







任何一个对C稍稍有了解的人都知道malloc、calloc、free。前面两个是用户态在堆上分配一段连续(虚拟地址)的内存空间,然后可以通过free释放,但是,同时也会有很多人对其背后的实现机制不了解。
这篇文章则是通过介绍这三个函数,并简单的予以实现,对比现有C的标准库实现(glibc等)相比,并不是特别高效,我们重在阐述背后的基本原理。
一、C程序的存储空间布局
图1
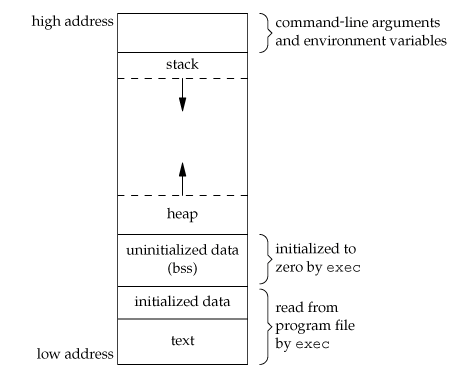
- text:整个用户空间的最低地址部分,存放的是指令(程序所编译成的可执行机器码)。可共享,即使是频繁操作执行的程序,在存储器中也只需有一个副本,通常是只读的。
- initialized data(data):存放初始化过的全局变量,包含了程序中需明确地赋初值的变量。
- uninitialized data(bss):存放的是未初始化过的全局变量,在程序开始执行之前,内核将此段中的数据初始化为0或者NULL。
- heap:堆,自低地址向高地址增长,后面重点剖析
- stack:栈,自高地址向低地址增长,自动变量以及每次函数调用时所需保存的信息都存放在此段中。
二、Heap 内存模型
一般来说,malloc所申请的内存主要从heap区域分配的。
linux内存管理,从这里可以了解到linux下虚拟地址与物理地址。
linux对堆的管理如下:
图2
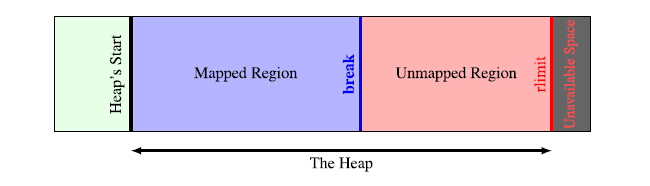
linux 内核维护一个break指针,这个指针指向堆空间的某个地址。从堆起始地址(Heap’s Start)到break之间的地址空间为映射好的(虚拟地址与物理地址的映射,通过MMU实现),可以供进程访问;而从break往上,是未映射的地址空间,如果访问这段空间则程序会报错。
所以,如果Mapped Region 空间不够时,会调整break指针,扩大映射空间,重新分配内存。
三、调整break:brk()和sbrk()
最初break的位置正好位于bss端末尾之后,看图1,在break指针的位置升高时,程序可以访问新分配区域内的任何内存地址,而此时物理内存页尚未分配,内存会在京城首次试图访问这些虚拟内存地址时自动分配新的物理内存页。
linux通过brk和sbrk系统调用操作break指针:
int brk(void *addr);
void *sbrk(intptr_t increment);brk() 将break指针设置为 addr 所指定的位置,由于虚拟内存以页为单位进行分配,addr实际会四舍五入到下一个内存也的边界处。
由于brk是直接指定一个地址,所以一旦这个值取得过低,有可能导致不可预知的行为,对照图1,brk只能在指定的区域内调整break。
sbrk() 将break指针在原有地址增加从参数 increment 传入的大小(linux中,sbrk是基于brk基础上实现的一个库函数),用于声明increment 的intptr_t 类型属于整数数据类型。
若调用成功,sbrk() 返回前一个break 的地址,换言之,如果break 增加,那么返回值是指向这块新分配内存起始位置的指针。
sbrk(0) 将得到当前break指针的位置。
系统对每一个进程所分配的资源不是无限的,包括可映射的内存空间,图2,未映射内存的尾端有个rlimit表示当前进程可用的资源上限。
三、malloc
根据标准C库函数的定义,malloc 具有如下模型:
void* malloc(size_t size);这个函数要实现的功能是在系统中分配一段连续的可用的内存,具体有如下要求:
- malloc分配的内存大小至少为size参数所指定的字节数
- malloc的返回值是一个指针,指向一段可用内存的起始地址
- 多次调用malloc所分配的地址不能有重叠部分,除非该地址已经被释放掉
- malloc应该尽快完成内存分配并返回(不能使用NP-hard的内存分配算法)
- 实现malloc时,应该同时实现内存大小调整和内存释放函数(calloc和free)
- malloc分配失败时必须返回NULL
malloc 返回内存块所采用的字节对齐方式,总是适宜于高效访问任何类型的C语言数据结构。
四、初探实现malloc:
我们假定整个内存处于初始状态,即break指针位于bss段的单位,整个heap都是 Unmapped Region。(图2)
基于此,我们可以实现一个简单但毫无实际价值的malloc:
/*一个糟糕的仿制malloc*/
#include <sys/types.h>
#incldue <unistd.h>
void *malloc(size_t size)
{
void *p;
p = sbrk(0);
/*如果sbrk失败,返回NULL*/
if(sbrk(size) == (void*)-1)
return NULL;
return p;
}这个malloc就是从未映射区域直接划出一块,但是malloc对这块已分配的内存缺乏记录,不便于内存释放。
