









先来看一个TopK题目: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
如何解答?Topk之前已经说过,寻找最小的K个数。
可是我们如何处理Query呢?一千万条记录,每条记录是255Byte,很显然要占据2.375G内存,很明显不能用内部的排序,无论是什么内部排序。这个时候可以用外排序,归并排序可以解决。可是题目也说了除去重复最多300W,300W完全可以放入内存,可是如何把1000W的字符串放入内存呢?这就是我们接下来要说的了,Hsah Table完全可以解决。
不要着急,听我细细道来。
说哈希之前先来说一下直接寻址表,这个类似BloomFilter和位向量。如果关键字域比较小,也就是说关键字不多,而且都在一定范围内。那我们可以完全把关键字当成数组下标,每一个关键字放入哈希表的一个槽。这也即是一一映射,映射结果不变化。
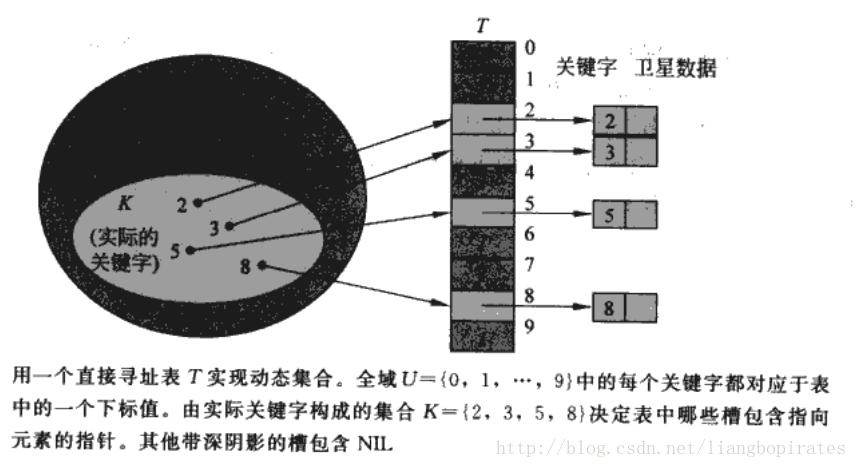
这个看起来蛮不错的,操作也很简单,每个操作时间代价都是O(1).

确实很不错。可是这只是关键字分布较小范围的时候才会有作用,而且还要求关键字都不能相等。。。如果有100个整数,都是64位的,有的很小,有的超大。这个时候你定义的数组的大小岂不是2^64-1,你能忍受吗?你还会用这种方法吗?2个数,1和100000000,你定义的数组大小也必须是100000000,这样才符合刚才的直接寻址法。太浪费内存了吧。。 所以来说,直接寻址固然不错,可是限制太多。关键字不重复,关键字的范围要小。 接下来我正式的介绍一下哈希表。 什么是哈希表?Hash Table也叫散列表。 哈希表是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,存放记录的数组叫做哈希表。建好的Hash表的查询速度是常数级O(1),这样就比较nice了。 Hash映射就是用一个Hash函数将关键字key映射到Hash表的槽里。这个映射不是一一映射了,即便是一个字符串也能映射成一个整数。对于刚才的直接寻址表来说就是key映射到key槽,而Hash函数将key映射到H(key)槽里。而我们要定义的表的大小只是关键字的数量,不必是关键字范围的大小和关键字的重复,这样就不会浪费内存。而且插入一个需要的时间也是O(1),不过我们用Hash表大部分是为了查询,查询的时间复杂度也是O(1)。
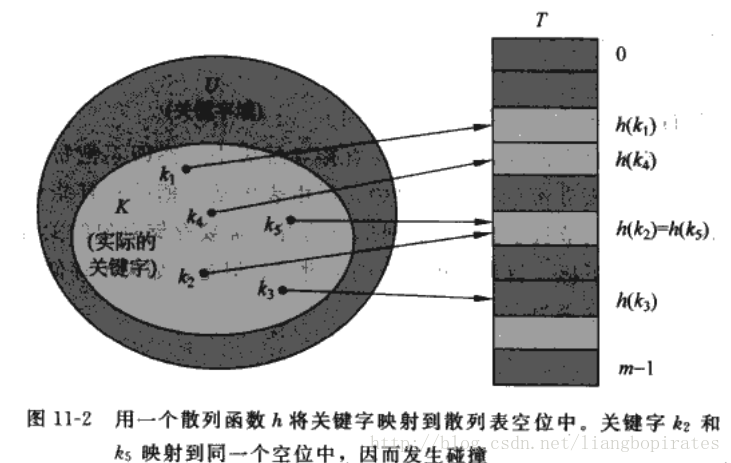
不幸的是这可能会出现问题,什么问题?不同的关键字映射到相同的槽里,碰撞collision出现了。这咋办啊?关键字总不能舍弃吧?难道我们期望他们不会碰撞?这是不现实的。不过不要着急,我们可以在那个槽的地方拉一个链表,将所有映射到这个槽的关键字都放到这个链表里面。这就是所谓的拉链法,也叫链接法。
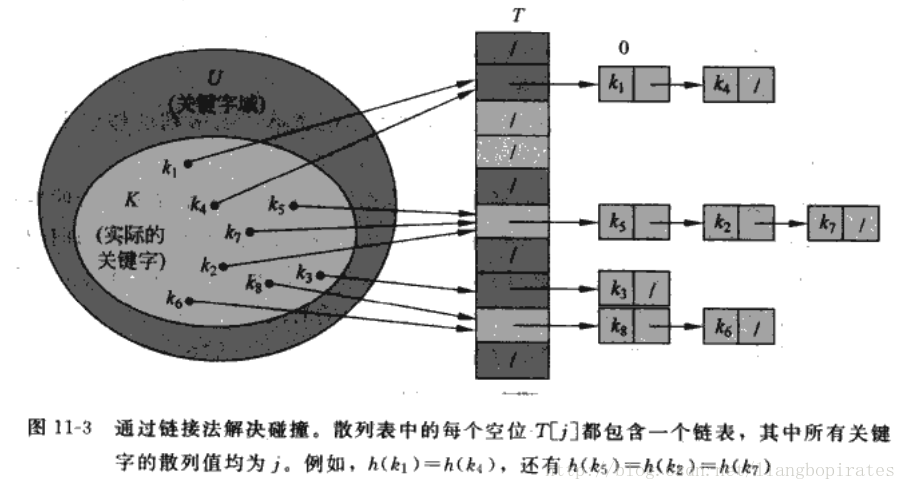
