









1.简介
crawler4j是一个开源的网络爬虫框架(github地址),可以帮助我们很快地实现一个最基本的网络爬虫。同时由于它的架构比较简单,整个项目只有几十个代码文件,并且完全实现了一个爬虫应该具有的所有基本单元。麻雀虽小,肝胆俱全。非常适合爬虫菜鸟来进行深入的学习。
2.环境搭建
2.1爬虫开发环境
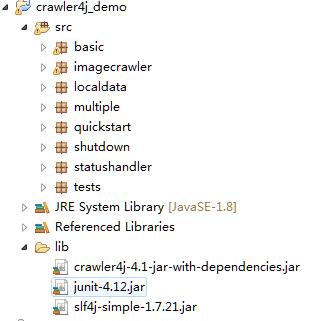
如果你只是想在你的爬虫项目中使用crawler4j,而不需要深入研究其源代码。可以直接下载(crawler4j-4.1-jar-with-dependencies.jar)。由于crawler4j和很多apache项目一样,都使用slf4j日志接口,所以需要添加额外的日志实现,一般可以使用log4j等日志系统。如下图所示(我使用的是sfl4j-simple日志实现)。
接下来可以把github上的demo代码复制到项目中,测试即可。亲手运行一下,才会有切身的体会。
2.2代码研究环境
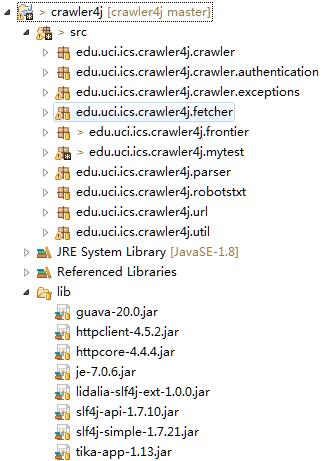
我们研究源代码,就必须搭建代码阅读和运行环境。下载项目源代码,我使用的是crawler4j-4.1版本。在eclipse中先建立相应的package和class文件,复制相应的class文件。之后根据错误提示,从网上找到相应的依赖包。
这些包的用处之后再慢慢分析。图中我额外添加了一个mytest包,用于写一些临时的test case,帮助我们理解函数的功能。
3.crawler4j架构
src
crawler // 爬虫类
authentication // 认证
exceptions // 异常定义
fetcher // 网络获取
frontier // 爬虫调度
parser // 网页内容处理
rototstxt // robot协议处理
url // URL处理
util // 工具
mytest // 我们的测试用例可以看出crawler4j的基本架构就是把所有你能想到的组成部分都单独拆出来,每个部分只负责一件事。
4.代码阅读与分析
国外大神写书都是首先从架构写起,然后逐个深入,最后有机结合。作为学习笔记,我的想法是由易到难,先把依赖包最少的最简单的类理解清楚,再分析难的,最后组合到一起。话不多说,走你。















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