五、正式实现malloc
上面说到分配的内存没有记录,一旦调用free释放,free不知道它到底要释放多大的内存,所以我们需要额外一个数据结构来记录这些信息。
5.1、数据结构
一个简单可行方案是将堆内存以块的形式组织起来,每个块(block)由meta区和数据区组成,meta去记录数据块的元信息(数据块大小、空闲标志位、指针等),数据区则是真实分配的内存区域,并且数据区的第一个字节地址即为malloc返回的地址。
可用如下结构体定义一个block:
typedef struct s_block *t_block;
struct s_block{
size_t size;//数据区大小
t_block next;//指向下个块的指针
int free;//是否是空闲块
char data[1];//虚拟字段,表示数据块的第一个字节,长度不计入meta
};图3

那么用这个结构体来分配内存,而不用malloc则是下面一番场景:
t_block b;
b = sbrk(0);
sbrk(sizeof(struct s_block) + size);
b->size = size;//size 为要分配的内存大小5.2、寻找合适的block
我们从堆的起始地址开始查找第一个符合要求的block,并返回block起始地址,如果找不到就返回NULL;
t_block find_block(t_block *last, size_t size)
{
t_block b = base;
while(b && !(b->free && b->size >= size))
{
*last = b;
b = b->next;
}
return b;
}这里base是一个全局变量,维护整个堆的起始地址。另外,这里在遍历时会更新一个last指针,这个指针始终指向当前遍历的block,如果找不到合适的block,那么malloc将很容易的开辟新的block使用。
5.3、开辟新的block
如果现有block都不能满足需求,则需要在链表最后开辟一个新的block。最简单的方式就是利用sbrk升高break位置然后对其初始化,然后更新对应block指针,将其add到链表最后。
t_block extend_heap(t_block last, size_t size)
{
t_block b;
b = sbrk(0);//定位到当前break位置
if(sbrk(sizeof(struct s_block) + size) == (void*)-1)//调整break位置
return NULL;
b->size = size;
b->next = NULL;
if(last)//这个last是指向extend之前最后一个block
last->next = b;//新开辟的block挂载在链表中
b->free = 0;
return b;
}5.4、分裂block
看前面 find_block() 的实现,如果我们申请的 size 远小于查找到的 block。(这种情况是可能,它是查到第一个满足条件(大小,可用)的block),这样会导致较大内部碎片的产生。
所以,应该在剩余数据区足够大的情况下,将其分裂成一个新的block:
图4
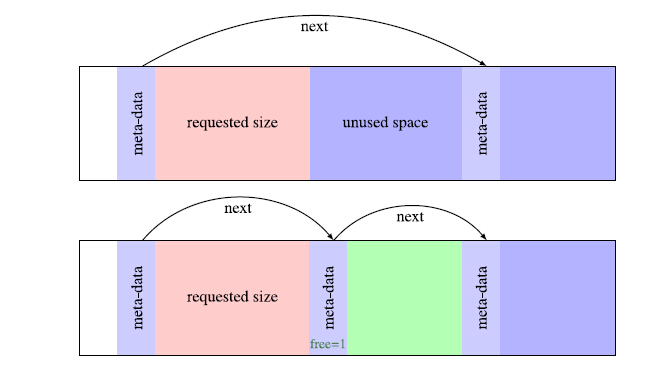
//b是要分裂的block,size是申请的内存大小
//分裂后b成了分配后的block
void split_block(t_block b, size_t size)
{
t_block new;//新的空闲block = 要分裂的block - 申请分配出去的内存
new = b->data + size;//将new定位到剩下的数据块区域
//分裂的原block-分配出去的内存大小-block结构体本身大小
new->size = b->size - size - BLOCK_SIZE;
new->next = b->next;//链表插入
new->free = 1;//空闲标记可用
b->size = size;
b->next = new;//链表插入
}看了上面一大串,是不是跟伙伴算法很像。但是这里的分裂block函数,得视情况调用,如果申请的size < block->size,但是又不是小太多,如果分裂block的话,会导致分裂后剩余未分配出去的数据块过小,无法满足其余需求,很容易形成内存碎片。
所以,伙伴算法有更高效的处理(实际上伙伴算法也会产生内部碎片)。
5.5、malloc 的实现
铺垫做了那么多,我们可以利用它们整合成一个简单可用的malloc。
首先定义一个block链表的头指针,初始化为NULL,另外,我们需要剩余空间至少有 BLOCK_SIZE + 4 才执行分离操作。
此外,一开始我们讲到,malloc对分配的内存大小也有要求,是按4字节对齐,所以申请的size不为4的倍数时,我们需要将其调整为大于size的最小的4的倍数。
