








前言:
此文翻译自TensorFlow tutorial: Sequence-to-Sequence Models
本文的尽量在做到意思正确的情况下,做到不尬翻。但第一次尝试翻译,另加上英语水平有限,难免有所出入,欢迎指正。
PS: 本人跑的实验是根据翻译的项目修改成的简易中文Chatbot
Sequence-to-Sequence模型
之前在RNN Tutorial讨论过(如果你还没有阅读,请先前往阅读之),循环神经网络(Recurrent Neural Networks, RNNs)可以进行语言的建模。这就产生了一个有趣的问题:我们是否可以在已经产生的词汇生成一些有意义的反馈呢?举个栗子,是否可以训练一个神经网络,用于英法翻译?而这已被证明是可行的。
这份tutorial将会展示如何使用端到端的方法构建并训练这种网络。从TensorFLow main repo和TensorFlow models repo把github的项目拷贝(clone)下来,然后你就按照以下方式运行你的翻译程序啦:
cd models/tutorials/rnn/translate
python translate.py --data_dir [你的数据所在目录]
过程中将会从WMT’15 Website下载英法翻译数据用于训练。数据大约有20GB,下载和准备可能需要一些时间,因此阅读这个tutorial和程序运行可以并行进行。
这个tutorial参考如下文件:
| 文件 | 文件说明 |
| tensorflow/tensorflow/python/ops/seq2seq.py | 构建seq2seq模型所需要的库 |
| models/tutorials/rnn/translate/seq2seq_model.py | 神经机器翻译seq2seq模型 |
| tensorflow/tensorflow/python/ops/data_utils.py | 用于准备翻译数据的Helper函数 |
| models/tutorials/rnn/translate/translate.py | 用于训练和解码 |
Sequence-to-sequence基础
一个初始的seq2seq模型(Cho et al.(pdf)),包括两个循环神经网络:一个处理输入的编码器和一个生成输出的解码器。基本结构如下图所示:
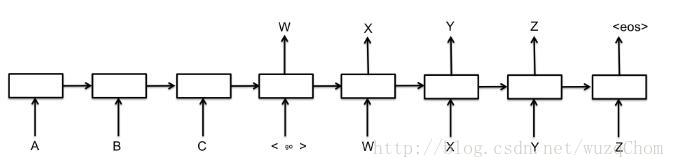
图片中的每一个方框代表RNNs中的一个单元,最常见的是GRU单元或者LSTM单元(关于这些单元的解释请看RNN Tutorial)。编码器和解码器可以共享权重或者更加常见的使用一组不同的参数。对于多层的单元也已经成功应用在了seq2seq模型当中,如用于翻译(Sutskever et al., 2014(pdf))
在以上描述的基础模型中,每一个输入(译者注:所有的输入更加合适?)都被编码成一个固定的状态向量,而这个状态向量是传如解码器的唯一参数。为了让编码器更加直接地对输入进行编码,就引入了注意力机制(attention mechanism)(Bahdanau et al., 2014(pdf))。这里我们并不会介绍注意力机制的细节(详见论文);只说一点:注意力机制可以使解码器在每一个解码的步骤都可以查看输入。在解码器当中使用了注意力机制的多层LSTM单元的seq2seq网络看起来是这样滴:
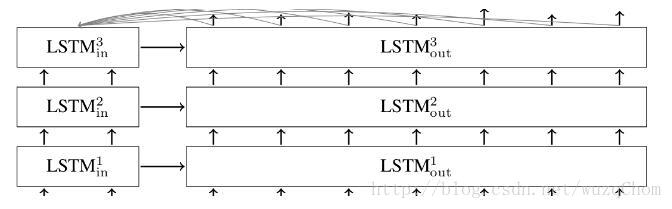
译者注:个人认为还是上述论文的图可能更好理解一点
TensorFlow seq2seq的库
如前所述,有许多不同的seq2seq模型。每一个seq2seq模型都可以使用不同的RNN单元,但是它们都接收编码器的输入和解码器的输入。这就产生了TensorFLow seq2seq库中的一个接口(tensorflow/tensorflow/python/ops/seq2seq.py)。最基础带编码器-解码器的seq2seq模型可以按照以下方式使用:
outputs, states = basic_rnn_seq2seq(encoder_inputs, decoder_inputs, cell)
在上面的函数中,“encoder_inputs”代表输入到编码器的一系列的张量,即第一张图中的A, B, C。同理,“decoder_inputs”代表了输入到解码器的张量,即图一中的GO, W, X, Y, Z。
参数“cell”是tf.contrib.rnn.RNNCell类中的一个实例,其决定模型内部将使用哪一种RNN单元。你可以使用诸如GRU单元或者LSTM单元这类已经存在的单元,也可以手动实现。还有,tf.contrib.rnn提供了提供了封装器去构造多层单元,在输入和输入添加dropout或者做其它的一些变化。例子详见RNN Tutorial。
