







大家在调用pickle模块的时候应该有遇到这个问题,当你多次pickle.dump 对象,写入到文件中,然后再pickle.load的时候,却只会load出来一个第一个数据,有木有?
eg:
测试pickle模块的时候发现dump进去数据可说倒不出来。。。
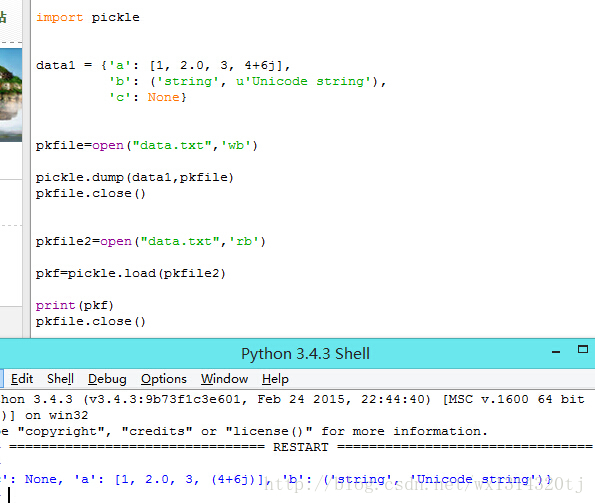
但你发现这个文件数据变大了,肯定是吃进去了。那我们用winhex瞅瞅:
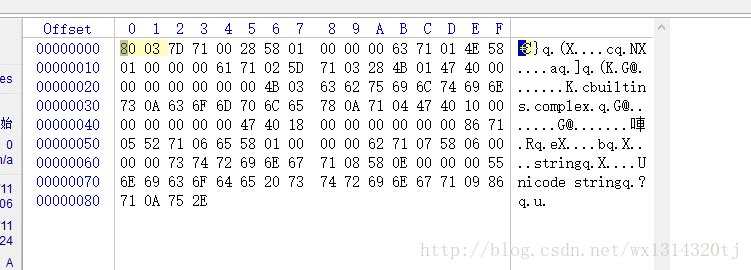
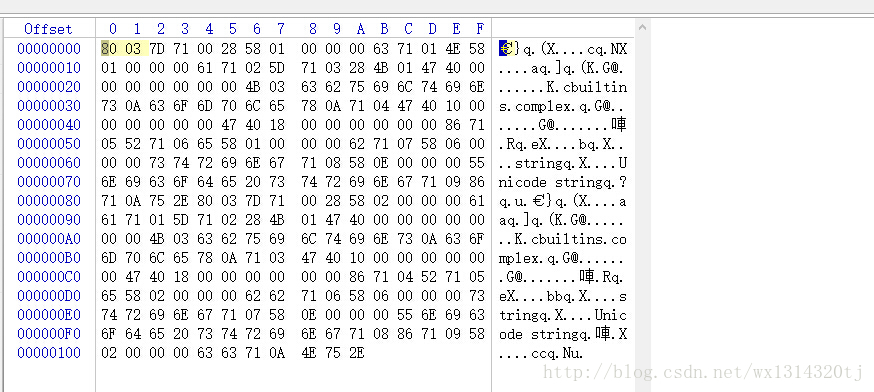
肚子都大了,咋生不出来呢?
solution:
import os
import piskle
pkfile=open("D:\\testfile.txt",'ab')
pickle.dump(data1,pkfile)
pickle.dump(data2,pkfile)
pkfile.close() 和下面这两个load结果是不是一样?
pkfile=open("testfile.txt",'ab')
pickle.dump(data1,pkfile)
pkfile.close() load出来的结果是一样的,但文件testfile.txt的大小确实不同 而且扔到winhex里也确实内容有变多可能我们都是习惯把数据修改好再重新dump覆盖掉之前的,可是如果真的需要追回并且一定要load出来改怎么办呢 ?
其实很简单, 我们正常dump一次 所以load一次就好了 这里我dump了两次 是不是要load两次才能把数据读出来呢。。。。果断试了下,代码:
import os
import pickle
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
data2 = {'aa': [1, 2.0, 3, 4+6j],
'bb': ('string', u'Unicode string'),
'cc': None}
pkfile=open("testfile.txt",'ab')
pickle.dump(data1,pkfile)
pickle.dump(data2,pkfile)
pkfile.close()
pkfile2=open("testfile.txt",'rb')
pkf=pickle.load(pkfile2)
pkf1=pickle.load(pkfile2)
print(pkf)
print(pkf1)load2次,结果如下:

所以解决方法如下:
Pickle 每次序列化生成的字符串有独立头尾,pickle.load() 只会读取一个完整的结果,所以你只需要在 load 一次之后再 load 一次,就能读到第二次序列化的 [‘asd’, (‘ss’, ‘dd’)]。如果不知道文件里有多少 pickle 对象,可以在 while 循环中反复 load 文件对象,直到抛出异常为止。
使用try … except语句即可。














 9335
9335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









