









一、数据存储模型
create table的with子句用于设置表的存储选项。例如:
db1=# create table t1 (a int) with
db1-# (appendonly=true,
db1(# blocksize=8192,
db1(# orientation=row,
db1(# compresstype=zlib,
db1(# compresslevel=1,
db1(# fillfactor=50,
db1(# oids=false);
CREATE TABLEdb1=# create table sales
db1-# (id int, year int, month int, day int,region text)
db1-# distributed by (id)
db1-# partition by range (year)
db1-# subpartition by range (month)
db1-# subpartition template (
db1(# start (1) end (13) every (1),
db1(# default subpartition other_months )
db1-# subpartition by list (region)
db1-# subpartition template (
db1(# subpartition usa values ('usa') with
db1(# (appendonly=true,
db1(# blocksize=8192,
db1(# orientation=row,
db1(# compresstype=zlib,
db1(# compresslevel=1,
db1(# fillfactor=50,
db1(# oids=false),
db1(# subpartition europe values ('europe'),
db1(# subpartition asia values ('asia'),
db1(# default subpartition other_regions)
db1-# ( start (2002) end (2010) every (1),
db1(# default partition outlying_years);
...
CREATE TABLE1. APPENDONLY
因为HDFS上文件中的数据只能追加,不允许修改或删除,所以该选项只能设置为TRUE,设置为FALSE会报错:
db1=# create table t1(a int) with (appendonly=true);
CREATE TABLE
db1=# create table t2(a int) with (appendonly=false);
ERROR: tablespace "dfs_default" does not support heap relation2. BLOCKSIZE
设置表中每个数据块的字节数,值在8192到2097152之间,而且必须是8192的倍数,缺省值为32768。该属性必须与appendonly=true一起使用,并且只支持行存储模型:
db1=# create table t1(a int) with (blocksize=8192);
ERROR: invalid option 'blocksize' for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (appendonly=true,blocksize=8192);
CREATE TABLE
db1=# create table t2(a int) with (appendonly=true,blocksize=8192,orientation=parquet);
ERROR: invalid option 'blocksize' for parquet table
db1=# create table t2(a int) with (appendonly=true,blocksize=8192,orientation=row);
CREATE TABLE3. bucketnum
设置一个哈希分布表使用的哈希桶数,有效值为大于0的整数,而且不要大于default_hash_table_bucket_number配置参数。缺省值为segment节点数 * 6。推荐在创建哈希分布表时显式指定该值。该属性在建表时指定,表创建以后不能修改bucketnum的值。
db1=# create table t1(a int) with (bucketnum=1) distributed by (a);
CREATE TABLE4. ORIENTATION
该参数设置数据存储模型,有效值为row(缺省值)和parquet,分别指的是面向行和列的存储格式。此选项只能与appendonly=true一起使用。
db1=# create table t1(a int) with (orientation=parquet);
ERROR: invalid option "orientation" for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (orientation=parquet,appendonly=true);
CREATE TABLEdb1=# create table t1(a int) with (orientation=column,appendonly=true);
ERROR: Column oriented tables are deprecated. Not support it any more.5. COMPRESSTYPE
该属性指定使用的压缩算法,有效值为ZLIB、SNAPPY或GZIP。缺省值ZLIB的压缩率更高但速度更慢。Parquet表仅支持SNAPPY和GZIP。该选项只能与appendonly=true一起使用。
db1=# create table t1(a int) with (compresstype=zlib);
ERROR: invalid option 'compresstype' for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (compresstype=zlib,appendonly=true);
CREATE TABLE
db1=# create table t2(a int) with (compresstype=zlib,appendonly=true,orientation=parquet);
ERROR: parquet table doesn't support compress type: 'zlib'
db1=# create table t2(a int) with (compresstype=snappy,appendonly=true,orientation=parquet);
CREATE TABLE6. COMPRESSLEVEL
有效值1-9,数值越大压缩率越高。如果不指定,缺省值为1 。该选项只对zlib和gzip有效,并且只能与appendonly=true一起使用。
db1=# create table t1(a int) with (compresstype=snappy,compresslevel=1);
ERROR: invalid option 'compresslevel' for compresstype 'snappy'.
