂的表达式。符号LEAP_YEAR在应用程序中可以直接用来判断对应表达式计算结果真假,根据判断结果来表示是否为闰年年份。
#define LEAP_YEAR year % 4 == 0 && year %100 != 0 || year % 400 == 0
if(LEAP_YEAR) //如果是闰年则执行if结构中的代码块
{
… //代码块
}
15.3.2 带参数的宏定义
上述实例中第四个采用宏定义表示闰年的实现方式有一个不足之处。year必须是事先定义的常量符号,这就限制了操作时候的灵活性。而宏定义中常量符号表示的表达式可以通过增加接受外部程序参数传入的方式,类似于函数的使用方式。这样就让宏定义具有更强的功能。
判断年份是否闰年的基本算法前面已经介绍过,下面将会通过定义带参数year的宏定义来实现。
#define LEAP_YEAR(year) year % 4 ==0 && year % 100!=0 || year% 400 ==0
if(LEAP_YEAR(year))
{
… //代码块
}
上述实现方式中,将year作为宏定义符号LEAP_YEAR的参数,并使用圆括号包含。随后,依然是闰年判断计算表达式定义。应用程序实际使用中只需要使用符号LEAP_YEAR同时带有相应的实参表示其年份即可。由于宏定义的符号在预处理程序中是进行直接的替换,所以事先year并不需要声明其类型,只需要在实际应用中直接给出值即可。实际应用程序判断中,直接将该符号表示的表达式展开,采用传入的year参数来带入该表达式进行计算判断。
这种带参数的宏定义方式使得宏具有可操作更多应用的能力。与函数相比,其优势在于不需要事先声明该参数。但是,同时带来一个缺点,即程序在编译过程中缺少了编译器层的函数参数类型检查。一旦出现错误,就比较的隐蔽,不容易察觉。
下面将会通过一些带参数宏定义实例,帮助读者更多地了解宏定义带参数应用情况,实例如下。
1.准备实例
打开UE工具,创建新的空文件并且另存为chapter1501_01.h、chapter1501_01.cpp。该代码文件随后会同makefile文件一起通过FTP工具传输至Linux服务器端,客户端通过scrt工具访问操作。程序代码文件编辑如下所示。
/**
* 实例chapter1501
* 源文件chapter1501_01.cppchapter1501_01.h
* 宏定义使用演示
*/
//带参数宏定义头文件chapter1501_01.h
#ifndef MACROPARAMETER_H_
#define MACROPARAMETER_H_
#include <iostream>
using namespace std;
#define add(a,b) a+b //加法计算宏定义
#define cube(x) x*x*x //立方计算宏定义
#define max(a,b) (((a)>(b))?(a):(b)) //大小比较计算宏定义
#define LEAP_YEAR(year) year%4==0 &&year%100!=0\ //闰年计算宏定义
||year%400==0
#endif
//带参数宏定义源文件chapter1501_01.cpp
#include "chapter1501_01.h"
int main()
{
inta,b,year; //定义3个整型变量
a =6; //整型变量a赋初值6
b =7; //整型变量b赋初值7
year= 2008; //整型变量year赋初值2008
cout<<"a+b:"<<add(a,b)<<endl; //调用加法计算宏,打印输出其结果
cout<<"acube:"<<cube(a)<<endl; //调用立方计算宏,打印输出其结果
cout<<"maxa and b:"<<max(a,b)<<endl; //调用大小比较计算宏,打印输出其结果
if(LEAP_YEAR(year)) //调用闰年计算宏,判断输入年份是否闰年
{
cout<<year<<"is a leap year!"<<endl; //如果闰年则打印闰年信息
}
else
cout<<year<<"is not a leap year!"<<endl; //否则打印不闰年信息
return0;
}
本实例通过宏定义的方式,将闰年计算公式定义为宏常量,在应用程序中演示宏常量的一般使用方法。程序主要在主函数中完成,程序具体剖析见程序注释与后面讲解。
2.编辑makefile
Linux平台下需要编译源文件为chapter1501_01.cpp,相关makefile工程文件编译命令编辑如下所示。
OBJECTS=chapter1501_01.o
CC=g++
chapter1501_01: $(OBJECTS)
$(CC)$(OBJECTS) -g -o chapter1501_01
clean:
rm-f chapter1501_01 core $(OBJECTS)
submit:
cp-f -r chapter1501_01 ../bin
cp-f -r *.h ../include
上述makefile文件套用前面的模板格式,主要替换了代码文件、程序编译中间文件、可执行程序等。在编译命令部分-g选项的加入,表明程序编译同时加入了可调式信息。
3.编译运行程序
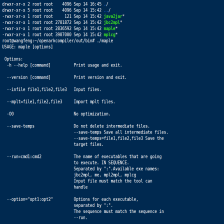
当前shell下执行make命令,生成可执行程序文件,随后通过make submit命令提交程序文件至本实例bin目录。通过cd命令定位至实例bin目录,执行该程序文件运行结果如下所示。
[developer@localhost src]$ make
g++ -c -ochapter1501_01.o chapter1501_01.cpp
g++ chapter1501_01.o -g -o chapter1501_01
[developer@localhost src]$ make submit
cp -f -r chapter1501_01 ../bin
cp -f -r *.h ../include
[developer@localhostsrc]$ cd ../bin
[developer@localhostbin]$ ./chapter1501_01
a+b:13
a cube:216
max a and b:7
2008 is a leap year!
