









源文档 <file:///E:\Edison\Books\Java\NIO\Java%20NIO(2)-缓冲区基础.docx>
缓冲区(Buffer)对象是面向块的I/O的基础,也是NIO的核心对象之一。在NIO中每一次I/O操作都离不开Buffer,每一次的读和写都是针对Buffer操作的。Buffer在实现上本质是一个数组,其作用是一个存储器,或者分段运输区,并且提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。对于传统的流I/O,这是一种设计上的进步。
为了方便理解,下面我会主要采用代码示例加注释的方式说明缓冲区比较重要的API和知识点。
缓冲区基础
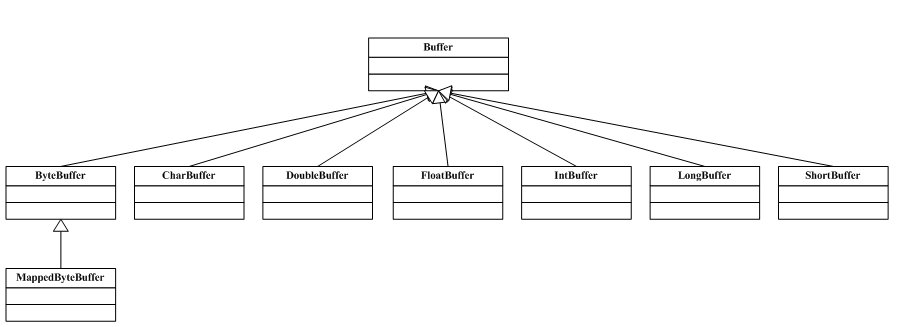
Buffer缓冲区的家谱如下图:
作为所有缓冲区类的父类,Buffer类的包含了下面4个重要属性,
// Invariants: mark <= position <= limit <= capacity
privateint mark = -1;
privateint position = 0;
privateint limit;
privateint capacity;
这4个属性指明了Buffer所包含的数据元素的信息。
@Test1
/**
*缓冲区4属性
* capacity容量: 能够容纳数据元素的最大数量,在缓冲区创建时指定并且不能更改。
* limit上界: 缓冲区第一个不能被读或写的元素索引,也就是数据的上限位置,这个位置以后即便有数据,也是不能够访问的。
* position位置: 缓冲区下一个读或写的元素索引。
* mark标记: 标记一个索引。调用mark()方法将会设定mark = position,调用reset()方法将设定position = mark。
*四者之间关系始终为 mark <= position <= limit <= capacity
*/
publicvoid testNewBuffer()
{
CharBuffer cb= CharBuffer.allocate(10);
//buffer初始设置
System.out.println(cb.capacity());//结果为10
System.out.println(cb.limit());//结果为10
System.out.println(cb.position());//结果为0
//mart初始值为-1
}
下面是缓冲区主要API列表:
publicabstract class BufferAPI
{
publicfinalint capacity();//返回capacity值
publicfinalint position();//返回position值
publicfinal Buffer position(int newPosition);//设置新的position值
publicfinalint limit();//返回limit值
publicfinal Buffer limit(int newLimit);//设置新的limit值
publicfinal Buffer mark();//标记位置 mark = position
publicfinal Buffer reset();//返回标记位置 position = mark
publicfinal Buffer clear();//重置缓冲区的属性到新建时的状态,不会清楚数据
publicfinal Buffer flip();//缓冲区翻转,用于读和写的切换
publicfinal Buffer rewind();//重置缓冲区position和mark属性
publicfinalint remaining();//返回缓冲区可读或写的元素数量
publicfinalboolean hasRemaining();//缓冲区是否还有可读或写的元素
publicabstractboolean isReadOnly();//缓冲区是否是只读的
}
需要注意的是有些方法的返回值是Buffer,它返回的是自身的引用,这是一个精巧的类设计,允许我们级联的调用方法。
@Test2级联
/**
* Buffer支持级联用法
*/
publicvoid testCascade()
{
ByteBuffer bb= ByteBuffer.allocate(10);
//正常调用
bb.mark();
bb.position(5);
bb.reset();
//级联调用
bb.mark().position(5).reset();
//上述2种方法是等价的,但无疑级联调用更加美观简洁
}
