









以二进制格式读写数据
- 输入流:Java API可以从其中读入一个字节序列(二进制格式)的对象(抽象类InputStream)
- 输出流:Java API可以向其中写入一个字节序列(二进制格式)的对象(抽象类OutputStream)
完成对流的读写后应该调用close关闭它,关闭一个输出流的同时还会冲刷用于该输出流的缓冲区:所以被临时置于缓冲区中,以更大的包的形式传递的字符在关闭输出流时都将被送出。
Java的流和文件操作的灵活性在于每一个类负责一种职责,可以自由组合流过滤器:(Java.io中的类都将相对路径名解释为以用户工作目录开始)
FileInputStream和FileOutputStream提供辅助在一个磁盘文件上的里输入流和输出流。
这些类只是在字节级别的读写
例如从文件中读入数字或者构造一个带缓冲区的输入流:
File file = new File(路径名);
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
DataInputStream dataInputStream = new DataInputStream(fileInputStream);//1
BufferedInputStream bufferedReader = new BufferedInputStream(fileInputStream);//2以文本格式读写数据
对于Unicod文本,可以使用抽象类Reader和Writer
1、写出文本输出:
FileWriter fileWriter = new FileWriter(文件名);
PrintWriter printWriter = new PrintWriter(fileWriter);2、读入文本输入:
File file = new File(路径);
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line;
while((line = bufferReader.readLine())!= null){
do something with line;
}在Java(JVM,内存,代码)中字符只能以一种形式存在,就是Unicode(不选择任何特定的编码,直接使用它们在字符节中的编号,这是统一的唯一方法)
Java的这种约定使得一个字符分为两部分L:JVM内部和OS的文件系统。(编码转换都发生在边界,JVM和OS的交界处,各种输入输出流起作用的地方)
在JVM内部:统一使用Unicode表示,当这个字符被从JVM内部移到外部(即保存为文件系统中的一个文件的内容时),就进行了编码转换
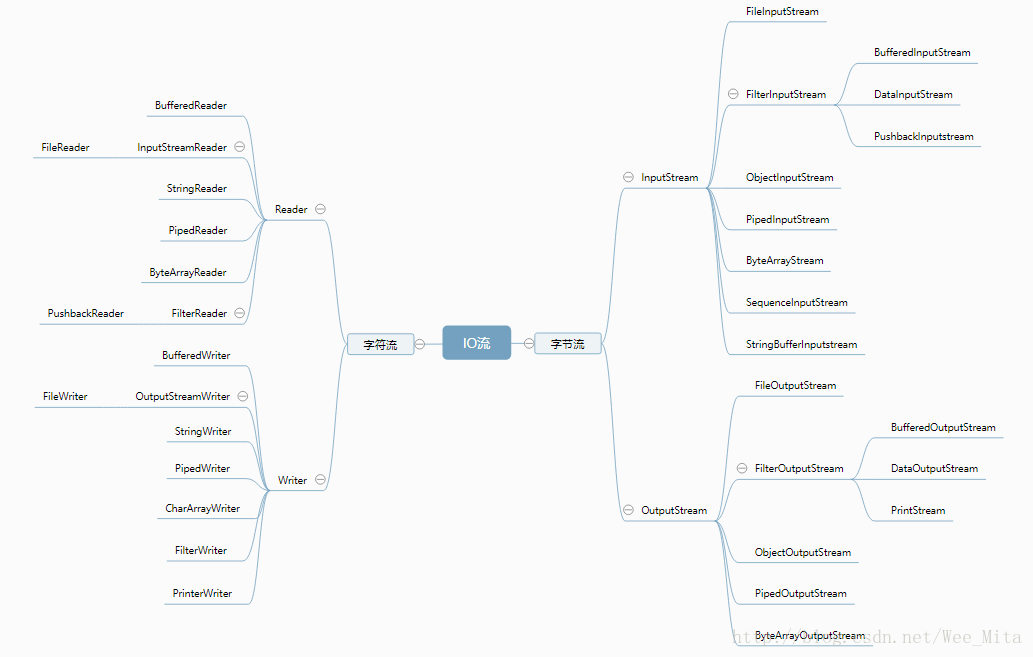
所有的I/O基本上可以分为两类:
- 面向字符的输入输出流
- 面向字节的输入输出流
ps:这里的面向是指类在处理输入输出的时候
1. 面向字节
这类工作保证系统中的文件的二进制内容和读入JVM内部的二进制内容一致,不能变换任何0或者1的顺序。这种输入输出方式适合读入视频或者音频文件,或者是不做变换的文件内容
2. 面向字符
这类工作保证系统中的文件的字符和读入内存的“字符”要一致。
例如,windows系统中的一个GBK文本文件,其中一个汉子,这个字的GBK编码不管是什么,当使用面向字符的I/O把它读入内存并保存在一个char型变量中,希望的是系统不要直接保存这个汉子的GBK编码到char变量中,我们不关心char变量具体的二进制内容是什么,只希望这个字符读取到char变量中之后还是这个汉子。
总结一下,面向字符的I/O类(Reader,Writer类)实际上隐式地做编码转换,
在输出时将内存中的Unicode字符使用系统默认的编码方案进行编码,
在输入时将文件系统中的已经编码过的字符使用默认的编码方案进行还原
这里的默认编码方案是GBK与Unicode的相互编码,如果用到GBK以外的文件,必须采用编码转换(因为Reader和Writer类不支持),即一个字节和一个字符之间的转换(InputStreamReader和OutputStreamWriter类)
3、序列化
Java的“对象序列化”能将一个实现了Serializable接口的对象转换成一组byte,这样日后要用这个对象的时候,就能把这些byte数据恢复出来,并据此重新构建那个对象。
这一点甚至在跨网络的环境下也是如此,这就意味着序列化机制能够自动补偿操作系统方面的差异
例如:
在Windows机器上创建一个对象,序列化之后再通过网络传到Unix机器上,最后在那里进行重建,不用担心在不同的平台上数据是怎么样表示的,以及byte顺序怎么样,或者别的什么细节
- 对象序列化能够实现轻量级的persistence(即对象的声明周期不是有程序是否运行决定的,在程序的两次调用之间对象仍然是活着的)
- 必须明确进行序列化和解序列化
在Java语言中加对象入序列化,是为了实现2个功能:
- Java的远程方法调用(Remote Method Invocation,RMI)能够像调用自己机器上的对象那样去调用其他机器是上的对象
- 当向远程对象传递消息的时候,就需要通过对象序列化来传送参数和返回值
序列化对象的步骤:
- 创建一个OutputStream
- 把对象嵌进ObjectOutputStream
- 使用writeObject()方法把对象写入OutputStream
读取序列化对象的步骤:
- 把InputStream嵌到ObjectInputStream中
- 调用readObject()方法
注意,此时入到的是Object的一个reference,因此在使用前需要先下传
例子:
package T616;
import java.io.*;
/**
* Created by Promacanthus on 2017/6/16.
*/
public class Serialize {
final static String PATH = "file.txt";
final static String[] strings = null;
public static void main(String[] args) throws IOException, ClassNotFoundException {
File file = new File(PATH);
FileOutputStream fileOutputStream = new FileOutputStream(file);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(strings);//对象序列化输出
FileInputStream fileInputStream = new FileInputStream(file);
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
Object object = objectInputStream.readObject();//读取序列化对象
}
}
对象序列化不仅能保存对象的副本,而且还会跟着对象中的reference把它所有引用的对象也保存起来,然后在继续跟踪那些对象的reference,以此类推。















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









