




 本文探讨了irqbalance的工作原理,旨在优化中断分配,提升系统性能。通过分析代码,介绍了irqbalance如何根据NUMA架构和smp_affinity进行中断分配。文章详细讲解了数据结构、中断类型、分配策略以及平衡算法,并提供了流程概述。
本文探讨了irqbalance的工作原理,旨在优化中断分配,提升系统性能。通过分析代码,介绍了irqbalance如何根据NUMA架构和smp_affinity进行中断分配。文章详细讲解了数据结构、中断类型、分配策略以及平衡算法,并提供了流程概述。
深入代码详谈irqbalance
之前在工作中简单研究了一下irqbalance,主要为了解决当时网卡性能问题,现在简单分享一点心得,希望能对大家有一丝帮助,也欢迎大家一起讨论。
总结的时候做了一个ppt,感兴趣的同学可以瞅瞅
http://download.csdn.net/detail/whrszzc/9413678
本例是采用的1.0.6版本的irqbalance,代码可以在下面网址获取:
https://github.com/Irqbalance/irqbalance
话说在前面,由于本人很讨厌直接贴上代码的不负责行为,这里虽然是深入代码详谈,但以总结心得为主,代码只给出个流程。
首先,借用网上的找来的一段介绍,稍微了解下irqbalance的功能:
irqbalance用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance mode 或 Power-save mode。
处于Performance mode 时,irqbalance 会将中断尽可能均匀地分发给各个 CPU core,以充分利用 CPU 多核,提升性能。
处于Power-save mode 时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲 CPU 的睡眠时间,降低能耗。(暂不讨论这种模式)
简单来说,Irqbalance的主要功能是优化中断分配,收集系统数据并分析,通过修改中断对于cpu的亲和性来尽量让中断合理的分配到各个cpu,以充分利用多核cpu,提升性能。
分析代码之前,首先来了解两个概念,numa架构和smp_affinity。
简单画个图来解释下numa:
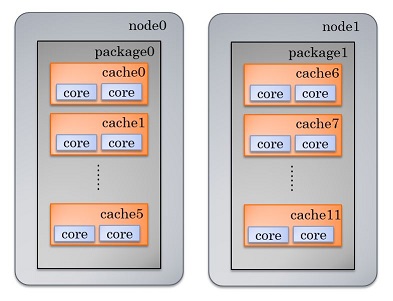
NUMA模式是一种分布式存储器访问方式,处理器可以同时访问不同的存储器地址,大幅度提高并行性。 NUMA模式下,处理器被划分成多个”节点”(node), 每个节点被分配有的本地存储器空间。 所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多。
irqbalance就是根据这种架构来分配中断的。主要的原因是避免终端在节点中迁移产生过多的代价。
smp_affinity是用来设置中断亲缘的CPU的mask码,简单来说就是在cpu上分配中断。
SMP affinity is controlled by manipulating files in the /proc/irq/ directory.
In /proc/irq/ are directories that correspond to the IRQs present on your
system (not all IRQs may be available). In each of these directories is
the “smp_affinity” file, and this is where we will work our magic.
好的,废话不多说,下面在代码层面介绍irqbalance,具体的流程会在最后贴出。
首先看一下irqbalance用到的数据结构是什么样的:
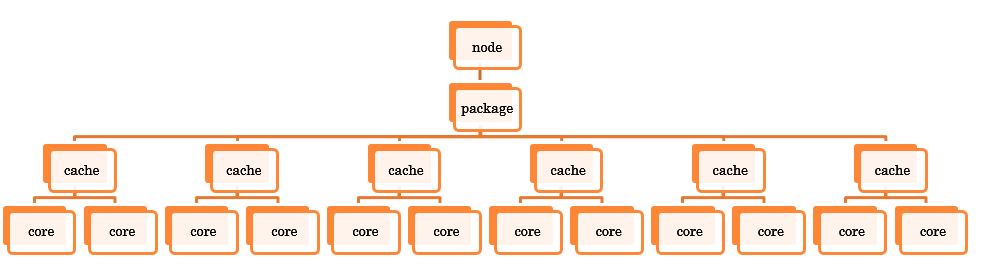
简单说就是根据cpu的结构由上到下建立了一个树形结构,当然,为了平衡终端,每个节点还会挂接本节点分配的中断。
树形结构建立好之后,自然是开始分配中断。irqbalance中把中断分成了八种类型:
#define IRQ_OTHER 0
#define IRQ_LEGACY 1
#define IRQ_SCSI 2
#define IRQ_TIMER 3
#define IRQ_ETH 4
#define IRQ_GBETH 5
#define IRQ_10GBETH 6
#define IRQ_VIRT_EVENT 7依据就是pci设备初始化时注册的类型:/sys/bus/pci/devices/0000:00:01.0/class
每种中断类型又分别对应一种分配方式,分配方式一共有四种:
BALANCE_PACKAGE
BALANCE_CACHE
BALANCE_NONE
BALANCE_CORE代表中断的分配范围,不急,接着看一下具体的分配方式:
首先是中断在numa_node中分配,有两种情况:
/sys/bus/pci/devices/0000:00:01.0/numa_node中指定了非-1的numa_node,则把中断分配到对应的numa;如果是-1的话,则根据中断数平均的分到两个numa
分配好numa_node之后开始在整个树中进行分配,分配哪一个层次的原则是
BALANCE_NONE分配在numa_node层
BALANCE_PACKAGE分配在package层
BALANCE_CACHE分配在cache层
BALANCE_CORE分配在core层决定出那一层之后,最后就是在每个层次中分配节点,原则是分配在负载最小的子节点,如果负载相同则分配在中断种类最少的节点
那么问题又来了,负载是个什么概念呢?
每个节点有各自的负载,自下而上进行计算。
处于最底层的每个逻辑cpu的负载的计算方法是:
在/proc/stat获取每个cpu的信息如下
cpu0 2383 0 298701 468097 158010 572 121175 0 0 0
取第6、7项,分别代表从系统启动开始累计到当前时刻,硬中断、软中断时间(单位是jiffies),然后将累加的值转换成纳秒单位,转换方法是:和*1*10^9/HZ。
了解了逻辑cpu的负载的计算方法不难得到负载所表示的意义:单位时间(10s)内,cpu处理软中断加上硬中断的时间的和
逻辑cpu这一层的负载计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









