






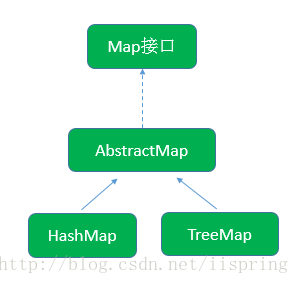
HashMap继承自抽象类AbstractMap,抽象类AbstractMap实现了Map接口。关系图如下所示:
Java中的Map<key, value>接口允许我们将一个对象作为key,也就是可以用一个对象作为key去查找另一个对象。
在我们探讨HashMap的实现原理之前,我们先自己实现了一个SimpleMap类,该类继承自AbstractMap类。具体实现如下:
- import java.util.*;
- public class SimpleMap<K,V> extends AbstractMap<K,V> {
- //keys存储所有的键
- private List<K> keys = new ArrayList<K>();
- //values存储所有的值
- private List<V> values = new ArrayList<V>();
- /**
- * 该方法获取Map中所有的键值对
- */
- @Override
- public Set entrySet() {
- Set<Map.Entry<K, V>> set = new SimpleSet<Map.Entry<K,V>>();
- //keys的size和values的size应该一直是一样大的
- Iterator<K> keyIterator = keys.iterator();
- Iterator<V> valueIterator = values.iterator();
- while(keyIterator.hasNext() && valueIterator.hasNext()){
- K key = keyIterator.next();
- V value = valueIterator.next();
- SimpleEntry<K,V> entry = new SimpleEntry<K,V>(key, value);
- set.add(entry);
- }
- return set;
- }
- @Override
- public V put(K key, V value) {
- V oldValue = null;
- int index = this.keys.indexOf(key);
- if(index >= 0){
- //keys中已经存在键key,更新key对应的value
- oldValue = this.values.get(index);
- this.values.set(index, value);
- }else{
- //keys中不存在键key,将key和value作为键值对添加进去
- this.keys.add(key);
- this.values.add(value);
- }
- return oldValue;
- }
- @Override
- public V get(Object key) {
- V value = null;
- int index = this.keys.indexOf(key);
- if(index >= 0){
- value = this.values.get(index);
- }
- return value;
- }
- @Override
- public V remove(Object key) {
- V oldValue = null;
- int index = this.keys.indexOf(key);
- if(index >= 0){
- oldValue = this.values.get(index);
- this.keys.remove(index);
- this.values.remove(index);
- }
- return oldValue;
- }
- @Override
- public void clear() {
- this.keys.clear();
- this.values.clear();
- }
- @Override
- public Set keySet() {
- Set<K> set = new SimpleSet<K>();
- Iterator<K> keyIterator = this.keys.iterator();
- while(keyIterator.hasNext()){
- set.add(keyIterator.next());
- }
- return set;
- }
- @Override
- public int size() {
- return this.keys.size();
- }
- @Override
- public boolean containsValue(Object value) {
- return this.values.contains(value);
- }
- @Override
- public boolean containsKey(Object key) {
- return this.keys.contains(key);
- }
- @Override
- public Collection values() {
- return this.values();
- }
- }
当子类继承自AbstractMap类时,我们只需要实现AbstractMap类中的entrySet方法和put方法即可,entrySet方法是用来返回该Map所有键值对的一个Set,put方法是实现将一个键值对放入到该Map中。