#define align4(x) (((((x)-1)>>2)<<2)+4)
#define BLOCK_SIZE 12
void *base = NULL;
void *malloc(size_t size)
{
t_block b, last;
size_t s;
s = align4(size);
if(base)
{
//first find a block
last = base;
b = find_block(&last, s);
if(b)
{
//can we split
if((b->size - s) >= (BLOCK_SIZE + 8))
split_block(b, s);
b->free = 0;
}
else
{
//no fitting block, extend the heap
b = extend_heap(last, s);
if(!b)
return NULL;
}
}
else
{
//first time
b = extend_heap(NULL, s);
if(!b)
return NULL;
base = b;
}
return b->data;
}实现思路很简单:首先往链表中查找合适的block,如果找到了,看是否可以分裂,如果可以就分裂;如果没有找到合适的,就开辟一个新的block;如果是第一次分配,即整个内存链表不存在,则一开始就得新开辟一个block。
六、calloc 的实现
先看calloc的标准库语义:函数 calloc() 用于给一组相同对象分配内存。
void *calloc(size_t numitems, size_t size)参数numitems指定分配对象的数量,size指定每个对象的大小。
calloc 与之malloc 不同之处在于,calloc 会将分配后的内存空间初始化,而malloc 申请的是一块未初始化的内存。
所以,实现calloc,只需两步:
- malloc 一块内存
- 将数据区内容初始化为0
void *calloc(size_t numitems, size_t size)
{
size_t *new;
size_t s, i;
new = malloc(numitems * size);
if(new)
{
//因为申请的内存总是4的倍数,所以这里我们以4字节为单位初始化
s = align4(numitems * size) >> 2;
for(i = 0; i < s; ++i)
new[i] = 0;
}
return new;
}七、free 的实现
free 的实现并不像看上去那么简单,需要解决两个关键问题:
- 如何验证所传入的地址是有效地址(malloc方式分配的)
- 如何解决碎片问题
7.1、先看如何解决碎片问题,就是把相邻的空闲内存合并为大的(伙伴算法类似):
//合并相邻空闲的内存块,参数决定合并的是上一个还是下一个
t_block fusion(t_block b)
{
if(b->next && b->next->free)
{
b->size += BLOCK_SIZE + b->next->size;
b->next = b->next->next;
if(b->next)
b->next->prev = b;
}
return b;
}再看如何验证所传入的地址是有效的,位于heap内。
一个解决方法是,在block结构体中添加一个 ptr 指针,用于指向数据块区域,如果 b->ptr == b->data,则表示 b 极有可能是一个有效block。
所以我们对block数据结构进行了扩展:
struct s_block{
size_t size;//数据区大小
t_block next;//指向下个块的指针
int free;//是否是空闲块
struct s_block *next;
struct s_block *prev;
void *ptr;
char data[1];
};7.2、根据给定地址得到对应的block
//注意,这个函数最后通过偏移量得到的block可能是有效的,可能不是有效的
t_block get_block(void *p)
{
char *tmp;
tmp = p;
return (p = tmp -= BLOCK_SIZE);
}7.3、下面则验证是不是有效的block:
int valid_addr(void *p)
{
if(base)
{
if(p > base && p < sbrk(0))
return (p == (get_block(p))->ptr);
//如果两个字段地址一样,表示是一个有效block
}
return 0;
}7.4、下面就实现free
这里我们采用的合并策略是这样的:先合并相邻的空闲内存块,合并之后,再检查是否还有空闲的相邻内存块,如果有则继续合并,直到最后,该内存块是最大的连续内存块。
另外,对于break指针的调整(降低),必须保证在该释放的block与 Unmapped Region之间是空闲的,没有被占。