对于每一个槽都给他拉一个链表,到时候凡是Hash值相同的映射到同一个槽的都要放到链表里,链表的大小随时变化。

查询和插入的时间复杂度同样是常数级O(1)的。解决了?NO。一般情况下还好,如果所有的Hash值都相同了,也就说所以的关键字都映射到一个相同的槽里,这Hash表就变成了链表了,而且内存占用比链表还大。查询的时间复杂度是O(N)。这不是坑吗?那我们还用它做什么?不用了?唉唉唉,凡事总有例外,这个不能怪Hash表,只能说Hash函数太差了,如果选一个好的Hash函数,这个情况就不会出现(NO,下文会有说明,想想)。一个理想的Hash函数会将所有的关键字都平均均匀的映射到Hash表的不同槽里。也就是说这个情况是最坏的情况,拉链法的平均情况还是很好的。 我们来分析一下拉链法的平均情况:假设对于每一个关键字key都用相同的记录映射到Hash表的任何一个槽里,而且每一个关键字key都是相互独立的,这就是简单一致Hash。假设有n个关键字,Hash表有m个槽。那么有两个key被Hash函数映射到同一个槽里的概率有多大?1/m,互相独立,互不影响。定义装载因子α=n/m,即Hash表中每一个槽中关键字的平均数量。(α>1 <1 =1)则对于Hash表的下标i的链表中的关键字数ni=α。则此时查询用时O(1+α),包括查找成功和查找失败。 定理:在简单一致Hash的假设下,对于链接法解决碰撞的Hash表,平均情况下成功查找和查找失败用时都是O(1+α)。 α是槽里关键字的平均数量。如果n=O(m),α=n/m=O(m)/m=O(1)。那么查询的时间复杂度就是常数级O(1)。一般情况下m和n都是一个数量级。 为了避免链接法的最坏情况,选择一个好的Hash函数是至关重要的。
我们来看一下常用的Hash函数。 除法哈希法,也叫除留余数法。通过关键字除以槽数m将关键字映射到槽里的方法。哈希函数是H(k)=k Mod m。 举个例子,m=12,k=100,H(100)=4。 而如果m=2k,那么无论k是什么,H(K)的值都是一个0和奇数,也即是说只要奇数槽和0槽被占用,其他的偶数槽都是浪费掉了。如果m=2^r,那么H(k)的值就是k的低r位(化成二进制)。这样造成的后果是某一个槽有很多的关键字。所以来说一般的m取值尽量不要接近2的整数幂,而且还要是质数。 这样虽然很好了,可是除法毕竟在计算机运算是不快的,所以我们再讲一个乘法Hash。 乘法哈希法:用关键字乘A(0<A<1),取其结果的小数再乘以m取整。 Hash函数是H(k)=[m(kA Mod 1)].其优点是对m没有什么要求,一般选择2的整数幂(呵呵)。 假设计算机字长为w位,把k化为w位的二进制,A=s/2^w(<0s<2^w),m=2^p,则
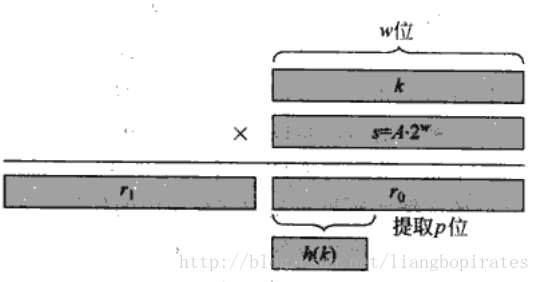
这样就比较好了,A取值没啥要求。最好的A=(√5-1)/2。还有一些平方取中法,折叠法等等。
