







一、目的
理解MapReduce在Hadoop体系结构中的角色,通过该实验后,能设计开发简单的MapReduce程序。
二、设备
计算机:CPU四核i7 6700处理器;内存8G; SATA硬盘2TB硬盘; Intel芯片主板;集成声卡、千兆网卡、显卡; 20寸液晶显示器。
编译环境:(1)操作系统:Linux (2)Hadoop版本:2.7.2 机器:虚拟机3台 (3)Eclipse 4.7
三、内容
3.1启动Hadoop服务
(1)格式化namenode。
(2)启动Hadoop。
[root@hadoop101 ~]# cd /opt/module/hadoop-2.7.2/
[root@hadoop101 hadoop-2.7.2]# sbin/./start-all.sh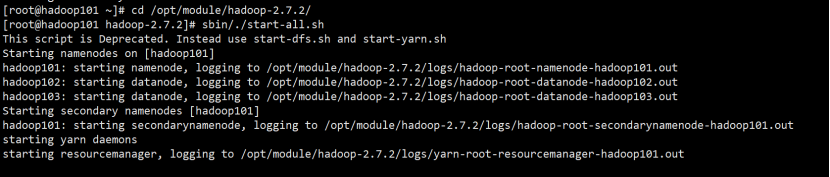
(3)用jps验证服务器服务是否启动成功。
[root@hadoop101 hadoop-2.7.2]# jps


3.2开发LineCount程序
(1)打开Eclipse开发工具,新建Maven项目。
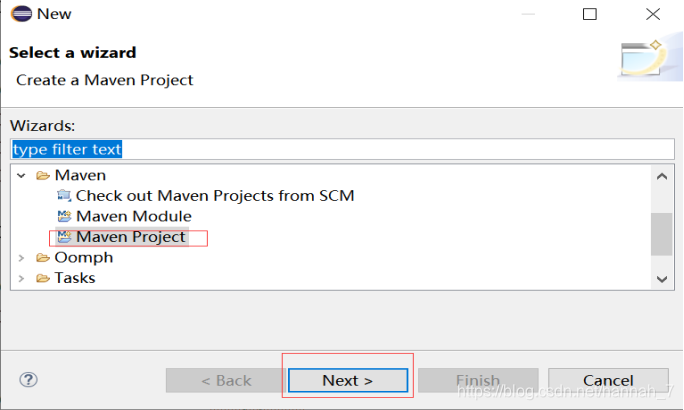
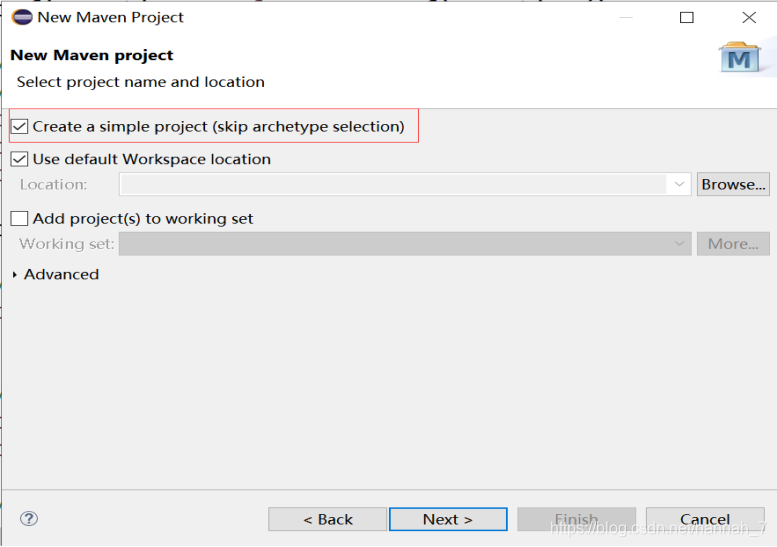
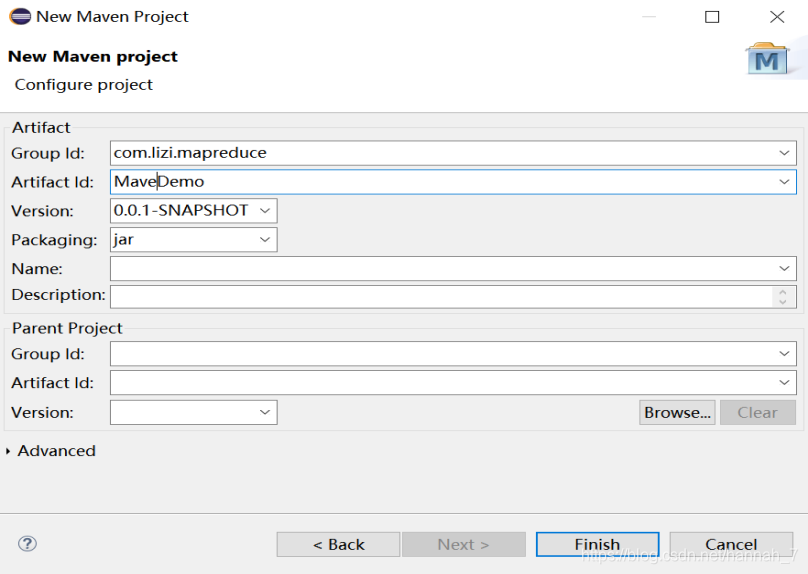
(2)WORDCOUNT代码
WordCountMapper:
package com.lizi.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到输入的这行数据 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