void free(void *p)
{
t_block b;
if(valid_addr(p))//地址的有效性验证
{
b = get_block(p);//得到对应的block
b->free = 1;
//如果相邻的上一块内存是空闲的就合并,
//合并之后的上一块还是空闲的就继续合并,直到不能合并为止
while(b->prev && b->prev->free)
{
b = fusion(b->prev);
}
//同理去合并后面的空闲block
while(b->next)
fusion(b);//内部会判断是否空闲
//如果当前block是最后面的那个block,此时可以调整break指针了
if(NULL == b->next)
{
if(b->prev)//当前block前面还有占用的block
b->prev->next = NULL;
else//当前block就是整个heap仅存的
base = NULL;//则重置base
brk(b);//调整break指针到b地址位置
}
//否则不能调整break
}
}八、realloc的实现
同样先看标准库中realloc的语义:
void *realloc(void *ptr, size_t size)ptr 是指向需要调整大小的内存块的指针,参数 size 指定所需调整大小的期望值。
realloc() 用来调整(通常是增加)一块内存的大小,而此块内存应是之前由malloc函数分配的。若 realloc 增加了已分配内存块的大小,则不会对额外分配的内存进行初始化。
8.1、内存块复制
看了realloc的语义,我们首先得实现一个内存复制方法。如同calloc一样,我们以4字节为单位进行复制:
void copy_block(t_block src, t_block dst)
{
int *sdata, *dtata;
size_t i;
sdata = src->ptr;
ddata = dst->ptr;
for(i = 0; i*4 < src->size && i*4 < dst->size; ++i)
ddata[i] = sdata[i];
}8.2、实现realloc
为了更高效,我们考虑以下几个方面:
- 如果当前block的数据区大于等于realloc要求的size,则考虑能不能split,然后直接返回
- 如果新的size变小了,考虑split
- 如果当前block的数据区不能满足size,但是其后继block是free,并且合并后可以满足size,则考虑合并,然后再考虑能不能split
- 如果以上都不行,则调用malloc重新分配size大小内存,然后内存复制
void *realloc(void *p, size_t size)
{
size_t s;
t_block b, new;
void *newp;
if(!p)
return malloc(size);
if(valid_addr(p))
{
s = align4(size);
b = get_block(p);//得到对应的block
if(b->size >= s)//如果size变小了,考虑split
{
if(b->size - s >= (BLOCK_SIZE + 4))
split_block(b, s);
}
else//如果当前block的数据区不能满足size
{
//如果后继block是free的,并且合并后大小满足size,考虑合并
if(b->next && b->next->free
&& (b->size + BLOCK_SIZE + b->next->size) >= s)
{
fusion(b);
//合并后满足size,再看能不能split
if(b->size - s >= (BLOCK_SIZE + 4))
split_block(b, s);
}
else//以上都不满足,则malloc新区域
{
newp = malloc(s);
if(!newp)
return NULL;
//内存复制
new = get_block(newp);
copy_block(b, new);
free(p);//释放old
return newp;
}
}
return p;//当前block数据区大于size时
}
return NULL;
}九、总结
以上是一个比较简陋,存在很大的优化空间,但大致阐述了malloc的机制,这也是本篇博文的目的。
对于更好的优化读者可以参考linux内核伙伴算法、以及STL空间配置器。
十、参考资料:
1、《Advanced Programming in the UNIX Environment》
2、《The Linux Programming Interface》
3、 A Malloc Tutorial















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









