







大家好,非常高兴能在这里给大家分享,感谢InfoQ提供的这个微信的平台,首先简单自我介绍一下,我叫曾勇,是Elastic的工程师。
Elastic将在今年秋季的时候发布一个Elasticsearch V5.0的大版本,这次的微信分享将给大家介绍一下5.0版里面的一些新的特性和改进。
5.0? 天啦噜,你是不是觉得版本跳的太快了。
好吧,先来说说背后的原因吧。

相信大家都听说ELK吧,是Elasticsearch、Logstash、Kibana三个产品的首字母缩写,现在Elastic又新增了一个新的开源项目成员:Beats,

有人建议以后这么叫:ELKB?为了未来更好的扩展性:) ELKBS?ELKBSU?…..所以我们打算将产品线命名为ElasticStack,同时由于现在的版本比较混乱,每个产品的版本号都不一样,Elasticsearch和Logstash目前是2.3.4;Kibana是4.5.3;Beats是1.2.3;

版本号太乱了有没有,什么版本的ES用什么版本的Kibana?有没有兼容性问题?
所以我们打算将这些的产品版本号也统一一下,即v5.0,为什么是5.0,因为Kibana都4.x了,下个版本就只能是5.0了,其他产品就跟着跳跃一把,第一个5.0正式版将在今年的秋季发布,目前最新的测试版本是:5.0 Alpha 4
上面就是整个ElasticStack了,其实还是之前的那些啦
目前各团队正在紧张的开发测试中,每天都有新的功能和改进,本次分享主要介绍一下Elasticsearch的主要变化。
首先来看看5.0里面都引入了哪些新的功能吧。
首先看看跟性能有关的,第一个就是Lucene 6.x 的支持,
Elasticsearch5.0率先集成了Lucene6版本,其中最重要的特性就是 Dimensional Point Fields,多维浮点字段,ES里面相关的字段如date, numeric,ip 和 Geospatial 都将大大提升性能,这么说吧,磁盘空间少一半;索引时间少一半;查询性能提升25%;IPV6也支持了。