db1=# create table t1(a int) with (compresslevel=1);
ERROR: invalid option 'compresslevel' for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (compresslevel=1,appendonly=true);
CREATE TABLE7. OIDS
缺省值为FALSE,表示不给行赋予对象标识符。建表时不要启用OIDS。首先,通常OIDS对用户应用没有用处。再者,行典型的HAWQ系统中的表都很大,如果为每行赋予一个32位的计数器,不但占用空间,而且可能给HAWQ系统的目录表造成问题。最后,每行节省4字节存储空间也能带来一定的查询性能提升。
8. FILLFACTOR
该选项控制插入数据时页存储空间的使用率,作用类似于Oracle的PCTFREE,为后续的行更新预留空间。取值范围是10到100,缺省值为100,即不为更新保留空间。HAWQ不支持UPDATE和DELETE操作,故该值保持缺省即可。该选项对parquet表无效。
db1=# create table t1(a int) with (fillfactor=100,orientation=parquet);
ERROR: invalid option "orientation" for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (fillfactor=100);
CREATE TABLE9. PAGESIZE与ROWGROUPSIZE
ROWGROUPSIZE:描述Parquet文件中row group的大小,可配置范围为 [1KB,1GB) 默认为8MB。
PAGESIZE:描述parquet文件中每一列对应的page大小,可配置范围为[1KB,1GB),默认为1MB。
这两个选项只对parquet表有效,并且只能与appendonly=true一起使用。PAGESIZE的值应该小于ROWGROUPSIZE,因为行组包含页的元信息。
db1=# create table t1(a int) with (pagesize=1024,rowgroupsize=1024,orientation=parquet);
ERROR: row group size for parquet table must be larger than pagesize. Got rowgroupsize: 1024, pagesize 1024
db1=# create table t1(a int) with (pagesize=1024,rowgroupsize=8096,orientation=parquet);
ERROR: invalid option "orientation" for base relation. Only valid for Append Only relations
db1=# create table t1(a int) with (pagesize=1024,rowgroupsize=8096,orientation=row);
ERROR: invalid option 'pagesize' for non-parquet table
db1=# create table t1(a int) with (pagesize=1024,rowgroupsize=8096,orientation=parquet,appendonly=true);
CREATE TABLE二、数据分布策略
首先需要指出的是,这里所说的数据分布策略并不直接决定数据的物理存储位置,数据块的存储位置是由HDFS决定的。这里的数据分布策略概念是从GreenPlum继承来的,存储移植到HDFS上后,数据分布决定了HDFS上数据文件的生成规则,以及在此基础上的资源分配策略。
所有的HAWQ表(除gpfdist外部表)都是分布存储在HDFS上的。HAWQ支持两种数据分布策略,随机与哈希。在创建表时,DISTRIBUTED子句声明HAWQ的数据分布策略。如果没有指定DISTRIBUTED子句,则HAWQ缺省使用随机分布策略。当使用哈希分布时,bucketnum属性设置哈希桶的数量。几何数据类型(Geometric Types)或用户定义数据类型的列不能作为HAWQ的哈希分布键列。哈希桶数影响处理查询时使用的虚拟段的数量。
缺省时,哈希分布表使用的哈希桶数由default_hash_table_bucket_number服务器配置参数的值所指定。可以在会话级或使用建表DDL语句中的bucketnum存储参数覆盖缺省值。
随机分布相对于哈希分布有一些益处。例如,集群扩容后,HAWQ的弹性查询特性,使得在操作随机分布表时能够自动使用更多的资源,而不需要重新分布数据。重新分布大表数据的资源与时间消耗都非常大。而且,随机分布表具有更好的数据本地化,这尤其表现在底层的HDFS因为某个数据节点失效而执行rebalance操作重新分布数据后。在一个大规模Hadoop集群中,增删数据节点后rebalance的情况很常见。
然而,哈希分布表可能比随机分布表快。在HAWQ的TPCH测试中,哈希分布表在很多查询上具有更好的性能。图1是HAWQ提供的一个数据分布性能对比图,其中CO表示列存储格式,AO表示行存储格式。
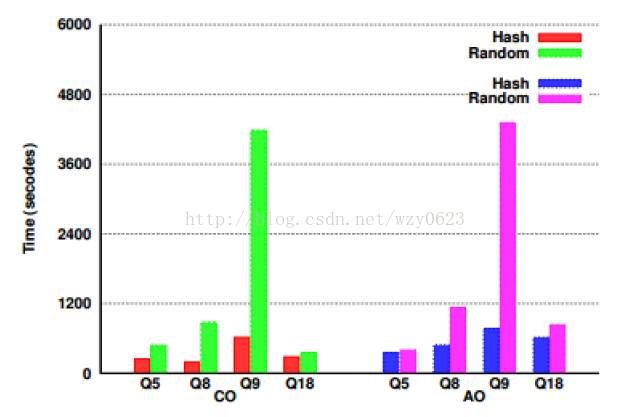
HAWQ的文档中并没有说明具体的测试环境,比如数据量和segment节点数是多少,CPU或内存等资源情况,default_hash_table_bucket_number、hawq_rm_nvseg_perquery_perseg_limit、hawq_rm_nvseg_perquery_limit等参数设置的是多少,具体查询语句是什么等等,因此这个测试的结果也许并不能适用于普遍情况。
HAWQ的运行时弹性查询是以虚拟段为基础的,而虚拟段是基于查询成本按需分配的。每个节点使用一个物理段和一组动态分配的虚拟段。通常,为查询分配的虚拟段越多,查询执行的越快。可以通过设置default_hash_table_bucket_number和hawq_rm_nvseg_perquery_limit参数,控制一个查询使用的虚拟段的数量,从而调整性能。但是必须要知道如果default_hash_table_bucket_number的值改变了,哈希分布表的数据必须重新分布,这可能是一步成本很高的操作。因此,如果需要大量的虚拟段,最好在建表前预先设置好default_hash_table_bucket_number。在集群扩容后,可能需要调整default_hash_table_bucket_number的值。但要注意,该值不要超过hawq_rm_nvseg_perquery_limit参数的值。
