







基于相关滤波器的跟踪算法,典型的算法有KCF、DSST、STC、SAMF等。这些算法的大致框架相差不大。
文章中作者对近年来基于相关滤波方法的视觉跟踪的有关研究进行了总结,通过一个统一的框架,总结了11中方法,回顾了这些算法的贡献。

介绍
在视频第一帧给定目标的初始位置,追踪的目标就是预测之后的位置。追踪受到很多因素的影响,比如:光照变坏、遮挡、形变、旋转等。在过去对于跟踪的研究之中,主要分为两种方法:生成式模型和判别式模型。前者的主要思想是通过寻找最佳匹配的窗口,而后者的主要思想就是学习从背景中区分目标。
在判别式模型中,基于相关滤波器的跟踪算法表现比较好。一般的,相关滤波器的原理就是在场景中,对每个感兴趣的目标产生高响应(相关峰 correlation peak),对于背景则产生低的响应。
correlationfilter-based tracking(CFTs)主要可以通过以下几个方面提高:
1)引入更好的训练方案(introducing better training schemes)
2)提取强大的特征(extracting powerful features)
3)减轻尺度变化的影响(relieving scaling issue)
4)结合基于部分的追踪策略(applying part-based tracking atrategy),即相对于对目标整体识别,可以将目标分成好几个部分,对各个部分进行识别
5)结合long-term的跟踪(cooperation with long-term tracking)
CFT整体框架介绍
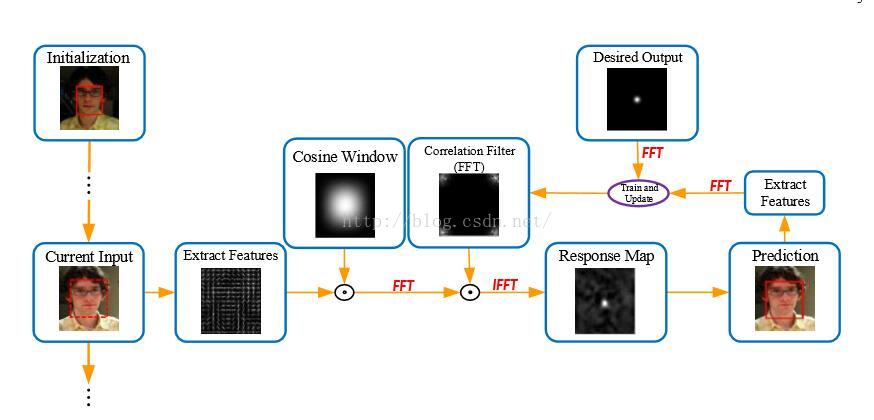
相关滤波器的训练机制
A、传统的训练方法
最简单的情况,从一个图像上截取一个模板,用它来对目标产生顶峰。但是这种方法有时候对于背景也会产生一个很高的响应。为了解决这种问题,一些方法通过抑制负样本的响应,保留正样本的响应来训练。但是这种硬性的约束有时候并不能取得一个良好的效果。有一种叫做平均所有的滤波器(ASEF)的方法,通过平均所有训练得到的滤波器来得到一个一般的滤波器。尽管这种方法取得了不错的效果,但是需要大规模的样本来训练,这就制约了它的跟踪速度。
B、适应性的相关滤波
MOSSE(最小均方误差和输出)方法在ASEF的基础上做出了一些改进,提高了效率。
1)MOSSE
2)Regularized ASEF:通过稍微改变原始的形式,ASEF也可以应用到有效的跟踪中。
C、核相关滤波器
1)Ridge Regression Problem
2)Circulant Matrix
3)Detection,和ASEF、MOSSE方法一样,相应值最大的位置就是目标位置。
D、密集时空上下文跟踪器
E、更新机制
每种方法的更新机制略有不同,具体参考下边链接。
鲁棒的更新机制要考虑长期更新来实现,如果目标丢失或者被遮挡,学习它的外观模型是有害的,为了避免学习误判的样本,一些人引进了长期跟踪组件,如:当检测到有遮挡时,停止更新。如果长期跟踪组件具有更高的置信度,就重新跟新我们的滤波器。
F、比较不同的训练机制
ASEF,滤波器的产生是通过平均所有学习到的滤波器,但是MOSSE的滤波器则是通过平均所有的图像训练到的。通过引入脊回归、循环矩阵、核相关滤波器等,STC和它们则有很多不同的地方:
1)STC建立了目标及其上下文之间的关系,但是其他滤波跟踪方法则用训练的滤波器建立输入的外观模型;
2)STC得到的置信图可以看做是给定的当前目标的先验概率,但是其他跟踪算法的置信图的值表示的是相关分数;
3)STC可以进行任意尺度的估计,但是这一点对于其他跟踪还是很困难的
详细请参考:http://blog.csdn.net/lk798362252/article/details/51030248















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









