







最近因为工作的原因,好久没有写博客了。(看到有很多评论和留言,都不能一一回复啦~)
过年之前Oracle组织过一次内部的编程马拉松,当时选择的题目是OCR相关的,但是但是做出来的效果不是很好,就一直想着把代码重新整理一下,优化一下效果。
目前随着国内互联网火的一塌糊涂,似乎也带动了图像处理的发展与引用,以前一直觉得图像处理很难找到合适的工作,所以找工作的时候就换了自然语言处理,然后现在发现互联网招聘图像处理工程师也很多。。。
废话不多说,来看OCR on Android .
作OCR的话,需要使用一些已有的sdk, 例如tesseract,这个是Google的一个开源项目貌似国内访问这个比较费劲。
tesseract是C语言开发的,如果想要使用的Android平台上,需要通过Android平台的JNI调用机制,有兴趣的朋友可以参考:http://blog.csdn.net/watkinsong/article/details/9849973
对于大部分朋友来说,完全不需要直接操作底层的c语言,毕竟通过JNI调用非常难调试。 为了便于使用tesseract,github上有个叫tess-two的项目,把tesseract的底层API封装为Android平台可以直接使用的java API, 这样直接引用这个项目就可以直接进行OCR开发了。
如果不想看下面的罗嗦,直接下载我的Demo项目,直接看代码就可以了,下载地址: https://github.com/weixsong/libra, 注意,这是一个项目的集合,找到OCRDemo文件夹就是相应的项目。
第一步: 到 https://github.com/weixsong/tess-two 下载最新的tess-two项目,通过eclipse导入该羡慕
第二部:创建你自己的OCR项目,然后引用tess-two项目,这样就可以使用tess-two项目提供的API以及.so文件了。
第三步:到https://code.google.com/p/tesseract-ocr/, 下载你需要的对应的语言的已经训练好的训练数据(至于这个数据是模板,还是个神经网络,还是分类器。。。我不知道), 然后把训练数据放入Android 项目的 asset文件目录中,
需要注意的是,在写Android程序时,需要把训练好的分类文件拷贝到Android存储中:
private void checkAndCopyFiles() {
String[] paths = new String[] { DATA_PATH, DATA_PATH_TESSDATA };
for (String path : paths) {
File dir = new File(path);
if (!dir.exists()) {
if (!dir.mkdirs()) {
Log.v(TAG, "ERROR: Creation of directory " + path
+ " on sdcard failed");
return;
} else {
Log.v(TAG, "Created directory " + path + " on sdcard");
}
}
}
for (String lang : langs) {
String traineddata_path = DATA_PATH_TESSDATA + lang
+ ".traineddata";
String asset_tessdata = "tessdata/" + lang + ".traineddata";
if (!(new File(traineddata_path)).exists()) {
try {
AssetManager assetManager = getAssets();
InputStream in = assetManager.open(asset_tessdata);