表1是HAWQ给出的segment节点数量与default_hash_table_bucket_number值的对应关系。不推荐将该参数改为大于1000的值。
节点数 | default_hash_table_bucket_number |
<= 85 | 6 * #nodes |
> 85 and <= 102 | 5 * #nodes |
> 102 and <= 128 | 4 * #nodes |
> 128 and <= 170 | 3 * #nodes |
> 170 and <= 256 | 2 * #nodes |
> 256 and <= 512 | 1 * #nodes |
> 512 | 512 |
2. 选择数据分布策略
在选择分布策略时,应该考虑具体数据和查询的情况,包括以下几点:- 平均分布数据。为了达到最好的性能,所有segment应该包含相似数量的数据。如果数据不平衡或存在“尖峰”,拥有更多数据的segment的工作负载会比其它segment高 很多。
- 本地和分布式操作。本地操作比分布式操作更快。如果查询中有连接、排序或聚合操作,如果能够在一个segment上完成,那么本地处理查询是最快的。当多个表共享一个公共的哈希分布键,该列上的连接或排序操作是在本地进行的。对于随机分布策略,是否本地连接是不可控的。
- 平均处理查询。为了获得更好的性能,所有segment应该处理等量的查询工作。如果表的数据分布策略和查询条件谓词匹配的不好,查询负载可能成为“尖峰”。例如,假设有一个销售事务表,以公司名称列作为分布键分布数据。如果查询中的一个谓词引用了单一的分布键,则查询可能只在一个segment上进行处理。而如果查询谓词通常以公司名称外的其它条件选择数据,可能所有segment共同处理查询。
- 随机分布表的大小。
- 哈希分布表的CREATE TABLE DDL中指定的bucketnum存储参数。
- 数据本地化情况。
- default_hash_table_bucket_number
- hawq_rm_nvseg_perquery_limit
对于任何一个特定的查询,前四个因素已经是固定值,只有最后一个配置参数hawq_rm_nvseg_perquery_limit可以被用于调整查询执行的性能。hawq_rm_nvseg_perquery_limit指定集群范围内,一个查询语句在执行时可用的最大虚拟段数量,缺省值为512,取值范围是1到65535。
除hawq_rm_nvseg_perquery_limit参数外,hawq_rm_nvseg_perquery_perseg_limit也控制执行一个查询使用的虚拟段数量。该参数指示一个HAWQ的segment在执行一个查询时可以使用的最大虚拟段数,缺省值为6,取值范围是1到65535。它影响随机分布表、外部表和用户定义表,但不影响哈希分布表。减小hawq_rm_nvseg_perquery_perseg_limit的值可能提高并发性,增加它的值可能提升一个查询执行的并行度。对于某些查询,如果达到硬件的限制,提升并行度并不会提高性能,况且数据仓库应用的并发量通常也不会很高。因此,在绝大多数部署环境中,不应该修改此参数的缺省值。
修改服务器配置参数最简便的方法,是使用Ambari的Web界面交互式设置,如图2所示。大多数情况下,HAWQ的运行时弹性查询将动态分配虚拟段以优化性能,因此通常不需要对相关参数做进一步的调优。
下面用一个例子说明两种数据分布策略。建立三个表,t1使用单列哈希分布,t2使用随机分布,t3使用多列哈希分布。
db1=# create table t1 (a int) distributed by (a);
CREATE TABLE
db1=# create table t2 (a int) distributed randomly;
CREATE TABLE
db1=# create table t3 (a int,b int,c int) distributed by (b,c);
CREATE TABLEdb1=# select c.relname, sub.attname
db1-# from pg_namespace n
db1-# join pg_class c on n.oid = c.relnamespace
db1-# left join (select p.attrelid, p.attname
db1(# from pg_attribute p
db1(# join (select localoid, unnest(attrnums) as attnum
db1(# from gp_distribution_policy) as g on g.localoid = p.attrelid
db1(# and g.attnum = p.attnum) as sub on c.oid = sub.attrelid
db1-# where n.nspname = 'public'
db1-# and c.relname in ('t1', 't2', 't3')
db1-# and c.relkind = 'r';
relname | attname
---------+---------
t1 | a
t2 |
t3 | c
t3 | b
(4 rows)db1=# select c.relname, d.dat2tablespace tablespace_id, d.oid database_id, c.relfilenode table_id
db1-# from pg_database d, pg_class c, pg_namespace n
db1-# where c.relnamespace = n.oid
db1-# and d.datname = current_database()
db1-# and n.nspname = 'public'
db1-# and c.relname in ('t1', 't2');
relname | tablespace_id | database_id | table_id
---------+---------------+-------------+----------
t1 | 16385 | 25270 | 156897
t2 | 16385 | 25270 | 156902
(2 rows)
[gpadmin@hdp3 ~]$ hdfs dfs -ls /hawq_data/16385/25270/156897