大家可以看到,我们上面的代码不仅除了实现entrySet和put方法外,我们还重写了get、remove、clear、keySet、values等诸多方法。其实我们只要重写entrySet和put方法,该类就可以正确运行,那我们为什么还要重写剩余的那些方法呢?AbstractMap这个方法做了很多处理操作,Map中的很多方法在AbstractMap都实现了,而且很多方法都依赖于entrySet方法,举个例子,Map接口中的values方法是让我们返回该Map中所有的值的Collection。我们可以看一下AbstractMap中对values方法的实现:
- public Collection<V> values() {
- if (values == null) {
- values = new AbstractCollection<V>() {
- public Iterator<V> iterator() {
- return new Iterator<V>() {
- private Iterator<Entry<K,V>> i = entrySet().iterator();
- public boolean hasNext() {
- return i.hasNext();
- }
- public V next() {
- return i.next().getValue();
- }
- public void remove() {
- i.remove();
- }
- };
- }
- public int size() {
- return AbstractMap.this.size();
- }
- public boolean isEmpty() {
- return AbstractMap.this.isEmpty();
- }
- public void clear() {
- AbstractMap.this.clear();
- }
- public boolean contains(Object v) {
- return AbstractMap.this.containsValue(v);
- }
- };
- }
- return values;
- }
大家可以看到,代码不少,基本的思路是先通过entrySet生成包含所有键值对的Set,然后通过迭代获取其中的value值。其中生成包含所有键值对的Set肯定需要开销,所以我们在自己的实现里面重写了values方法,就一句话,return this.values,直接返回我们的values字段。所以我们重写大部分方法的目的都是让方法的实现更快更简洁。
大家还需要注意一下,我们在重写entrySet方法时,需要返回一个包含当前Map所有键值对的Set。首先键值对时一种类型,所有的键值对类都要实现Map.Entry<K,V>这个接口。其次,由于entrySet要让我们返回一个Set,这里我们没有使用Java中已有的Set类型(比如HashSet、TreeSet),有两方面的原因:
1. Java中HashSet这个类内部其实用HashMap实现的,本博客的目的就是要研究HashMap,所以我们不用此类;
2. Java中Set的实现也不是很麻烦,自己实现一下AbstractSet,加深一下对Set的理解。
以下是我们自己实现的键值对类SimpleEntry,实现了Map.Entry<K,V>接口,代码如下:
- import java.util.Map;
- //Map中存储的键值对,键值对需要实现Map.Entry这个接口
- public class SimpleEntry<K,V> implements Map.Entry<K, V>{
- private K key = null;//键
- private V value = null;//值
- public SimpleEntry(K k, V v){
- this.key = k;
- this.value = v;
- }
- @Override
- public K getKey() {
- return this.key;
- }
- @Override
- public V getValue() {
- return this.value;
- }
- @Override
- public V setValue(V v) {
- V oldValue = this.value;
- this.value = v;
- return oldValue;
- }
- }
以下是我们自己实现的集合类SimpleSet,继承自抽象类AbstractSet<K,V>,代码如下:
- import java.util.AbstractSet;
- import java.util.ArrayList;
- import java.util.Iterator;
- public class SimpleSet<E> extends AbstractSet<E> {
- private ArrayList<E> list = new ArrayList<E>();
- @Override
- public Iterator<E> iterator() {
- return this.list.iterator();
- }
- @Override
- public int size() {
- return this.list.size();
- }
- @Override
- public boolean contains(Object o) {
- return this.list.contains(o);
- }
- @Override
- public boolean add(E e) {
- boolean isChanged = false;
- if(!this.list.contains(e)){
- this.list.add(e);
- isChanged = true;
- }
- return isChanged;
- }
- @Override
- public boolean remove(Object o) {
- return this.list.remove(o);