为什么快,底层使用的是Block k-d trees,核心思想是将数字类型编码成定长的字节数组,对定长的字节数组内容进行编码排序,然后来构建二叉树,然后依次递归构建,目前底层支持8个维度和最多每个维度16个字节,基本满足大部分场景。
说了这么多,看图比较直接
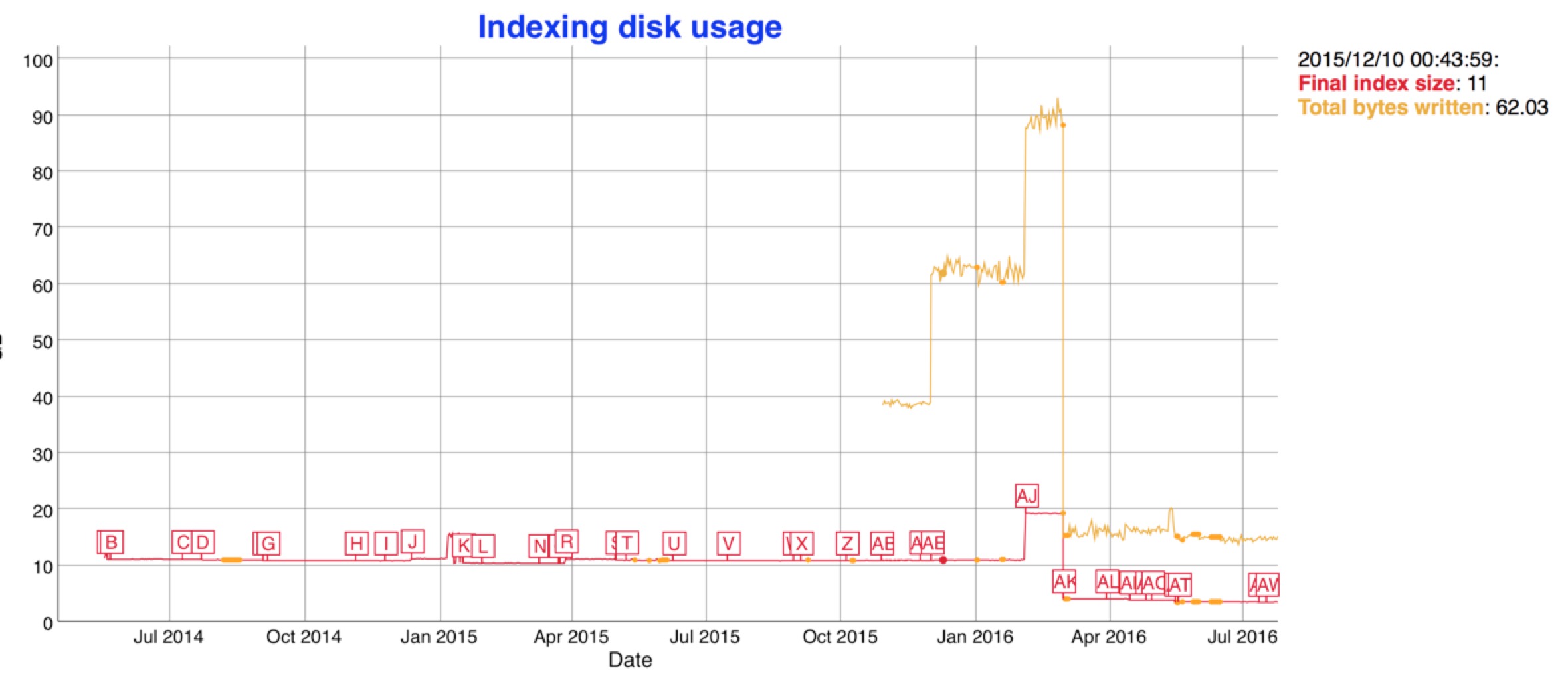
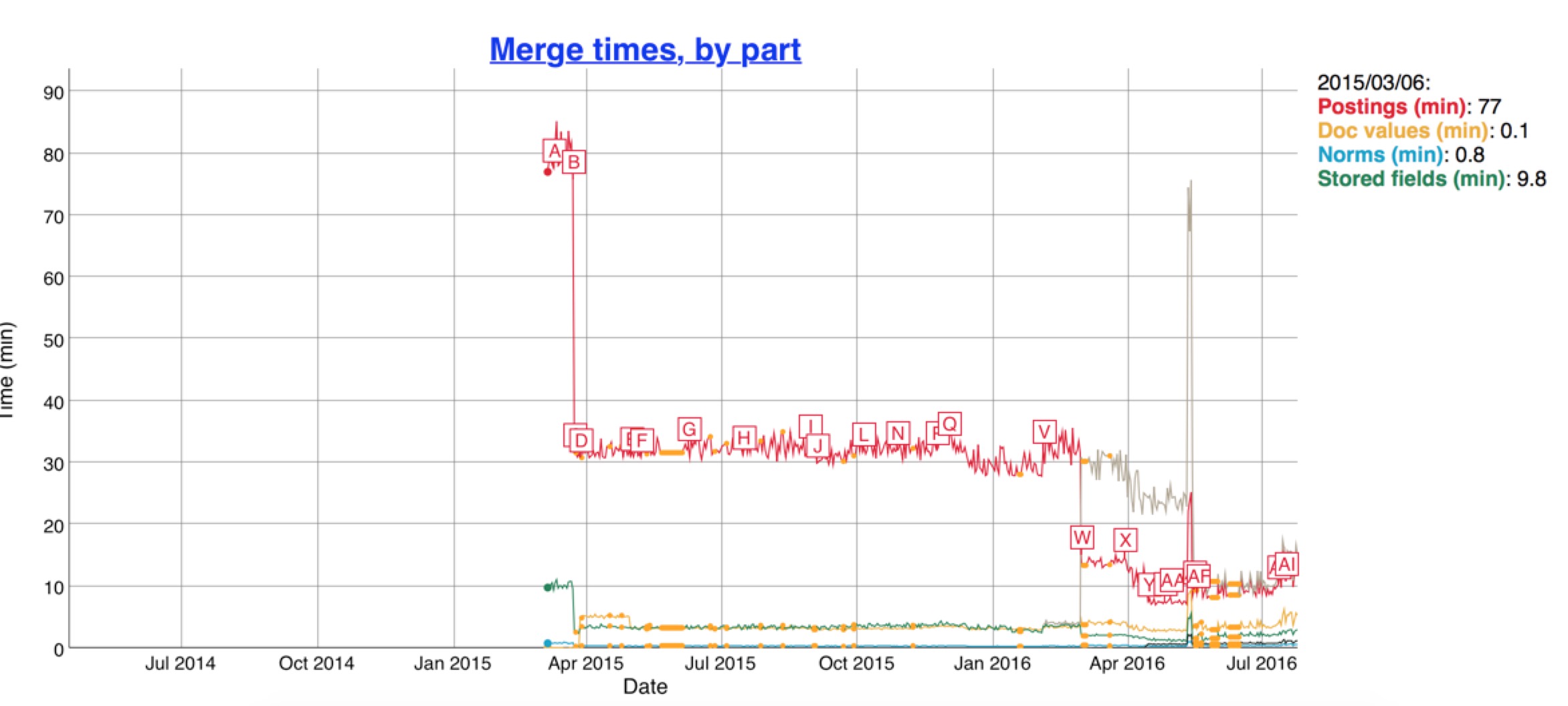
图中从2015/10/32 total bytes飙升是因为es启用了docvalues,我们关注红线,最近的引入新的数据结构之后,红色的索引大小只有原来的一半大小。索引小了之后,merge的时间也响应的减少了,看下图
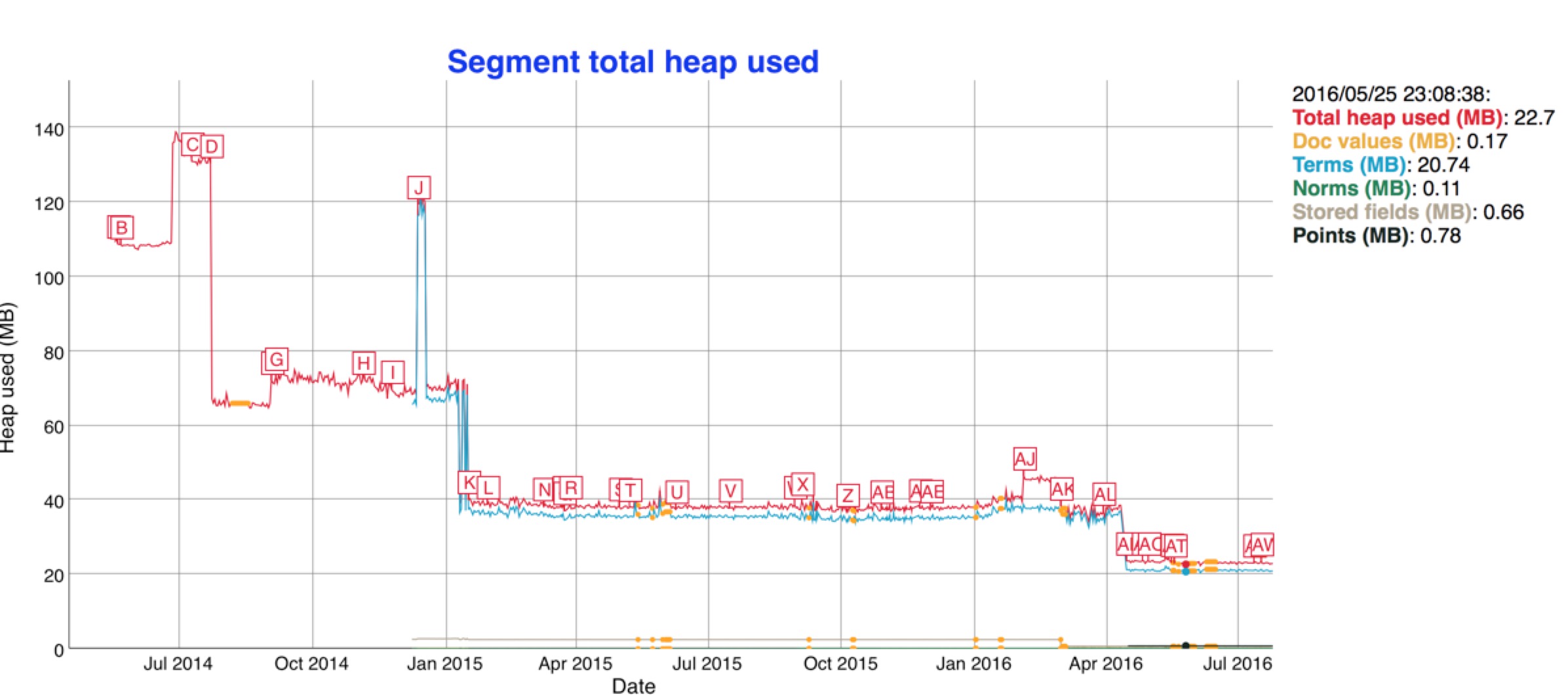
相应的Java堆内存占用只原来的一半:
再看看索引的性能,也是飙升
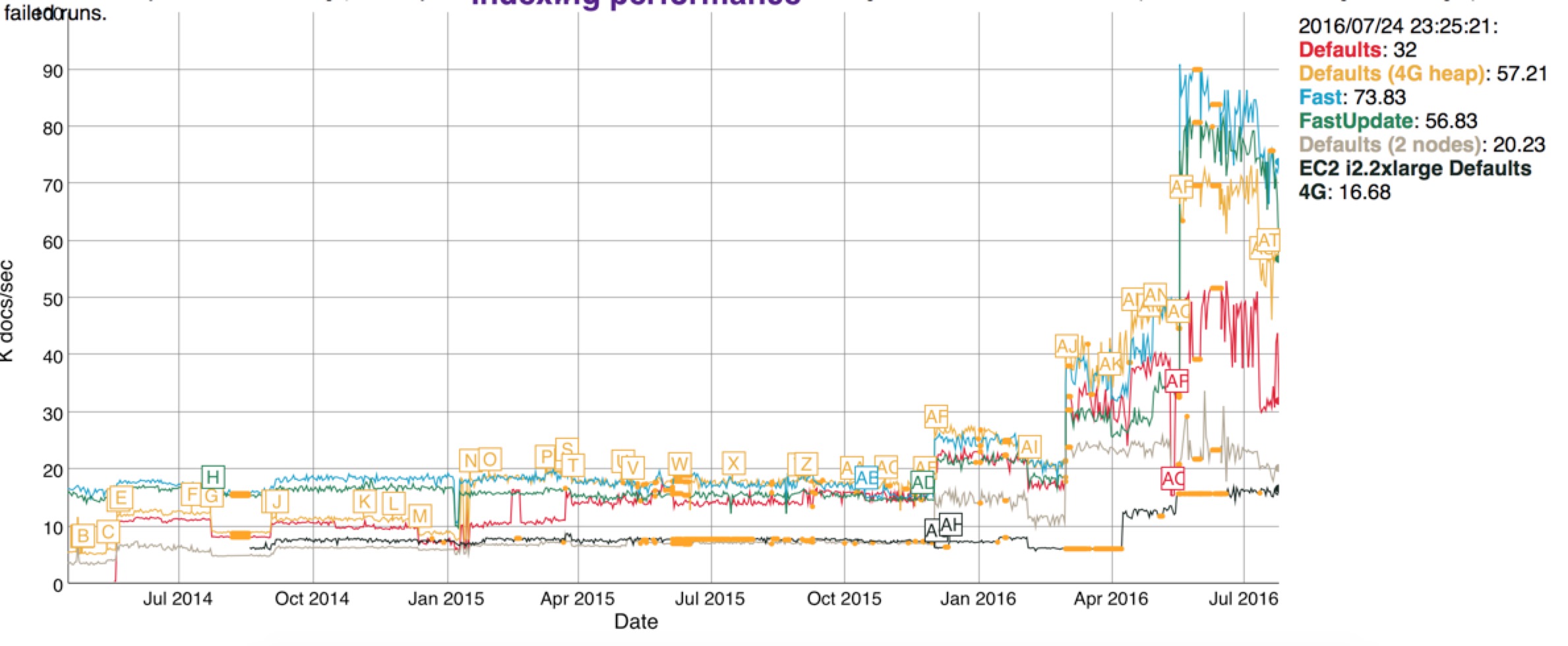
当然Lucene6里面还有很多优化和改进,这里没有一一列举。我们再看看索引性能方面的其他优化