[gpadmin@hdp3 ~]$ hdfs dfs -ls /hawq_data/16385/25270/156902
[gpadmin@hdp3 ~]$ db1=# insert into t1 values (1),(2),(3);
INSERT 0 3
db1=# insert into t2 values (1),(2),(3);
INSERT 0 3
[gpadmin@hdp3 ~]$ hdfs dfs -ls /hawq_data/16385/25270/156897
Found 24 items
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/1
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/10
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/11
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/12
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/13
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/14
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/15
-rw------- 3 gpadmin gpadmin 16 2017-04-01 14:40 /hawq_data/16385/25270/156897/16
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/17
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/18
-rw------- 3 gpadmin gpadmin 16 2017-04-01 14:40 /hawq_data/16385/25270/156897/19
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/2
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/20
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/21
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/22
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/23
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/24
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/3
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/4
-rw------- 3 gpadmin gpadmin 16 2017-04-01 14:40 /hawq_data/16385/25270/156897/5
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/6
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/7
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/8
-rw------- 3 gpadmin gpadmin 0 2017-04-01 14:40 /hawq_data/16385/25270/156897/9
[gpadmin@hdp3 ~]$ hdfs dfs -ls /hawq_data/16385/25270/156902
Found 1 items
-rw------- 3 gpadmin gpadmin 48 2017-04-01 14:40 /hawq_data/16385/25270/156902/1
[gpadmin@hdp3 ~]$ 相对于哈希分布策略,随机分布更具有弹性。可以看到,t2表只在HDFS上创建了一个数据文件。查询t2表分配的虚拟段数量,由查询优化器在运行时决定。分配虚拟段数与表的数据量有关,对于小表的查询可能只分配一个虚拟段,而大表可能每个主机分配6个虚拟段。集群扩展时,不需要重新分布数据,如果需要数据库会自动增加查询一个随机分布表总的虚拟段数量。
HAWQ推荐使用随机分布,这也是缺省的分布策略,原因如下:
- 适合HDFS。NameNode只需要跟踪更少的文件。
- 更具弹性。集群增减节点时,不需要重新分配数据。
- 可以通过增加hawq_rm_nvseg_perquery_perseg_limit的值提高查询并行性。
- 优化器可以根据查询的需求动态分配虚拟段数量。
3. 数据分布用法
数据分布的原理虽然复杂,但DISTRIBUTED子句的语法却很简单,DISTRIBUTED BY (<column>, [ … ] )用来声明一列或多列,作为哈希分布表的分布键。DISTRIBUTED RANDOMLY显式指定表使用随机分布策略。
db1=# create table t1(id int) with (bucketnum=8) distributed by (id);
CREATE TABLE
db1=# create table t2(id int) with (bucketnum=8) distributed randomly;
CREATE TABLE
db1=# create table t3(id int) distributed randomly;
CREATE TABLEdb1=# \d t2
Append-Only Table "public.t2"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Distributed randomly
db1=# alter table t2 set distributed by (id);
ERROR: bucketnum requires a numeric value
db1=# select t1.*,t2.relname from gp_distribution_policy t1,pg_class t2
db1-# where t1.localoid=t2.oid;