- }
- @Override
- public void clear() {
- this.list.clear();
- }
- }
我们测试下我们写的SimpleMap这个类,测试包括两部分,一部分是测试我们写的SimpleMap是不是正确,第二部分测试性能如何,测试代码如下:
- import java.util.HashMap;
- import java.util.HashSet;
- import java.util.Map;
- public class Test {
- public static void main(String[] args) {
- //测试SimpleMap的正确性
- SimpleMap<String, String> map = new SimpleMap<String, String>();
- map.put("iSpring", "27");
- System.out.println(map);
- System.out.println(map.get("iSpring"));
- System.out.println("-----------------------------");
- map.put("iSpring", "28");
- System.out.println(map);
- System.out.println(map.get("iSpring"));
- System.out.println("-----------------------------");
- map.remove("iSpring");
- System.out.println(map);
- System.out.println(map.get("iSpring"));
- System.out.println("-----------------------------");
- //测试性能如何
- testPerformance(map);
- }
- public static void testPerformance(Map<String, String> map){
- map.clear();
- for(int i = 0; i < 10000; i++){
- String key = "key" + i;
- String value = "value" + i;
- map.put(key, value);
- }
- long startTime = System.currentTimeMillis();
- for(int i = 0; i < 10000; i++){
- String key = "key" + i;
- map.get(key);
- }
- long endTime = System.currentTimeMillis();
- long time = endTime - startTime;
- System.out.println("遍历时间:" + time + "毫秒");
- }
- }
输出结果如下:
{iSpring=27}
27
-----------------------------
{iSpring=28}
28
-----------------------------
{}
null
-----------------------------
遍历时间:956毫秒
从结果里面我们看到输出结果是正确的,也就是我们写的SimpleMap基本实现都是对的。我们往Map中插入了10000个键值对,我们测试的是从Map中取出这10000条键值对的性能开销,也就是测试Map的遍历的性能开销,结果是956毫秒。
没有对比就不知性能强弱,我们测试下HashMap读取这10000条键值对的时间开销,测试方法完全一样,只是我们传入的是HashMap的实例,测试代码如下:
- //创建HashMap的实例
- HashMap<String, String> map = new HashMap<String, String>();
- //测试性能如何
- testPerformance(map);
测试结果如下:
遍历时间:32毫秒
我去,不比不知道,一比吓一跳啊,HashMap比我们自己实现的SimpleMap快的那不是一点半点啊。为什么我们的SimpleMap性能这么差?而HashMap的性能如此高呢?我们分别研究。
首先分析SimpleMap性能为什么这么差。
我们的SimpleMap是用ArrayList来存储keys和values的,ArrayList本质是用数组实现的,我们的SimpleMap的get方法是这样实现的:
- @Override
- public V put(K key, V value) {
- V oldValue = null;
- int index = this.keys.indexOf(key);
- if(index >= 0){
- //keys中已经存在键key,更新key对应的value
- oldValue = this.values.get(index);
- this.values.set(index, value);
- }else{
- //keys中不存在键key,将key和value作为键值对添加进去
- this.keys.add(key);
- this.values.add(value);
- }
- return oldValue;
- }
需要性能开销的主要是this.keys.indexOf(key)这句代码,这句代码从ArrayList中查找指定元素的索引,本质就是从数组开头走,往后找,直至数组的末尾。如下图所示:

这样从头开始查找,并且每次在遍历元素的时候,都需要调用元素的equals方法,所以从头开始查找就会导致调用很多次equals方法,这就造成了SimpleMap效率低下。比如我们将全国的车辆放入到SimpleMap中时,我们是依次将车辆放到ArrayList的最后面,依次往后插入值,车牌号就相当于key,车辆就好比是value,所以SimpleMap中有两个长度很长的ArrayList,分别存储keys和values,如果要在该SimpleMap中查找一辆车,车牌是"鲁E.DE829",那如果用ArrayList查找的话就要从全国的的所有车辆中去查找了,这样太慢。
那么HashMap为何效率如此高呢?
HashMap比较聪明,大家可以看看HashMash.java的源码,HashMap把里面的元素分类放置了,还拿上面根据车牌号查找车辆的例子来说,当把我们把车辆往HashMap里面放的时候,HashMap将它们分类处理了,首先来一辆车的时候,先看其车牌号,比如车牌号是"鲁E.DE829",一看是鲁,就知道是山东的车辆,那么HashMap就开辟了一块空间,专门放山东的车,就把这辆车放到这块山东专属的区间了,下次又要向HashMap放入一辆车牌号为“浙A.GX588",HashMap一看是浙江的车,就将这辆车放入到浙江的专属区间了,依次类推。说的再通俗点,假设我们有一种很大的桶,该桶就是相应的区间,可以装下很多车,如下图所示:
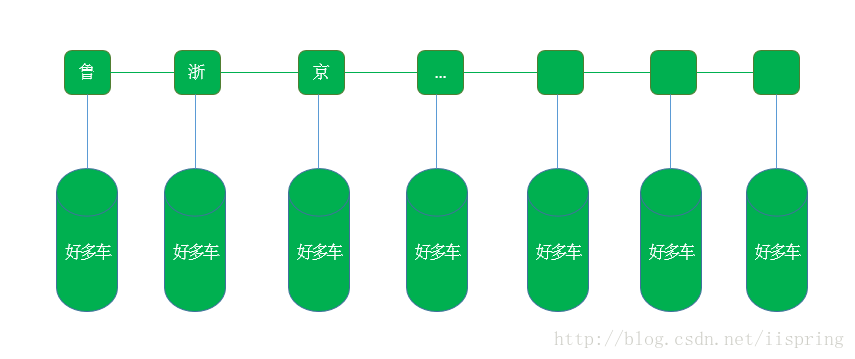
当我们从HashMap中根据车牌号查找指定的车辆时,比如查找车牌号为为"鲁E.DE829"的车,当调用HashMap的get方法时,HashMap一看车牌号是鲁,那么HashMap就去标为鲁的那个大桶,也就是山东区间去找这辆车了。这样就没有必要从全国的车辆中挨个找这辆车了,这就大大缩短了查找空间,提高了效率。
我们可以看看HashMap.java中具体的源码实现,
HashMap中用一个名为table的字段存储着一个Entry数组,table存储着HashMap里面的所有键值对,每个键值对都是一个Entry对象。每个Entry对象都存储着一个key和value,除此之外每个Entry内部还存着一个next字段,next也是Entry类型。数组table的默认长度是DEFAULT_INITIAL_CAPACITY,即初始长度为16,当容器需要更多的空间存取Entry时,它会自动扩容。
以下是HashMap的put方法的源码实现:
- public V put(K key, V value) {
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key.hashCode());
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- addEntry(hash, key, value, i);
- return null;
- }
在put方法中,,调用了对象的hashCode方法,该方法返回一个int类型的值,是个初始的哈希值,这个值就相当于车牌号,例如"鲁E.DE829",HashMap中有个hash方法,该hash方法将我们得到的初始的哈希值做进一步处理,得到最终的哈希值,就好比我们将车牌号传入hash方法,然后返回该存放车辆的大桶,即返回"鲁",这样HashMap就把这辆车放到标有“鲁”的大桶里面了。 上面说到的hash方法叫做哈希函数,专门负责根据传入的值返回指定的最终哈希值,具体实现如下:
- static int hash(int h) {
- // This function ensures that hashCodes that differ only by
- // constant multiples at each bit position have a bounded
- // number of collisions (approximately 8 at default load factor).
- h ^= (h >>> 20) ^ (h >>> 12);
- return h ^ (h >>> 7) ^ (h >>> 4);
- }
可以看出来,HashMap中主要是通过位操作符实现哈希函数的。这里简单说一下哈希函数,哈希函数有多种实现方式,比如最简单的就是取余法,比如对i%10取余,然后按照余数创建不同的区块或桶。比如有100个数,分别是从1到100,那么分别对10取余,那么就可以把这100个数放到10个桶子里面了,这就是所谓的哈希函数。只不过HashMap中的hash函数看起来比较复杂,进行的是位操作,但是其作用与简单的取余哈希法的作用是等价的,就是把元素分类放置。
具体将键值对放入到HashMap中的方法是addEntry,代码如下:
- void addEntry(int hash, K key, V value, int bucketIndex) {
- Entry<K,V> e = table[bucketIndex];
- table[bucketIndex] = new Entry<>(hash, key, value, e);
- if (size++ >= threshold)
- resize(2 * table.length);
- }
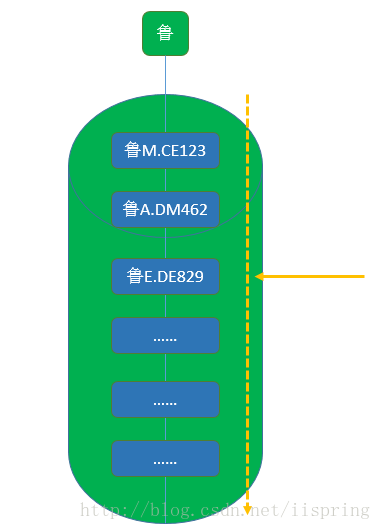
键值对都是Map.Entry<K,V>对象,并且Map.Entry具有next字段,也就是桶里面的元素都是通过单向链表的形式将Map.Entry串连起来的,这样我们就可以从桶上的第一个元素通过next依次遍历完桶里面所有的元素。比如桶中有如下键值对:
桶-->e1-->e2-->e3-->e4-->e5-->e6-->e7-->e8-->e9-->...
addEntry代码首先取出桶里面的第一个键值对e1,然后将新的键值对e置于桶中第一个元素的位置,然后将键值对e1放置于新键值对e后面,放置完之后,桶中新的键值对如下:
桶-->e-->e1-->e2-->e3-->e4-->e5-->e6-->e7-->e8-->e9-->...