OutputStream os = new FileOutputStream(traineddata_path);
// Transfer bytes from in to out
byte[] buf = new byte[1024];
int len;
while ((len = in.read(buf)) > 0) {
os.write(buf, 0, len);
}
in.close();
os.close();
Log.v(TAG, "Copied " + lang + " traineddata");
} catch (IOException e) {
Log.e(TAG,
"unable to copy " + lang + " traineddata "
+ e.toString());
}
}
}
}第四步:就可以使用tess-two进行OCR识别了,当然,你需要提供一张照片。。。
package com.example.homework;
import android.graphics.Bitmap;
import android.util.Log;
import com.googlecode.tesseract.android.TessBaseAPI;
public class TesstwoOCR {
private static final String TAG = "TesstwoOCR";
private TessBaseAPI ocr_eng;
private TessBaseAPI ocr_chi;
public TesstwoOCR() {
Log.v(TAG, "BaseApi initializing...");
ocr_eng = new TessBaseAPI();
ocr_eng.setDebug(true);
ocr_eng.init(MainActivity.DATA_PATH, MainActivity.LANG_EN);
ocr_chi = new TessBaseAPI();
ocr_chi.setDebug(true);
ocr_chi.init(MainActivity.DATA_PATH, MainActivity.LANG_ZH);
}
public String doOCR(Bitmap bitmap, String lang) {
String result = "";
if (lang.equals(MainActivity.LANG_EN)) {
ocr_eng.setImage(bitmap);
result = ocr_eng.getUTF8Text();
} else if (lang.equals(MainActivity.LANG_ZH)) {
ocr_chi.setImage(bitmap);
result = ocr_chi.getUTF8Text();
} else {
//nothing
}
return result.trim();
}
}
上面的代码我分别使用了中文和英文的OCR识别,因为再我的Demo中可以进行中英文识别的切换。
因为这里给出了Demo的源代码, 所以整个过程描述的比较简单。大家还是尽量参考Demo代码进行对应的OCR识别的开发。 Demo 下载地址:https://github.com/weixsong/libra, 在源代码中,也有详细的如何使用该项目的说明。
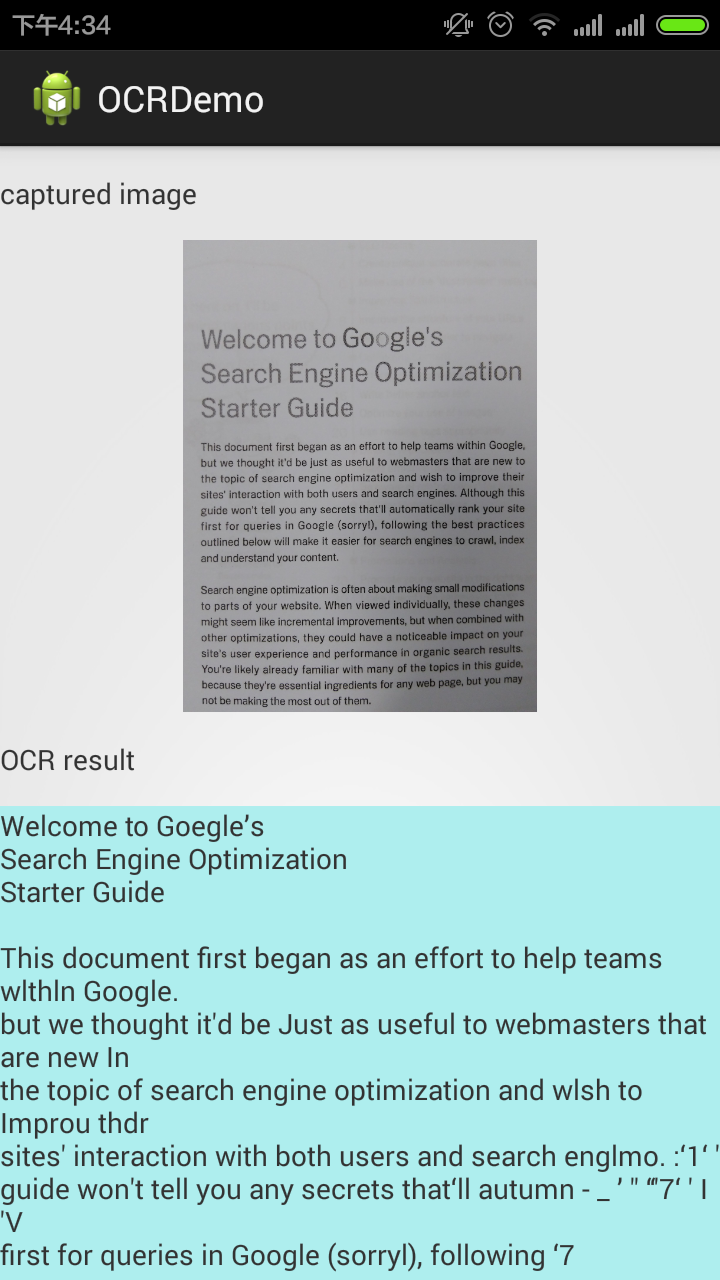
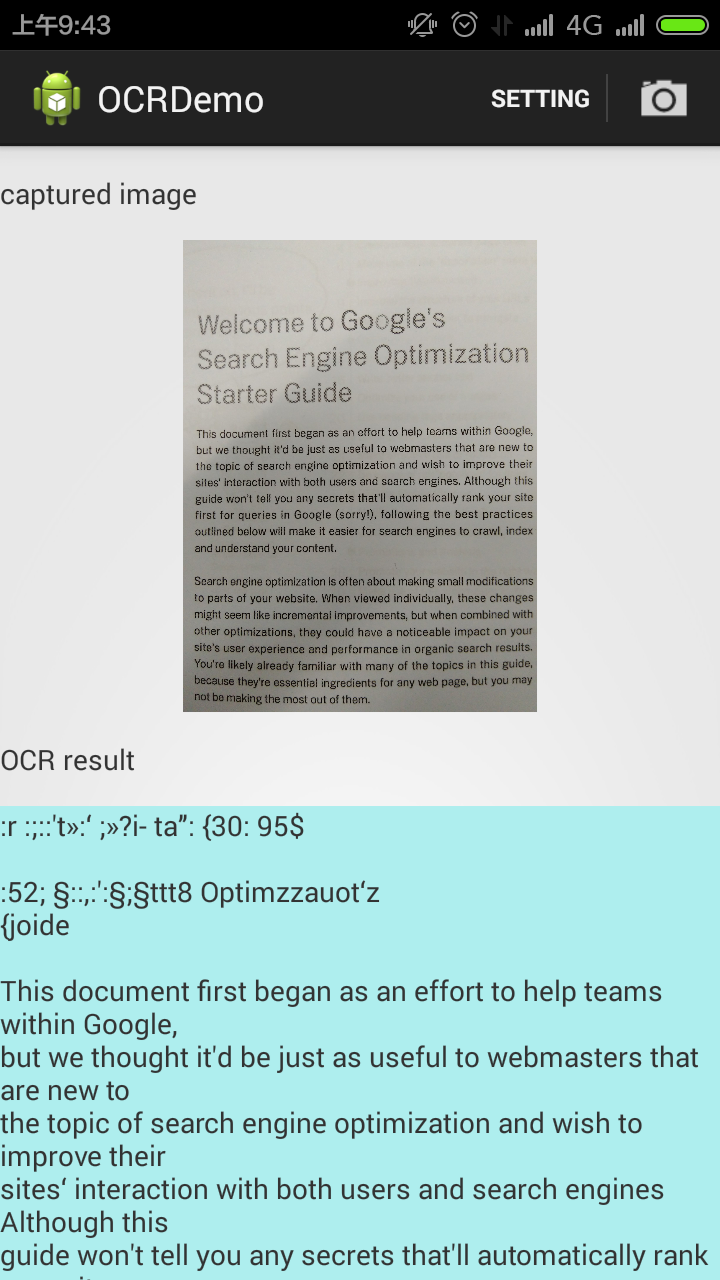
下面是OCR识别的效果截图, 总体来说,目前的效果还是相当不错的:


















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