在许多的seq2seq模型的应用当中,解码器在时刻t的输出会成为解码器t+1时刻的输入。在测试阶段,当解码一个序列的时候,解码器就是以这种方法构建的。而在训练阶段,常见的做法是:即使是之间已经有错的情况下,在每一个时刻都提供正确的输入。seq2seq.py中的函数通过使用feed_previous参数都可以实现这两种模型。第二个栗子,来看看embedding RNN模型的用法:
outputs, states = embedding_rnn_seq2seq(
encoder_inputs, decoder_inputs, cell,
num_encoder_symbols, num_decoder_symbols,
embedding_size, output_projection=None,
feed_previous=False)
在embedding_rnn_seq2seq 的模型当中,所有的输入(包括encoder_inputs 和decoder_inputs)都代表了整数个离散值张量。它们将会被嵌入成稠密的表示(关于embeddings的更多细节请见:Vectors Representations Tutoral)。但是为了构建这样的embeddings我们需要指定会出现的离散符号的最大值:在编码器一端的num_encoder_symbols和解码器一端的 num_decoder_symbols
在上面的例子中,我们将feed_previous 设置为False。这意味着解码器将会使用所提供的decoder_inputs 张量。如果我们将decoder_inputs 设置为True的话,解码器仅仅会使用decoder_inputs 的第一个元素作为输入。所有其它的张量都会被忽略,取而代之的是decoder的前一个输出将会被使用。我们的翻译模型就是使用这种方式,但是在训练阶段,也可以使用这种方式来使得模型对于自己犯的错误更加的鲁棒,和Bengio et al., 2015(pdf)类似。
在上面的例子中使用的一个更加重要的参数是output_projection。如果没有指定,embedding 模型的输出的形状为batch_size x num_decoder_symbols ,其代表了每一个生成符号的logits。当训练模型的输出词典很大的时候,也即num_decoder_symbols 很大的时候,那么存储如此大的张量是不可行的。相反,若转换成更小的输出张量就更好,稍后将会使用output_projection将输出做投影。这使得我们的seq2seq模型可以使用采样的softmax损失(Jean et al., 2014(pdf))
除了basic_rnn_seq2seq 和embedding_rnn_seq2seq 之外,在seq2seq.py中还有一些seq2seq的模型;去那里看看吧。它们的接口都很相似,所以这里并不会详细介绍。在接下来的内容中,我们使用
embedding_attention_seq2seq 来实现翻译模型。
神经翻译模型
虽然seq2seq模型的核心是由tensorflow/tensorflow/python/ops/seq2seq.py 里面的函数构造的,但是在models/tutorials/rnn/translate/seq2seq_model.py中的有一些技巧还是值得分享的(ps:现在的tensorflow好像没有这个函数了,我是把这个文件直接放到项目里面了)。
Sampled softmax 和 output projection
对于前者,上面已经提到过,我们在处理输出词汇表巨大的时候会使用sampled softmax。为了可以正常解码,我们需要同时使用输出映射。这个两者都在seq2seq_model.py中的以下代码实现:
关于sampled softmax的更多内容,传送门:sampled softmax
if num_samples > 0 and num_samples < self.target_vocab_size:
w_t = tf.get_variable("proj_w", [self.target_vocab_size, size], dtype=dtype)
w = tf.transpose(w_t)
b = tf.get_variable("proj_b", [self.target_vocab_size], dtype=dtype)
output_projection = (w, b)
def sampled_loss(labels, inputs):
labels = tf.reshape(labels, [-1, 1])