在上面的API中并没有看到存取的方法,这是因为存取的方法都定义在具体的子类中,从家谱图看出对于除了boolean类型的其他基本类型,缓冲区都实现了具体的子类。缓冲区本质是用数组来存放数据元素的,那么不同的类型需要建立不同的数组。
缓冲区的存取是通过put()和get()方法实现的,以ByteBuffer类为例,如下:
@Test3存取
/**
* buffer的存取
*/
publicvoid testPutGet()
{
/**
* buffer的存取都通过put和get方法,并且提供了两种方式:相对和绝对
*相对方式:put和get的位置取决于当前的position值,调用方法后,position值会自动加1。
*当put方法position大于缓冲区上限会抛出BufferOverflowException;同样
*当get方法position大于或等于缓冲区上限抛出BufferUnderflowException。
*绝对方式:put和get需要传入索引参数,调用方法后position值不会发生改变。当传入的索引值
*是负数或者大于等于缓冲区上界,抛出IndexOutOfBoundsException。
*/
ByteBuffer bb= ByteBuffer.allocate(8);
//相对put,position递增
bb.put((byte)'h').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o').put((byte)'!');
bb.flip();//翻转缓冲区,读写转换
//相对get position递增
while(bb.hasRemaining())
{
System.out.print((char)bb.get());//输出“hello!”
}
System.out.println();
//绝对put
bb.put(0, (byte)'a');
bb.put(1, (byte)'b');
bb.rewind();//重置position,一般用于重新读
//绝对get
for(int i=0; i<bb.remaining(); i++)
{
System.out.print((char)bb.get(i));输出“abllo!”
}
//重置缓冲区为空状态以便下次使用
bb.clear();
/**
*遍历缓冲区的两种方法
* 1.
* for(int i=0; bb.hasRemaining(); i++)
*允许多线程来访问缓冲区,每次都会检查缓冲区上界;
* 2.
* int count = bb.remaining();
* for(int i=0; i<count; i++)
*如果不存在多线程问题则会更加高效
*/
/**
*缓冲区也提供了批量存取的put和get方法
*/
}
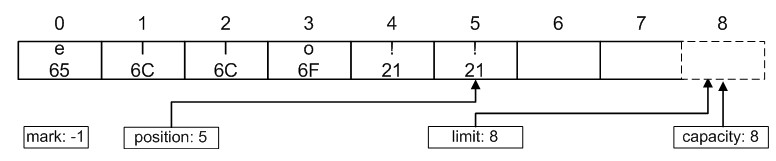
在@Test3中,缓冲区的属性以及数据元素的变化有必要详细说明下,初始化的缓冲区状态如下图:
向缓冲区中填充进“hello”字节码后,缓冲区的状态如下:
“hello”已经都在缓冲区里了,然后调用get方法读取数据,以缓冲区现在的状态执行绝对读操作是可以的,但是要执行相对读就是有问题的。我们希望的结果是把“hello”读取出来,但是当前的position位置在“hello”之外,一直读的结果就是读到上界然后抛出错误。
解决的方法很简单,在读之前把position置为0,并且把limit置为5,这样读取的区间正好在“hello”范围内。缓冲区API也封装了这个方法flip,用于读写之间的转换。flip后的缓冲区状态如下:
这样我们就可以顺利的读出缓冲区的内容。
@Test4压缩
/**
*缓冲区压缩
*压缩适用于这样的情况:缓冲区被部分释放后需要继续填充,
*此时剩下的未读数据需要向前移动到索引0的位置。
*通过源码可以看到compact()方法做了3件事:
* 1.将未读数据复制到缓冲区索引0开始的位置
* 2.将position设置为未读数据长度的索引位置
* 3.将limit设置为缓冲区上限
*/
publicvoid testCompact()
{
ByteBuffer bb= ByteBuffer.allocate(8);
bb.put((byte)'h').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o').put((byte)'!');
bb.flip();
bb.get();//释放部分数据
bb.compact();//压缩
bb.put((byte)'a');//继续填充数据
bb.flip();//压缩后如需读取,依然需要flip
while(bb.hasRemaining())
{