ES5.0在Internal engine级别移除了用于避免同一文档并发更新的竞争锁,带来15%-20%的性能提升 #18060
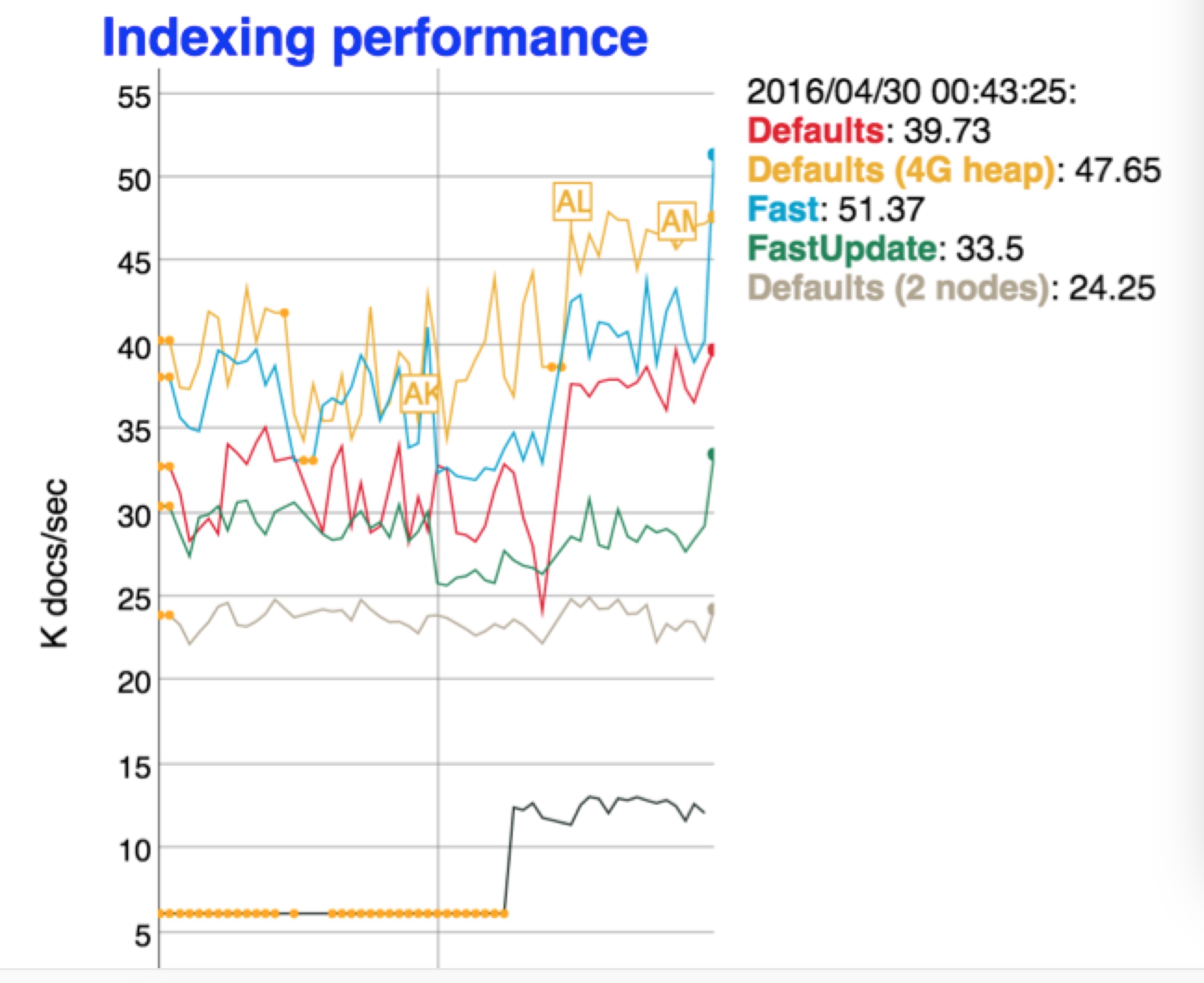
以上截图来自ES的每日持续性能监控:https://benchmarks.elastic.co/index.html
另一个和aggregation的改进也是非常大,Instant Aggregations
Elasticsearch已经在Shard层面提供了Aggregation缓存,如果你的数据没有变化,ES能够直接返回上次的缓存结果,但是有一个场景比较特殊,就是 date histogram,大家kibana上面的条件是不是经常设置的相对时间,如:from:now-30d to:now,好吧,now是一个变量,每时每刻都在变,所以query条件一直在变,缓存也就是没有利用起来,经过一年时间大量的重构,现在可以做到对查询做到灵活的重写,首先now关键字最终会被重写成具体的值,其次,每个shard会根据自己的数据的范围来重写查询为 match_all或者是match_none查询,所以现在的查询能够被有效的缓存,并且只有个别数据有变化的Shard才需要重新计算,大大提升查询速度。
另外再看看和Scroll相关的吧,现在新增了一个:Sliced Scroll
用过Scroll接口吧,很慢?如果你数据量很大,用Scroll遍历数据那确实是接受不了,现在Scroll接口可以并发来进行数据遍历了,
每个Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,利用Scroll重建或者遍历要快很多倍。
看看这个demo

可以看到两个scroll请求,id分别是0和1,max是最大可支持的并行任务,可以各自独立进行数据的遍历获取。
我们再看看es在查询优化这块做的工作,
新增
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









