







桶排序假设待排序的一组数统一的分布在一个范围中,然后设定对应数据数量的桶,待排序的一组数,分别对应算式处理归入这些子桶,并将桶中的数据进行排序,最后将各个桶中的数据有序的合并起来。
通俗的说,就是通过某个公式将待排序的一组数分为几个子范围,然后归入到对应的子桶,这样必然会有不一样的数据经过算式处理后对应同一个桶,我们可通过简单比较将对应同一个桶的不同数据排序,最后各个数据处理完后,有的桶为空,有的桶有多个数据(已排序好),这样我们就可以逐个的遍历桶,然后将数据依次放入原数组中,这样就完成了排序。

上面模型和哈希表的分离链接法很相似。这里不同数据对应同一个桶的插入是通过链表来存储的。
这里给出一个演示:Bucket Sort Visualization
根据上面算法模型和演示,给出代码:上面的图示模型和演示链表是带有表头的,这样是为了方便执行删除操作,但是我们这里仅作为排序,无需删除操作,所以链表是不带有表头的,这样既简化了问题又节省了空间。
typedef struct Node
{
int data;
struct Node *next;
}node;
void AddtoBucket(node *&pNode, int value)
{
node *pHead = NULL;
int tempValue;
node *pNew = new node;
pNew->data = value;
pNew->next = NULL;
if (NULL == pNode)
{
pNode = pNew;
}
else
{
pHead = pNode;
while ((pNode->data <= value) && (pNode->next != NULL))
pNode = pNode->next;
if (pNode->data <= value)
{
pNode->next = pNew;
}
else
{
//插入链表,这里采用的是修改值的方法,即插入指定节点的前面,无需获得该节点的前一节点
//只需修改该节点的值使其等于待插入节点值,然后该节点指向新建节点,新建节点的键值则设为前面节点的键值
tempValue = pNode->data;
pNode->data = pNew->data;
pNew->data = tempValue;
//修改指针
pNew->next = pNode->next;
pNode->next = pNew;
}
pNode = pHead; //修正头节点指针
}
}
void BucketSort(int Arr[], int length, int MaxNum)
{
node **list = new node*[length]; //分配指针数组空间
for (int i = 0; i < length; ++i)
list[i] = NULL;
int index;
for (int i = 0; i < length; ++i)
{
index = (Arr[i] * length) / (MaxNum + 1); //映射函数,可自定义
AddtoBucket(list[index], Arr[i]);
}
//将桶中的数据放入原来的串行中
for (int i = 0, j = 0; i < length; ++i)
{
while(list[i] != NULL)
{
Arr[j++] = list[i]->data;
list[i] = list[i]->next;
}
}
//销毁分配的空间,code 略
}上面插入链表采用的是修改值的方式,不是修改指针的方式,对比修改指针的方式,插入链表节点可以不需要找到前节点。
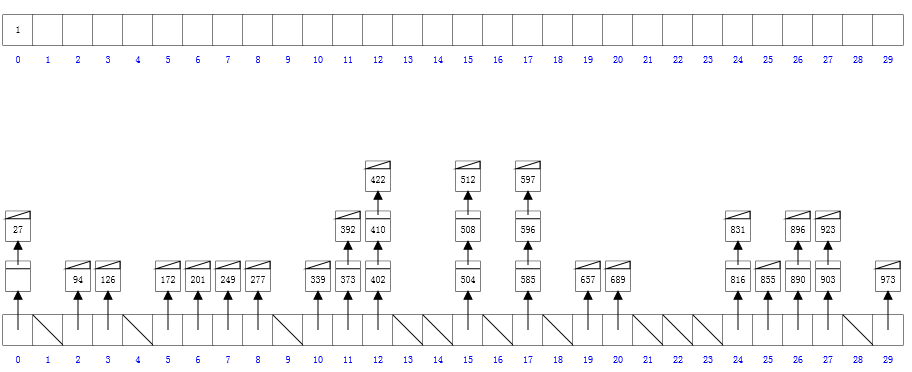
测试程序:
#define LENGTH 500
#define MAXNUM 1000
int main()
{
int Arr[LENGTH];
for (int i = 0; i < LENGTH; ++i)
Arr[i] = rand() % MAXNUM;
BucketSort(Arr, LENGTH, MAXNUM);
for (int i = 0; i < LENGTH; ++i)
{
cout << Arr[i] << endl;
}
return 0;
}复杂度分析:
对 N 个关键字进行桶排序的时间复杂度可分为两部分:
1. 循环计算每个关键字的映射函数,复杂度为 O(N);
2. 插入的时候进行比较,其时间复杂度取决于待插入桶中的数据量,这个复杂度为 ∑O(Ni*logNi) 。其中Ni 为第i个桶的数据量。
当每个桶中只有一个数据时,桶排序达到最好效率,其时间复杂度为O(N)。
桶排序的平均时间复杂度为线性的 O(N+C),其中C=N*(logN-logM)。如果相对于同样的N,桶数量M越大,其效率越高,最好的时间复杂度达到O(N)。 当然桶排序的空间复杂度 为O(N+M),桶排序的空间代价基本上是所有排序算法中耗空间最大的一种算法。此外,桶排序是稳定的,这个应该很容易看出来。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