System.out.print((char)bb.get());//遍历结果: ello!a
}
}
上面的例子进行如下的图解,当调用bb.get()后,缓冲区的情况是这样的:
然后调用compact()方法后,缓冲区变成下面的情况:
@Test5缓冲区比较
/**
*比较两个缓冲区相等 有equals和compareTo方法
* equals方法成立的条件如下:
* 1.两个对象类型相同。包含不同数据类型的 buffer 永远不会相等,而且 buffer
*绝不会等于非 buffer 对象。
* 2.两个对象都剩余同样数量的元素。Buffer 的容量不需要相同,而且缓冲区中剩
*余数据的索引也不必相同。但每个缓冲区中剩余元素的数目(从位置到上界)必须相
*同。
* 3.在每个缓冲区中应被 Get()方法返回的剩余数据元素序列必须一致。
*简单的说就是比较当前position到limit区间的数据元素
*
* compareTo方法返回值-1,0,1
*针对每个缓冲区剩余元素进行比较,直到不相等的元素被发现或者到达缓冲区的上界。
*如果在一方达到上界还没有出现不相等的元素,元素个数少的缓冲区视为小。
*/
publicvoid testEqualsAndCompare()
{
ByteBuffer buffer1= ByteBuffer.allocate(8);
ByteBuffer buffer2= ByteBuffer.allocate(8);
buffer1.put((byte)'h').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');
buffer2.put((byte)'m').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o').put((byte)'w');
buffer1.position(0);
buffer2.position(0);
System.out.println("equals: " + buffer1.equals(buffer2));//结果false
System.out.println("compare: " + buffer1.compareTo(buffer2));//结果-1
//两个缓冲区设定区间比较
buffer1.position(1).limit(4);
buffer2.position(1).limit(4);
System.out.println("equals: " + buffer1.equals(buffer2));//结果true
System.out.println("compare: " + buffer1.compareTo(buffer2));//结果0
buffer1.put(1, (byte)'z');
System.out.println("equals: " + buffer1.equals(buffer2));//结果false
System.out.println("compare: " + buffer1.compareTo(buffer2));//结果1
}
缓冲区的创建和复制
缓冲区提供了几种创建的方式:
@Test6创建间接缓冲区
/**
*分配操作创建一个缓冲区对象并分配一个私有的空间来储存容量大小的数据元素。
*/
publicvoid testAllocate()
{
ByteBuffer bb= ByteBuffer.allocate(100); //这段代码隐含地从堆空间中分配了一个byte型数组作为备份存储器来储存100个byte变量。
}
@Test7包装缓冲区
/**
*包装操作创建一个缓冲区对象但是不分配任何空间来储存数据元素。
*它使用您所提供的数组作为存储空间来储存缓冲区中的数据元素
*/
publicvoid testWrap()
{
byte[] bytes =new byte[6];
ByteBuffer bb= ByteBuffer.wrap(bytes);
/**
*对缓冲区的修改会影响数组,对数组的修改同样会影响缓冲区的数据
*/
bb.put((byte)'h').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o').put((byte)'!');
bb.flip();
for(byte b : bytes)
{
System.out.print((char)b);//结果hello!
}
System.out.println();
bytes[0] = (byte)'a';//改变数组第0项
while (bb.hasRemaining())
{
System.out.print((char)bb.get());//结果aello!