localoid | bucketnum | attrnums | relname
----------+-----------+----------+---------
40651 | 8 | {1} | t1
40656 | 8 | | t2
40661 | 24 | | t3
(3 rows)db1=# create table t1 (a int);
CREATE TABLE
db1=# \d t1
Append-Only Table "public.t1"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Distributed randomly
db1=# alter table t1 set distributed by (a);
ALTER TABLE
db1=# \d t1
Append-Only Table "public.t1"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Distributed by: (a)
db1=# alter table t1 set distributed randomly;
ALTER TABLEdb1=# alter table t1 set with (reorganize=true);
ALTER TABLE这里有一个需要注意的细节,如果在建表时显式指定了bucketnum,那么不能再使用ALTER TABLE语句修改表的分布策略,也不能重新分布数据。
db1=# create table t1(a int) with (bucketnum=10) distributed by (a);
CREATE TABLE
db1=# alter table t1 set distributed by (a);
ERROR: bucketnum requires a numeric value
db1=# alter table t1 set distributed randomly;
ERROR: bucketnum requires a numeric value
db1=# alter table t1 set with (reorganize=true);
ERROR: bucketnum requires a numeric value
db1=# alter table t1 set with (bucketnum=10,reorganize=true);
ERROR: option "bucketnum" not supporteddb1=# set default_hash_table_bucket_number=10;
SET
db1=# create table t1(a int) distributed by (a);
CREATE TABLE
db1=# alter table t1 set distributed randomly;
ALTER TABLE
db1=# alter table t1 set distributed by (a);
ALTER TABLE
db1=# alter table t1 set with (reorganize=true);
ALTER TABLE三、从已有的原始表创建新表
HAWQ提供了四种从一个原始表创建新表的方法,如表2所示。
| 语法 |
INHERITS | CREATE TABLE new_table INHERITS (origintable) [WITH(bucketnum=x)] [DISTRIBUTED BY col] |
LIKE | CREATE TABLE new_table (LIKE origintable) [WITH(bucketnum=x)] [DISTRIBUTED BY col] |
AS | CREATE TABLE new_table [WITH(bucketnum=x)] AS SUBQUERY [DISTRIBUTED BY col] |
SELECT INTO | CREATE TABLE origintable [WITH(bucketnum=x)] [DISTRIBUTED BY col]; SELECT * INTO new_table FROM origintable; |
1. INHERITS
CREATE TABLE语句的INHERITS子句指定一个或多个父表,新建的表作为子表,自动继承父表的所有列。INHERITS在子表与父表之间建立了一种永久性关系。对父表结构的修改会传递到子表,缺省时,子表中新增的数据也会在包含在父表中。db1=# create table t1(a int);
CREATE TABLE
db1=# create table t2(b int);
CREATE TABLE
db1=# create table t3() inherits (t1,t2);
NOTICE: Table has parent, setting distribution columns to match parent table
CREATE TABLE
db1=# \d t3
Append-Only Table "public.t3"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
b | integer |
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Inherits: t1,
t2
Distributed randomly
db1=# alter table t1 alter a type text;
ALTER TABLE
db1=# \d t3
Append-Only Table "public.t3"
Column | Type | Modifiers
--------+---------+-----------
a | text |
b | integer |
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Inherits: t1,
t2
Distributed randomly
db1=# insert into t3 values ('a',1);
INSERT 0 1
db1=# select * from t1;
a
---
a
(1 row)
db1=# select * from t2;
b
---
1
(1 row)
db1=# drop table t1;
NOTICE: append only table t3 depends on append only table t1
