









代码参考:http://deeplearning.net/tutorial/mlp.html#mlp
代码学习:http://blog.csdn.net/u012162613/article/details/43221829
代码下载:Github
2015/4/3
Experiment 1: 使用含有1层隐藏层的多层感知机
Github目录下mlp.py文件
使用推荐的配置
learning_rate = 0.01
L1_reg = 0.00
L2_reg=0.0001
n_epoches=1000
batch_size=20
n_hidden=500
实验结果:

实验耗时:

增加中间层:
<span style="font-size:14px;"><span style="font-size:14px;"><span style="font-size:14px;">self.hiddenLayer_1 = HiddenLayer(
rng=rng,
input=input,
n_in=n_in,
n_out=n_hidden_1,
activation=T.tanh
)
self.hiddenLayer_2 = HiddenLayer(
rng=rng,
input=self.hiddenLayer_1.output,
n_in=n_hidden_1,
n_out=n_hidden_2,
activation=T.tanh
)
self.hiddenLayer_3 = HiddenLayer(
rng=rng,
input=self.hiddenLayer_2.output,
n_in=n_hidden_2,
n_out=n_hidden_3,
activation=T.tanh
)</span></span></span>
<span style="font-size:14px;"><span style="font-size:14px;"><span style="font-size:14px;">self.L1 = (
abs(self.hiddenLayer_1.W).sum() + abs(self.hiddenLayer_2.W).sum() + abs(self.hiddenLayer_3.W).sum()
+ abs(self.logRegressionLayer.W).sum()
)
self.L2_sqr = (
(self.hiddenLayer_1.W ** 2).sum() + (self.hiddenLayer_2.W ** 2).sum() + (self.hiddenLayer_3.W ** 2).sum()
+ (self.logRegressionLayer.W ** 2).sum()
)
self.params = self.hiddenLayer_1.params + self.hiddenLayer_2.params + self.hiddenLayer_3.params + self.logRegressionLayer.params</span></span></span>
Experiment 2: 使用含有3层隐藏层的多层感知机
Github目录下mlp_3HiddenLayers.py文件
自己中间加入两个隐含层,分别为400 和 300 个节点。实验配置如下:
learning_rate = 0.01
L1_reg = 0.00
L2_reg=0.0001
n_epoches=1000
batch_size=20
n_hidden_1=500
n_hidden_2=400
n_hidden_3=300
实验结果:

实验耗时:

*实验虚拟内存消耗很大!!!

Experiment 3: 使用含有3层隐藏层的多层感知机,学习率减小一倍
修改Experiment 2中代码第264行,learning_rate=0.01 改为 earning_rate=0.005
调整Experiment 2中learning rate。实验配置如下:
learning_rate = 0.005
L1_reg = 0.00
L2_reg=0.0001
n_epoches=1000
batch_size=20
n_hidden_1=500
n_hidden_2=400
n_hidden_3=300
实验结果:

实验耗时:

总结
通过上述三个实验,发现隐含层变多,在测试集上的性能变差。可以参考多层神经网络效果不好的原因:训练深度网络的困难
2015/4/4
针对多层网络效果不好原因,无法确定是由于局部最优还是梯度弥撒。为了探究其原因,决定打印中间变量(模型的参数),发现问题。
在HiddenLayer代码中加入:
<span style="font-size:14px;"><span style="font-size:14px;">def show_params(self):
print self.W.get_value()
print self.b.get_value()</span></span>每次在validation上做测试时候打印变量:
在if (iter + 1) % validation_frequency == 0:下加入代码:
<span style="font-size:14px;"><span style="font-size:14px;">print('It is %i iteration' %(iter))
print 'learned parameters for the hidden layer:'
print classifier.hiddenLayer.show_params()</span></span>

Experiment 2的minibatch_avg_cost打印结果:

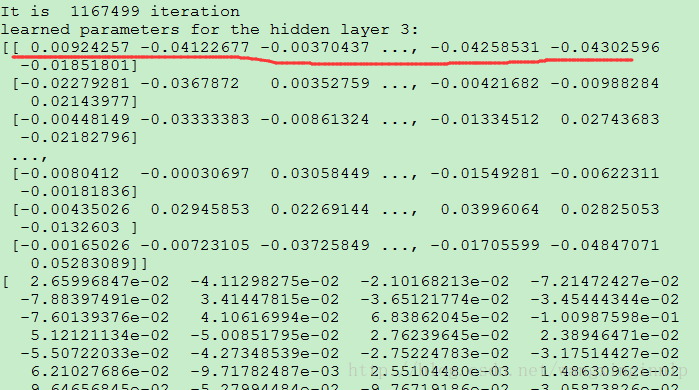
Experiment 2的后几轮参数变化打印结果:
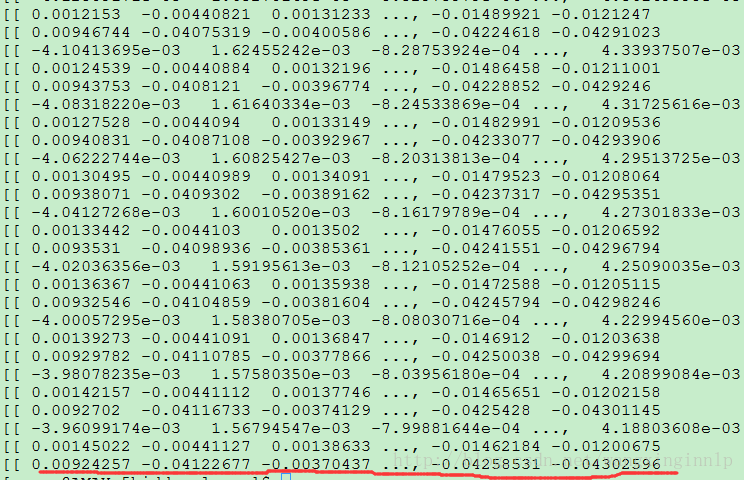
红线标注行为第3层隐含层的参数,改行对应展开为:
才疏学浅,分析不出到底是由于梯度弥散还是由于局部最优才导致的问题,改天请教下其他人。
参考博客:http://blog.csdn.net/u012162613/article/details/43221829














 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