}
/**
*带参数的包装方法
*/
ByteBuffer bp= ByteBuffer.wrap(bytes, 2, 2);
/**
*带参数的包装方法wrap(array, offset, length)并不意味着取数组的子集来作为缓冲区,
* offset和length属性只是设置了缓冲区初始状态;上面代码表示创建了posion为2,limit为4,
*容量为bytes.length的缓冲区
*/
}
@Test8间接缓冲区的备份数组
/**
*通过allocate和wrap方法创建的缓冲区都是间接缓冲区,
*间接缓冲区中使用备份数组,对于缓冲区备份数组java也提供了一些api
*/
publicvoid testBufferArray()
{
byte[] bytes =new byte[6];
ByteBuffer bb= ByteBuffer.wrap(bytes);
if(bb.hasArray())//hasArray()方法判断缓冲区是否有备份数组
{
byte[] byteArr = bb.array();//array()方法能够取得备份数组
System.out.println(bytes == byteArr);
System.out.println(bb.arrayOffset());//arrayOffset()方法返回缓冲区数据在数组中可以存储的开始位置
}
/**
*能够获得缓冲区的备份数组就获得了对缓冲区进行存取的权限,当缓冲区被设为只读的时候,
*无疑是不允许得到备份数组的。
*/
ByteBuffer bRead= bb.asReadOnlyBuffer();
System.out.println(bRead.hasArray());//输出为false
}
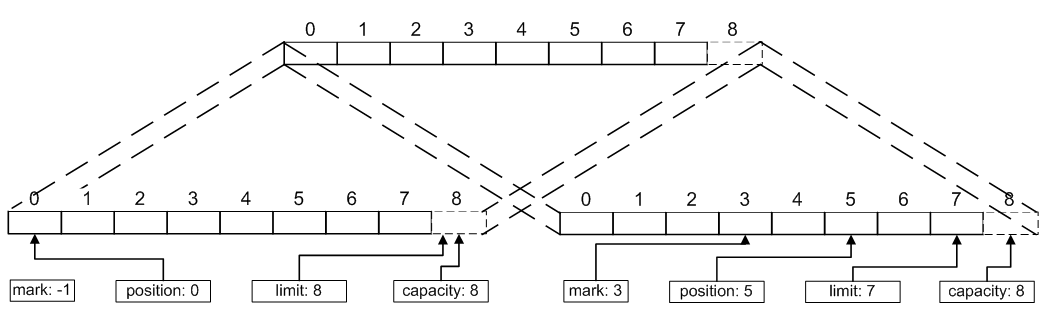
@Test9缓冲区的复制
/**
* Duplicate()方法创建了一个与原始缓冲区相似的新缓冲区,
*两个缓冲区共享数据元素,对一个缓冲区数据的修改将会反映在另一个缓冲区上,
*但每个缓冲区拥有自己独立的position、limit、mark属性,
*如果原始缓冲区是只读的或者直接缓冲区,复制的缓冲区将继承这些属性。
*/
publicvoid testDuplicate()
{
ByteBuffer orginal= ByteBuffer.allocate(8);
orginal.position(3).limit(7).mark().position(5);
ByteBuffer duplicate= orginal.duplicate();
orginal.clear();
System.out.println("orginal,position: " + orginal.position() +
"; limit: " + orginal.limit() +
"; mark: " + orginal.position());//结果 orginal,position: 0; limit: 10; mark: 0
System.out.println("duplicate,position: " + duplicate.position() +
"; limit: " + duplicate.limit() +
"; mark: " + duplicate.reset().position());//结果 duplicate,position: 5; limit: 8; mark: 3
//前面提到的asReadOnlyBuffer方法得到的只读缓冲区同duplicate类似
}
上例中原缓冲区和复制缓冲区的情况如下图:
@Test10缓冲区的分割
/**
* slice方法将对缓冲区进行分割,从原始缓冲区当前位置开始,直到上限
*也就是position到limit的区间创建了新的缓冲区,新缓冲区和原始缓冲区共享一段数据元素,
*也会继承只读和直接属性。
*/
publicvoid testSlice()
{
ByteBuffer orginal= ByteBuffer.allocate(10);
orginal.position(3).limit(8);
ByteBuffer slice= orginal.slice(); //分割了3-8的数据元素
}
上例分割后的缓冲区如下图:



















07-06
 632
632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