这样就把新的键值对放到了桶中了,也就将键值对放到HashMap中了。
那么当我们从HashMap中查找某个键值对时,怎么查找呢?原理与我们将键值对放入HashMap相似,
以下是HashMap的get方法的源码实现:
- public V get(Object key) {
- if (key == null)
- return getForNullKey();
- int hash = hash(key.hashCode());
- for (Entry<K,V> e = table[indexFor(hash, table.length)];
- e != null;
- e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
- return e.value;
- }
- return null;
- }
在get方法中,也是先调用了对象的hashCode方法,就相当于车牌号,然后再将该值让hash函数处理得到最终的哈希值,也就是桶的索引。然后我们再去这个标有“鲁”的桶里面去找我们的键值对,首先先取出桶里面第一个键值对,比对一下是不是我们要找的元素,如果是就直接返回了,如果不是就通过键值对的next顺藤摸瓜通过单向链表继续找下去,直至找到。 如下图所示:
下面我们再写一个Car类,该类有一个字段String类型的字段num,并且我们重写了Car的equals方法,我们认为只要车牌号相等就认为这是同一辆车。代码如下所示:
- import java.util.HashMap;
- public class Car {
- private final String num;//车牌号
- public Car(String n){
- this.num = n;
- }
- public String getNum(){
- return this.num;
- }
- @Override
- public boolean equals(Object obj) {
- if(obj == null){
- return false;
- }
- if(obj instanceof Car){
- Car car = (Car)obj;
- return this.num.equals(car.num);
- }
- return false;
- }
- public static void main(String[] args){
- HashMap<Car, String> map = new HashMap<Car, String>();
- String num = "鲁E.DE829";
- Car car1 = new Car(num);
- Car car2 = new Car(num);
- System.out.println("Car1 hash code: " + car1.hashCode());
- System.out.println("Car2 hash code: " + car2.hashCode());
- System.out.println("Car1 equals Car2: " + car1.equals(car2));
- map.put(car1, new String("Car1"));
- map.put(car2, new String("Car2"));
- System.out.println("map.size(): " + map.size());
- }
- }
Car1 hash code: 404267176
Car2 hash code: 2027651571
Car1 equals Car2: true
map.size(): 2
Car2 hash code: 2027651571
Car1 equals Car2: true
map.size(): 2
从结果可以看出来,Car1和Car2是相等的,既然二者是相等的,也就是两者作为键来说是相等的键,所以HashMap里面只能放其中一个作为键,但是实际结果中map的长度却是2个,为什么会这样呢?关键在于Car的hashCode方法,准确的说是Object的hashCode方法,Object的hashCode方法默认情况下返回的是对象内存地址,因为内存地址是唯一的。
我们没有重写Car的hashCode方法,所以car1的hashCode返回的值和car2的hashCode返回的值肯定不同。通过我们前面研究可知,如果是两个元素相等,那么这两个元素应该放到同一个HashMap的桶里。但是由于我们的car1和car2的hashCode不同,所以HashMap将car1和car2分别放到不同的桶子里面了,这就出问题了。相等(equals)的两个元素(car1和car2)如果hashCode返回值不同,那么这两个元素就会放到HashMap不同的区间里面。所以我们写代码的时候要保证相互equals的两个对象的哈希值必定要相等,即必须保证hashCode的返回值相等。那如何解决这个问题?我们只需要重写hashCode方法即可,代码如下:
- @Override
- public int hashCode() {
- return this.num.hashCode();
- }
Car1 hash code: 607836628
Car2 hash code: 607836628
Car1 equals Car2: true
map.size(): 1
Car2 hash code: 607836628
Car1 equals Car2: true
map.size(): 1
之前我们说了,相互equals的对象必须返回相同的哈希值,相同哈希值的对象都在一个桶里面,但是反过来,具有相同哈希值的对象(也就是在同一个桶里面的对象)不必相互equals。
总结:
1. HashMap为了提高查找的效率使用了分块查找的原理,对象的hashCode返回的哈希值进行进一步处理,这样就有规律的把不同的元素放到了不同的区块或桶中。下次查找该对象的时候,还是计算其哈希值,根据哈希值确定区块或桶,然后在这个小范围内查找元素,这样就快多了。
2. 如果重写了equals方法,那么必须重写hashCode方法,保证如果两个对象相互equals,那么二者的hashCode的返回值必定相等。
3. 如果两个对象的hashCode返回值相等,这两个对象不必是equals的。















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









