




 本文探讨了Hadoop在处理小文件时面临的问题,并介绍了Hadoop提供的几种解决方案,包括HadoopArchive、Sequencefile和CombineFileInputFormat,旨在提高系统的性能和效率。
本文探讨了Hadoop在处理小文件时面临的问题,并介绍了Hadoop提供的几种解决方案,包括HadoopArchive、Sequencefile和CombineFileInputFormat,旨在提高系统的性能和效率。
小文件指的是那些size比HDFS的block size(默认64M)小的多的文件。Hadoop适合处理少量的大文件,而不是大量的
小文件。
1, 小文件导致的问题
首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有1000 0000个小文件,每个文件占用一个block,则namenode大约需要2G空间。如果存储1亿个文件,则namenode需要20G空间。这样namenode内存容量严重制约了集群的扩展。其次,访问大量小文件速度远远小于访问几个大文件。HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能。
最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
2,Hadoop自带的解决方案
对于小文件问题,Hadoop本身也提供了几个解决方案,分别为:Hadoop Archive,Sequence file和CombineFileInputFormat。
(1) Hadoop Archive
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。对某个目录/foo/bar下的所有小文件存档成/outputdir/ zoo.har:
hadoop archive -archiveName zoo.har -p /foo/bar /outputdir
当然,也可以指定HAR的大小(使用-Dhar.block.size)。
HAR是在Hadoop file system之上的一个文件系统,因此所有fs shell命令对HAR文件均可用,只不过是文件路径格式不一样,HAR的访问路径可以是以下两种格式:
har://scheme-hostname:port/archivepath/fileinarchive
har:///archivepath/fileinarchive(本节点)
可以这样查看HAR文件存档中的文件:
hadoop dfs -ls har:///user/zoo/foo.har
输出:
har:///user/zoo/foo.har/hadoop/dir1
har:///user/zoo/foo.har/hadoop/dir2
使用HAR时需要两点,第一,对小文件进行存档后,原文件并不会自动被删除,需要用户自己删除;第二,创建HAR文件的过程实际上是在运行一个mapreduce作业,因而需要有一个hadoop集群运行此命令。
此外,HAR还有一些缺陷:第一,一旦创建,Archives便不可改变。要增加或移除里面的文件,必须重新创建归档文件。第二,要归档的文件名中不能有空格,否则会抛出异常,可以将空格用其他符号替换(使用-Dhar.space.replacement.enable=true 和-Dhar.space.replacement参数)。第三,存档文件不支持压缩。
一个归档后的文件,其存储结构如下图:
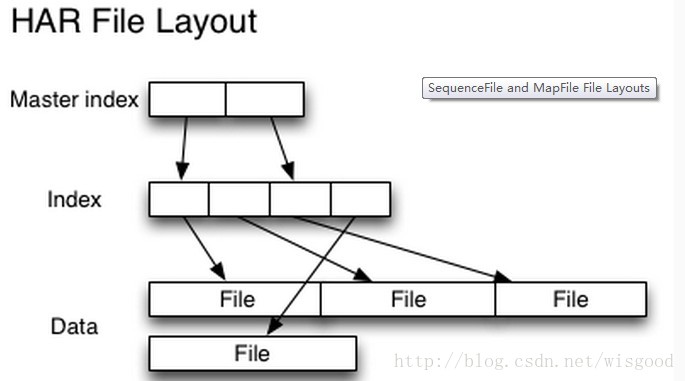
(2) Sequence file
Sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。Hadoop-0.21.0中提供了SequenceFile,包括Writer,Reader和SequenceFileSorter类进行写,读和排序操作。

创建sequence file的过程可以使用mapreduce工作方式完成,对于index,需要改进查找算法
优缺点:对小文件的存取都比较自由,也不限制用户和文件的多少,但是该方法不能使用append方法,所以适合一次性写入大量小文件的场景

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