ERROR: cannot drop append only table t1 because other objects depend on it
HINT: Use DROP ... CASCADE to drop the dependent objects too.
db1=# drop table t1 cascade;
NOTICE: drop cascades to append only table t3
DROP TABLE
db1=# \dt
List of relations
Schema | Name | Type | Owner | Storage
--------+------+-------+---------+-------------
public | t2 | table | gpadmin | append only
(1 row)db1=# CREATE TABLE sales (id int, date date, amt decimal(10,2)) inherits (t1)
db1-# DISTRIBUTED BY (id)
db1-# PARTITION BY RANGE (date)
db1-# ( PARTITION Jan08 START (date '2008-01-01') INCLUSIVE ,
db1(# PARTITION Feb08 START (date '2008-02-01') INCLUSIVE
db1(# END (date '2009-01-01') EXCLUSIVE );
ERROR: cannot mix inheritance with partitioningdb1=# create table t1(a int);
CREATE TABLE
db1=# create table t2(a smallint);
CREATE TABLE
db1=# create table t3 () inherits (t1,t2);
NOTICE: Table has parent, setting distribution columns to match parent table
NOTICE: merging multiple inherited definitions of column "a"
ERROR: inherited column "a" has a type conflict
DETAIL: integer versus smallint
db1=# alter table t2 alter a type int;
ALTER TABLE
db1=# create table t3 () inherits (t1,t2);
NOTICE: Table has parent, setting distribution columns to match parent table
NOTICE: merging multiple inherited definitions of column "a"
CREATE TABLEdb1=# create table t1(a int);
CREATE TABLE
db1=# create table t3 (a text) inherits (t1);
NOTICE: Table has parent, setting distribution columns to match parent table
NOTICE: merging column "a" with inherited definition
ERROR: column "a" has a type conflict
DETAIL: integer versus text
db1=# create table t3 (a int) inherits (t1);
NOTICE: Table has parent, setting distribution columns to match parent table
NOTICE: merging column "a" with inherited definition
CREATE TABLEdb1=# create table t1(a int default 1);
CREATE TABLE
db1=# create table t2(a int default 2) inherits (t1);
NOTICE: Table has parent, setting distribution columns to match parent table
NOTICE: merging column "a" with inherited definition
CREATE TABLE
db1-# \d t2
Append-Only Table "public.t2"
Column | Type | Modifiers
--------+---------+-----------
a | integer | default 2
...db1=# create table t1(a int) with (bucketnum=8) distributed by (a);
CREATE TABLE
db1=# create table t2 () inherits (t1);
NOTICE: Table has parent, setting distribution columns to match parent table
CREATE TABLE
db1=# \d t2
Append-Only Table "public.t2"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Inherits: t1
Distributed by: (a)
db1=# create table t3 () inherits (t1) with (bucketnum=8) distributed by (a);
CREATE TABLE
db1=# create table t4 () inherits (t1) with (bucketnum=16) distributed by (a);
ERROR: distribution policy for "t4" must be the same as that for "t1"
db1=# create table t4 (b int) inherits (t1) with (bucketnum=8) distributed by (b);