# We need to compute the sampled_softmax_loss using 32bit floats to
# avoid numerical instabilities.
local_w_t = tf.cast(w_t, tf.float32)
local_b = tf.cast(b, tf.float32)
local_inputs = tf.cast(inputs, tf.float32)
return tf.cast(
tf.nn.sampled_softmax_loss(
weights=local_w_t,
biases=local_b,
labels=labels,
inputs=local_inputs,
num_sampled=num_samples,
num_classes=self.target_vocab_size),
dtype)
首先,需要注意的是我们仅仅会在采样的数量(默认为512个)比目标输出词表更小的时候才会使用sampled softmax。对于那些输出词表小于512的情况,也许使用标准的softmax损失会更好。
其次,我们构建一个输出映射。它是一个包含了权重矩阵和偏置向量的元组对。如果使用的话,rnn的单元将会返回形状为batch_size x size的向量,而不是batch_size x target_vocab_size. 为了覆盖logits,我们需要乘上权重矩阵并且加上偏置,如seq2seq_model.py文件中124-126行所示:
if output_projection is not None:
for b in xrange(len(buckets)):
self.outputs[b] = [tf.matmul(output, output_projection[0]) +
output_projection[1] for ...]
装桶(Bucketing)和填充(padding)
除了sampled softmax,我们的翻译模型也是用了装桶(bucketing)和填充(padding),这两种方法是用于高效地处理不同长度句子的情况。我们首先来弄清楚是怎么一回事。当我们从英语翻译成法语的时候,假设我们的输入英语的长度为L1,输出法语的长度为L2。因为英语句子是作为encoder_inputs而传入的,法语句子作为decoder_inputs而传入(最开始加了一个GO前缀),原则上对于每一个长度为(L1,L2+1)的语句对,都要创建一个seq2seq的模型。这将导致一个巨大的计算图,而这个图由许多十分相似的子图构成。还有,因为我们只能使用一个特殊的PAD符号来填充每一个句子。对于已经填充的长度,我们只需要一个seq2seq模型。但是对于较短的句子的话,由于我们需要编码和加码很多没有意义的PAD字符,我们的模型将会变得十分低效。
作为折衷,我们使用一定数量的桶(buckets)并且把每一个句子桶填充至桶的长度。在 translate.py中,我们使用默认的桶如下:
buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]这意味着如果我们的英文句子有3个字符,对应法语的输出有6个字符,那么我们将会把这个句子放入第一个桶,并且将输入和输出分别填充到5和10个字符。如果输入输出的长度分别为8和18,不会用(10,15),而是使用(20,25)的桶,同样滴,输入和输出将会分别填充到20和25个字符。
记住当我们构建解码器的输入的时候,我们在输入数据之前加了一个特殊的 GO 字符。这个操作是在 seq2seq_model.py中的 get_batch()完成的,这个函数也将输入逆序(译者注:即本来从左到右,变成从右到左。对于这里,个人认为可能是因为rnn的性质,后面的序列保留的有效信息会更多而决定的,不一定正确)。在Sutskever et al., 2014中,展示了将输入逆序可以提升神经机器翻译的效果。把这些串起来,假设我们有一个句子”I go.”为输入,输出为“Je vais.” 。符号化成[“I”,”go”,”.”]和[“Je”,”vais”,”.”]分别作为输入和输出。他将会放入(5,10)的桶,然后填充并且将输入逆序之后,编码其的输入为[PAD PAD “.” “go” “I”],解码器的输入为[GO “Je” “vais” “.” EOS PAD PAD PAD PAD PAD]。
待续。。。
说明:由于csdn在线保存功能用户体验并不好,为了保存博文的内容,所以部分内容就先发表了。如造成读者不良阅读体验,敬请谅解。















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









