







 本文详细介绍了MapReduce的设计理念,MapReduce1.0与2.0的架构,以及MapReduce的运行流程,包括Map阶段、Reduce阶段、shuffle过程和Partitioner阶段。通过WordCount程序展示了Map和Reduce的实现,最后讨论了MapReduce的常见应用场景。
本文详细介绍了MapReduce的设计理念,MapReduce1.0与2.0的架构,以及MapReduce的运行流程,包括Map阶段、Reduce阶段、shuffle过程和Partitioner阶段。通过WordCount程序展示了Map和Reduce的实现,最后讨论了MapReduce的常见应用场景。
一、概述
MapReduce的设计理念源自于Google的MapReduce论文(发表于2004年12月),Hadoop MapReduce是Google MapReduce克隆版。MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。
MapReduce1.0的架构如下:
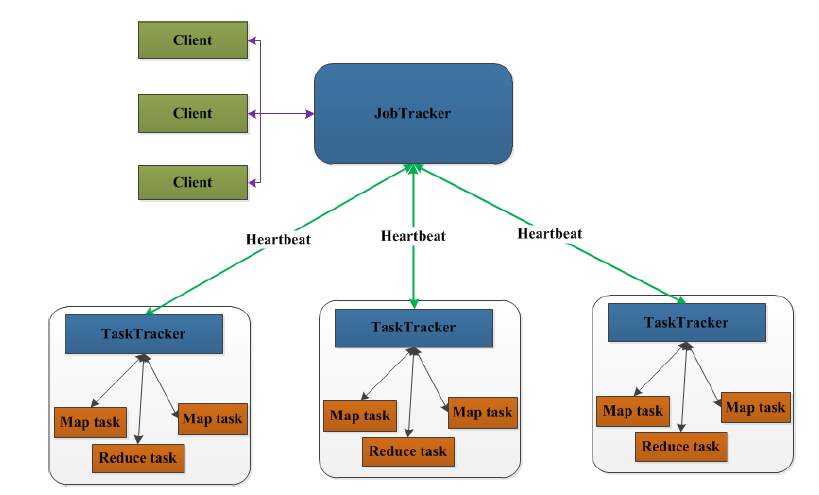
在Hadoop1.x中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
MapReduce2.0架构如下:
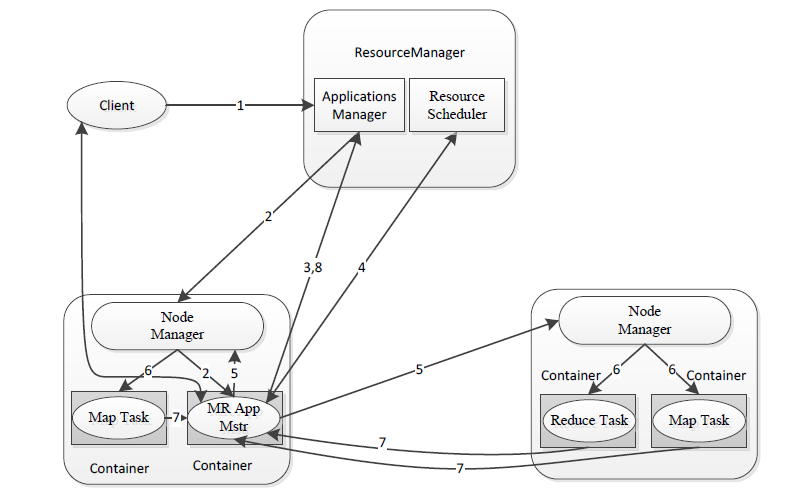
MapReduce2.0架构是在YARN架构的基础上运行,具体可参考上一篇关于YARN架构的介绍博文。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
二、MapReduce运行流程详解
MapReduce将作业的整个运行过程分为两个阶段:Map阶段Reduce阶段。
Map阶段由一定数量的Map Task组成,例如:
- 输入数据格式解析:InputFormat
- 输入数据处理:Mapper
- 本地规约:Combiner(相当于local reducer,可选)
- 数据分组:Partitioner
Reduce阶段由一定数量的Reduce Task组成,例如:
- 数据远程拷贝
- 数据按照key排序
- 数据处理:Reducer
- 数据输出格式:OutputFormat
通常我们把从Mapper输出数据到Reduce读取数据之间的过程称之为shuffle。
一个MapReduce的基本流程图如下:
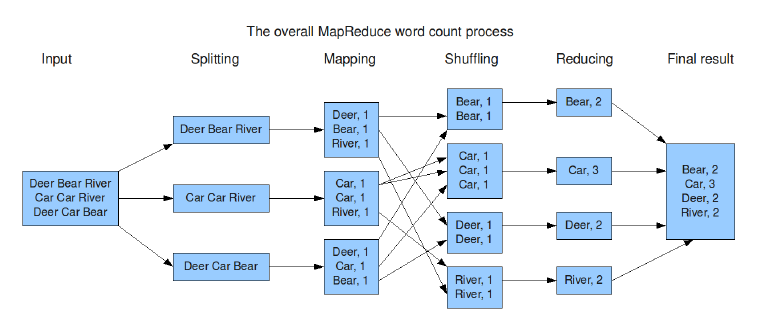
现在来结合hadoop提供的WordCount程序来对其执行流程进行详解。源码如下:(针对本地环境对源码作了一些修改)
package com.kang;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