ERROR: distribution policy for "t4" must be the same as that for "t1"2. LIKE
LIKE子句指示新建表从另一个已经存在的表中复制所有列的名称、数据类型、非空约束,以及表的数据分布策略。如果原表中指定了bucketnum,而新表没有指定,则bucketnum将被复制,否则使用新表的bucketnum。象appendonly这样的存储属性,或者分区结构不会被复制。缺省值也不会被复制,新表中所有列的缺省值都是NULL。与INHERITS不同,新表与原始表是完全解耦的。
db1=# create table t1 (a int) with (bucketnum=8) distributed by (a);
CREATE TABLE
db1=# create table t2 (like t1);
NOTICE: Table doesn't have 'distributed by' clause, defaulting to distribution columns from LIKE table
CREATE TABLE
db1=# create table t3 (like t1) with (bucketnum=16) distributed by (a);
CREATE TABLE
db1=# select t1.*,t2.relname from gp_distribution_policy t1,pg_class t2
db1-# where t1.localoid=t2.oid and t2.relname in ('t1','t2','t3');
localoid | bucketnum | attrnums | relname
----------+-----------+----------+---------
43738 | 8 | {1} | t1
43743 | 24 | {1} | t2
43748 | 16 | {1} | t3
(3 rows)db1=# create table t1 (a int not null check (a > 0));
CREATE TABLE
db1=# create table t2 (like t1);
NOTICE: Table doesn't have 'distributed by' clause, defaulting to distribution columns from LIKE table
CREATE TABLE
db1=# \d t2
Append-Only Table "public.t2"
Column | Type | Modifiers
--------+---------+-----------
a | integer | not null
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Distributed randomly
db1=# create table t3 (like t1 including constraints);
NOTICE: Table doesn't have 'distributed by' clause, defaulting to distribution columns from LIKE table
CREATE TABLE
db1=# \d t3
Append-Only Table "public.t3"
Column | Type | Modifiers
--------+---------+-----------
a | integer | not null
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Check constraints:
"t1_a_check" CHECK (a > 0)
Distributed randomly3. AS
CREATE TABLE AS是很多数据库系统都提供的功能。它用一个SELECT查询命令的结果集创建新表并向新建的表填充数据。新表的列就是SELECT返回的列,也可以显式定义新表的列名。新表的存储参数和分布策略与原表无关。
db1=# create table t1 (a int);
CREATE TABLE
db1=# insert into t1 values (100);
INSERT 0 1
db1=# create table t2 (b) with --只定义列名,不能指定列的数据类型
db1-# (bucketnum=8,
db1(# appendonly=true,
db1(# blocksize=8192,
db1(# orientation=row,
db1(# compresstype=zlib,
db1(# compresslevel=1,
db1(# fillfactor=50,
db1(# oids=false)
db1-# as select * from t1
db1-# distributed by (b);
SELECT 1
db1=# select * from t2;
b
-----
100
(1 row)4. SELECT INTO
SELECT INTO在功能上与AS类似,也是从查询结果创建新表,但这种语法不能定义新表的存储选项和分布策略,而总是使用缺省值。
db1=# create table t1 (a int) with
db1-# (bucketnum=8,
db1(# appendonly=true,
db1(# blocksize=8192,
db1(# orientation=row,
db1(# compresstype=zlib,
db1(# compresslevel=1,
db1(# fillfactor=50,
db1(# oids=false)
db1-# distributed by (a);
CREATE TABLE
db1=# insert into t1 values (1);
INSERT 0 1
db1=# select * into t2 from t1;
SELECT 1
db1=# \d t2
Append-Only Table "public.t2"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: f
Distributed randomly
db1=# select * from t2;
a
---
1
(1 row)














 3036
3036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









