







 本文通过Java详细介绍了如何使用MapReduce实现单词计数,包括Mapper、Reducer阶段的代码实现,并给出了主程序的完整流程。
本文通过Java详细介绍了如何使用MapReduce实现单词计数,包括Mapper、Reducer阶段的代码实现,并给出了主程序的完整流程。
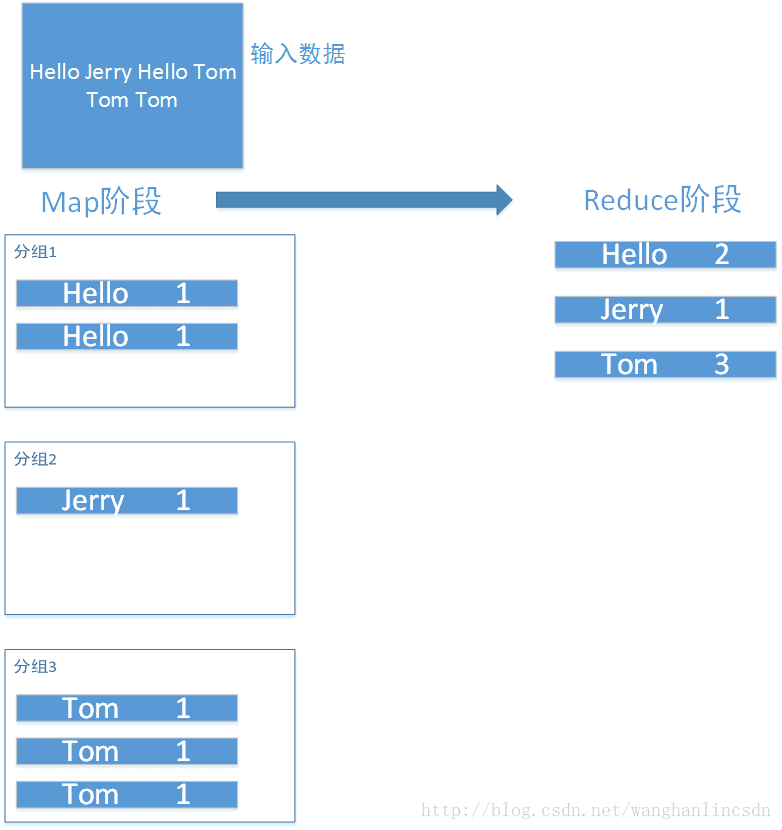
MapReduce实现单词计数示意图
MapReduce实现单词计数实例代码(Java)
①Mapper
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WM extends Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