说了这么些Hash函数。再来看一下避免碰撞的方法。除了链接法之外还有别的方法避免collision吗?当然,开放寻址法。 开放寻址,和链接法不同的是这没有链表,所有的关键字都放入槽内,如果Hash值相同此槽已有关键字,则再次Hash查询,直到找到一个空槽放入关键字key为止。查询序列也很关键,不过这是和第一次Hash值是有关系的。查询序列不一定是0 1 2 3....m,但其实只是m!中的一个,Hash表有m!种查询序列。对于每一个关键字查询序列是h(k,0),h(k,1),h(k,2)...h(k,m)。 查询和插入都很方便,可是删除确实很麻烦。


删除麻烦在哪里呢?因为我们要Hash很多次,比如k=496,第一次Hash(496,0)=586,可是发现槽586处有关键字370,第二次Hash(496,1)=204,发现槽204处有关键字37,第二次Hash(496,2)=304,发现槽304空,放入关键字496.如果删除值370,370在槽586处。然后我再查询496,第一次Hash得到586,发现槽位空,则说明496不存在,可是496明明是刚才插入的。所以来说删除不是仅仅删除就完事了,要做一个标记DEL,以免影响Hash,而且再次插入的时候这个标记表示是空槽可以插入,查询的时候看到此标记可以绕过去。 那么我们如何构造开放寻址Hash函数呢? 线性探测:H(k,i)=(H1(k,0)+i)Mod m,H和H1可以相同也可以不同。这样我们的查询序列就是从第一次Hash值开始一个接一个的查询空槽直到找到为止,只需要第一次Hash值即可,很简单。可是这个函数会出现问题,群集问题。就是说会造成一个很长的连续序列都不是空槽,而之前之后都有一连串的空槽,这样如果关键字的Hash值在这个序列中的话将会造成无用的遍历,甚至会到m槽,而0开始的序列有很多的空槽。这样无谓的浪费了很多的时间。
二次探测:我们不要这样一个接一个的查询空槽,而是间隔的查询。可以把i换成i^2或者变成H(k,i)=(H(k)+c*i+c*i^2),这样会好很多的,不过这样也会造成群集,二次群集。如果两个关键字的初始查询值相同,那么他们的查询序列也是相同的,二次群集的长度稍微短些,危害小些。不过这两种探测方法的查询序列都只是m种罢了,而Hash表的查询序列可是m!种。不过接下来我们说一个更好的,有m^2种查询序列。双重哈希:H(k,i)=(H1(K)+i*H2(k))Mod m,这种Hash方法可以大幅度的减轻群集现象。H1和H2都有m种查询序列,所以H有m^2种查询序列。这时候取m的值为2的整数幂,而且要H2函数的Hash值要总是产生奇数。
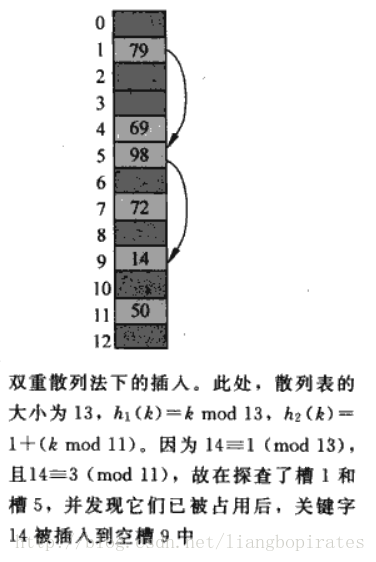