本实例中首先将带参数的宏定义放入头文件代码中,供需要应用的应用程序直接包含使用。头文件中包含了4个带参数宏的定义。从本实例中看出宏可以带有多个参数定义,参数之间采用逗号分隔,类似于函数中的参数表定义方式。
带参数宏定义中参数表放入圆括号中,圆括号表示的参数表必须与定义的标识符号之间没有空格。否则,会被认为是后面的表达式定义。宏定义中常量符号与对应的表达式之间采用空格隔开,后面表达式定义之间为了统一代码风格可以使用空格。宏定义中凡是常量标识符空格后的任何表达式定义都视为所要表示的对象。
上述代码中总共有4个带参数宏定义实例,分别为add(两数加法操作符号)、cube(单数x立方计算符号)、max(两数大小比较符号)以及闰年计算的常量符号定义。4个实例中分别从单参数宏定义到多参数宏定义。另外也演示了同一个宏定义中,一旦需要换行的情形可以使用“\”符号。下面将会分析4个实例中宏定义情况,以及应用中应该注意的基本考虑点的说明。
1.add(a,b)
第一个宏定义中表示两数加法计算,add(a,b)表示宏定义的标识符。其中,a与b为宏标识符的参数,所要表示的表达式为a+b。最终在应用程序中调用出展开的形式即为传入的实参的a+b的表达式计算结果。当然,带参数的宏定义与函数区别在于参数使用上。宏定义中形参是不需要定义和分配内存空间的。只要在实参定义时,说明其基本类型然后分别去替换即可。主应用程序中首先定义两个整型变量a和b,并且赋上初值分别为6和7。调用处直接add(a,b)后,在其调用点展开的表达式为a+b,根据实参的值直接计算出结果。
宏中的参数替换,实参不仅仅可以为变量或者直接的常量数值,往往还可以为对应表达式的替换。例如,此时调用add(a+1,b+1),则应用程序替换中将会替换为a+1+b+1,最后直接计算其表达式结果。
2.cube(a)
第二个实例中为单参数宏定义,表示参数x的立方计算结果。主程序中根据传入的实参直接替换参数并计算其结果,调用处cube(a)其展开表达式为a*a*a即6的立方计算。此时需要注意的是,一旦在调用中采用表达式替换比如cube(a+1)时,原先开发者的本意是计算a+1后的立方计算。但是由于宏定义中的参数是直接替换计算,表达式为x*x*x传入的实参a值为6,替换后即为6+1*6+1*6+1,得不到预期的结果。
因此在定义带参数的宏时,最好将后面的表达式中参数采用括号标注。如果要达到上述计算的正确预期结果,宏定义中表达式应该为(x)*(x)*(x)。此时调用处展开的表达式为(a+1)*(a+1)*(a+1)即计算得到预期表达式a+1的立方结果。
3.cube(a+1)
第三个参数宏定义中则注意了表达式中替换参数的情况,将需要替换的参数在表达式中都采用括号单独括起来参与运算。该宏定义主要用于计算两数比较大小的结果,替换的表达式中应用条件运算符计算。此时应用程序调用中如果为cube(a+1)则能够计算得出预期结果。
4.闰年计算
最后一个带参数的宏定义为前面讲述过的闰年情况。参数year为需要检查的是否闰年的年份数。通过实参替换计算得出结果,从而判断是否为闰年年份。在宏定义中可以看出,代码书写中如果需要换行表示的话可以直接使用“\”表示即可。预处理程序遇到该符号会自动将下一行的代码定义连接到本行形成整体的表达式。上述实例中根据输入实参为2008年份数,判断其展开的表达式计算是否为真。如果为真,则表示2008为闰年年份。
15.3.3 #与##操作符的宏
预处理中“#”与“##”操作符有着特别的含义。“#”操作符加入带参数的宏定义中用于放置在表达式参数前,预处理见到#操作符后会将随后的参数生成对应的参数字符串。下面通过使用实例演示“#”操作符。
#define string(str) #str
cout<<string(teststring)<<endl;
上述代码实例中首先定义带参数的宏,符号为string其中参数为str。随后的表达式中“#”操作符后直接为参数。由于“#”操作符表示在应用中直接将参数展开为对应的字符串。随后的代码中采用cout输出对象打印调用宏定义符号的结果。此时传入的参数为teststring,“#”操作符作用即为转换对应的参数teststring为相应的字符串。此时打印输出的结果为字符串teststring。“#”操作符的作用即为将宏定义中的参数转换为对应的字符串。
操作符“##”其作用则是将两个参数符号连接起来,操作符的前后面都可以是对应的参数。下面依然通过一个宏定义实例来了解“##”操作符的基本使用情况,实例代码如下所示。
#define TEST(n) value ## n
#define PRINT_TEST(n) printf(“value” #n“=%d\n”,value ## n)
int TEST(1) = 100;
int TEST(2) = 200;
PRINT_TEST(1);
PRINT_TEST(2);
上述实例中首先定义宏TEST,带有参数n。随后表达式为value##n,此时程序中展开为valuen。其中,n为实参替换。第二个宏定义中同样参数为n。随后的表达式为一个pingtf打印输出的语句。该语句中首先为字符串value,紧跟着#n将实参n转化为字符串。双引号后为设定输出的格式为整型,最后将value与n连为一个新的字符串。
从上述的实例演示来看,“#”操作符用于将宏定义参数替换成对应的常量字符串,在实际应用中根据需要应用。“##”操作符则主要用于将两个符号连接起来,该操作符的前后都可以为宏参数。实际应用程序中展开会将“##”前后的参数符号连接起来创建一个新的符号用于处理。
15.4 小结
C++应用程序中,预处理指令应用的掌握非常重要。良好的可扩展性强的应用程序中,往往都少不了一定数量的预处理指令的使用。初学者刚开始接触这部分知识时可能暂无法深入领会,对于本章学习应该多写应用实例来体会预处理指令在应用程序中的作用,掌握预处理指令的一般使用方式。














 3484
3484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