不过尽管开放寻址很好,可是最坏的情况依然还是很差,避免不了最坏的情况。所以我们来分析一下平均情况,看一看期望值。α=n/m是槽里关键字的平均数量,对于开放寻址来说α必然是小于等于1的,因为每一槽最多放入一个关键字。 假设对于每一个关键字key都用相同的记录映射到Hash表的任何一个槽里,而且每一个关键字key都是相互独立的,这就是简单一致Hash。假设有n个关键字,有m个槽的Hash表。对于失败的查找,第一次查找失败的概率是n/m(因为此时m中有n个数),那么第二次查找失败的概率是多少?(n-1)/(m-1),因为之前那个已经排除,不再查询。第i次查找失败的概率是(n-i+1)/(m-i+1)(<n/m)。 那么期望查找的次数E=1+n/m(1+(n-1)/(m-1)(1+...)+))=1+α(1+(1+α(1+...)))<1+α+α^2+α^3+...=1/(1-α)。所以来说失败查找的次数是1/(1-α),而成功的查找也是一样的,查找失败不是可以插入吗?那可是空槽啊。 定理:在一致哈希的假设下,对于一个开放寻址的Hash表,平均情况下成功查找和查找失败的次数都是1/(1-α)。 如果1/(1-α)=0.5,需要查询2次,而1/(1-α)=0.9,需要查询10次,所以一般情况希望1/(1-α)小一些比较好,这样查询次数才少。千万不要以为Hash的利用率越高,Hash很稠密才好,那样会使查询速度变的很慢。我们用Hash是为了什么,不就是为了快速的查找和插入吗?如果速度都没有了,我们还要它干什么呢? 好的Hash函数确实很重要啊,可是再好的Hash函数也不可避免碰撞,总是能找到一组关键字可以用你给定的Hash函数映射到同一个槽,查询时间变成O(n)最坏情况。这一点,与Hash函数没有任何关系,难道我们说了半天,P用没有?是有点坑啊。这个时候我们不由得想起了随机性,如果我们随机给你一个Hash函数,那你就没办法一定给我导致最坏的情况。这就是全域哈希。 全域哈希的思想就是执行算法开始从一个设计好的Hash函数集中随机选出一个函数,对于给定的关键字集合就没有办法导致最坏的情况。 如果全域哈希函数集合为H,而关键字集合为U,则对于U中关键字不同的key碰撞的概率是1/m。那么也就是说有|H|/m个哈希函数满足这个情况。 定理:如果h选自全域哈希函数集H的哈希函数,那么将n个关键字映射到m个槽中。则查询失败次数的期望查询次数就是α,而成功查询的期望次数是α+1。 利用全域哈希可以得到常数级的时间复杂度,因为n=O(m),α=O(1); 我们之所以使用Hash,看中的就是它的平均时间复杂度可以达到O(1)。大部分地方情况下我们利用Hash就是为了查询,如果我们仅仅希望创建一个静态的查询Hash Table,那么我们可以得到更好的效果。那就是完全哈希。 完全哈希:在最坏的情况下进行查找的时间复杂度是O(1)的哈希技术。 实现办法就是利用二级哈希表, 每一级的Hash函数都使用全域哈希函数。第一级的Hash表和之前没有什么区别,将关键字映射到槽里,但是如果发生碰撞了,我们利用拉链的思想,但是不用链表做,对于每一个碰撞的槽i再建立一个小型Hash表hi,而Hash表的大小mi是碰撞关键字ni的平方,即mi=ni^2.
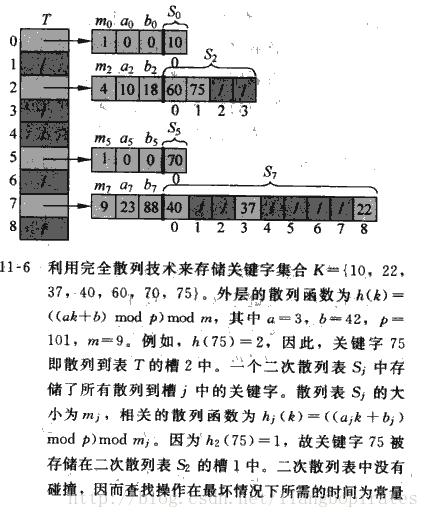
定理:对于一个从全域哈希函数集选择的哈希函数h,将n个关键字映射到m=n^2个槽里的哈希表,发生碰撞的概率小于1/2. 简单证明一下:对于m个槽两个不同的关键字碰撞的概率是1/m=1/n^2,而从n个关键字选出2个关键字的组合数是n(n-1))/2,则n(n-1))/2*1/n^2<1/2。 那么对于二级哈希表来说只要满足m=n^2,那就可以实现低概率碰撞的常量时间的查询。 可是二级哈希表的空间复杂度会不会太大?当然不会啦,如果一级哈希表做的好,那么二级的空间复杂度肯定会好的。 定理:对于一个从全域哈希函数集选择的哈希函数h,将n个关键字映射到m=n个槽里的哈希表,而且对于二级哈希表的大小为ni=mi^2,则一个完全哈希的哈希表的期望空间复杂度小于2n,即是O(n). 在这里要扩展一个哈希算法,即是d-left hashing。d-left hashing中的d是多个的意思,先看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。比较的是两个哈希函数映射的位置中已经存储的key(包括碰撞的情况)的个数,而不是两个子表中已有key的个数。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。 了解了2-left hashing,d-left hashing就很好理解,它只是对前者的扩展。2-left hashing固定了子表的个数是2,d-left hashing更加灵活,子表的个数是一个变量d,同时也意味着哈希函数的个数是d。在d-left hashing中,整个哈希表被分成d个从左到右依次相邻的子表,每个子表对应一个相互独立的哈希函数。在加入新key时,这个key被d个哈希函数同时计算,产生d个相互独立的位置,然后将key加入到负载最轻的位置(bucket)中。如果负载最轻的位置有多个,就把key加入到最左边的负载最轻的子表中。同样地,如果要查找一个key,需要同时查找d个位置。 OK,Hash表说先到这里,以后学到新的知识还是update。因为Hash算法博大精深,这只是九牛一毛而已。以后还要多多学习。 明白了这些 刚才的TopK问题就变的很好解决了,自己想一下吧,我就不多说了。 转载请注明出处http://blog.csdn.net/liangbopirates/article/details/9753599














 2235
2235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









