







 本文深入探讨MapReduce的实战应用,包括数据去重、排序、计算平均数、单表关联、多表关联和倒排索引等场景,通过案例解析MapReduce的工作原理和设计思路,帮助读者更好地理解和运用MapReduce处理大数据问题。
本文深入探讨MapReduce的实战应用,包括数据去重、排序、计算平均数、单表关联、多表关联和倒排索引等场景,通过案例解析MapReduce的工作原理和设计思路,帮助读者更好地理解和运用MapReduce处理大数据问题。
一、概述
前面关于MapReduce的wordcount程序已经做了比较详细的分析,这里再给出MapReduce应用的几个小案例,来更加深入的理解MapReduce的设计理念和应用方法。部分内容参考了书籍《hadoop实战》中的内容。
二、MapReduce应用之数据去重
在统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重这个操作。
1、情境要求
假设有如下两个数据样本file1.txt和file2.txt
file1.txt
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 cfile2.txt
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c我们需要将两个文件整合为一个文件并且去除其中重复的数据,最终结果应如下:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
2、思路解析
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。那么如果我们将同一个数据的所有记录都交给同一台机器做reduce,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是reduce的输入应该以数据作为key,而对value-list则没有要求。当reduce接收到一个
3、程序代码
package com.kang;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Duplicate {
// map将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object, Text, Text, Text> {
private static Text line = new Text();// 每行数据
// 实现map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
line = value;
context.write(line, new Text(""));
}
}
// reduce将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text, Text, Text, Text> {
// 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Duplicate");
job.setJarByClass(Duplicate.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("hdfs://sparkproject1:9000/root/input/"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://sparkproject1:9000/root/output/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
map的输入格式是<偏移量,行数据>的形式,类似<0,2012-3-1 a>。map操作我们直接把输入的value值作为输出的key,而输出的value值为空。map的输出格式就是<行数据,null>,例如<2012-3-1 a ,null>。因为我们设置了combine操作,所以map把输出传给reduce的时候进行了“本地reduce”,其作用是把当前map的输出中的重复数据去掉。然后传给reduce端,reduce端的作用就是把来自不同map的数据中重复的数据去掉。
4、结果展示
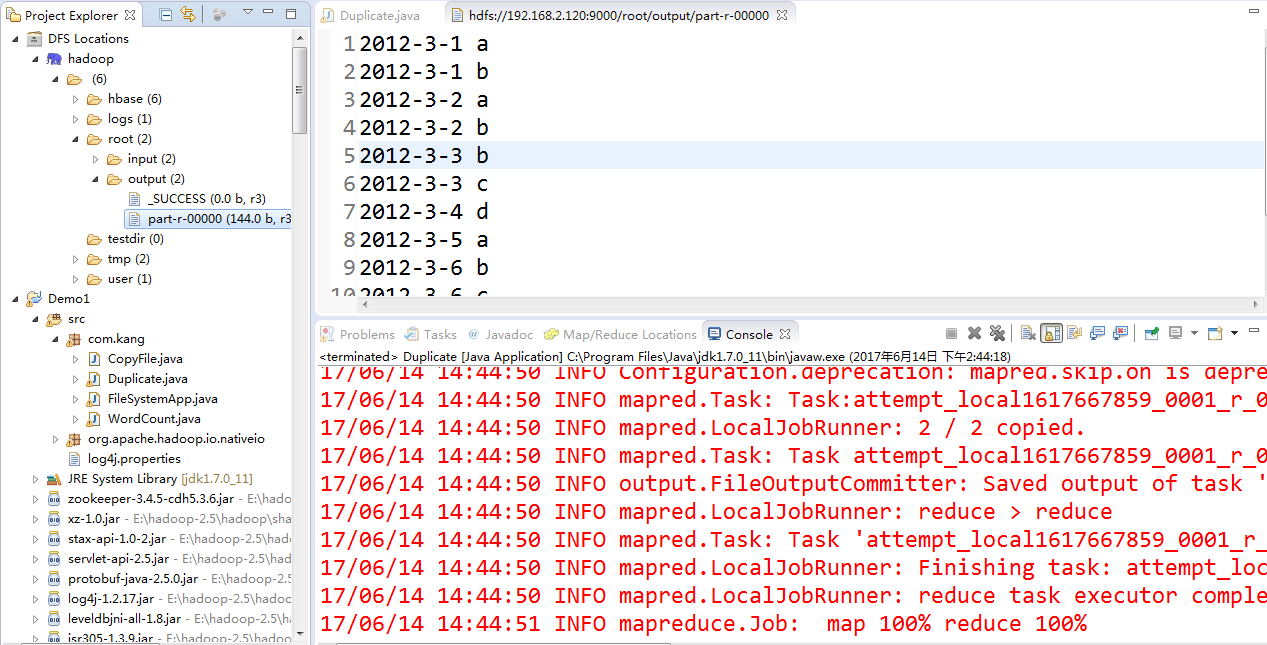
三、MapReduce应用之排序
数据排序是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。
1、情境要求
输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。
- 输入:
file1.txt
2
32
654
32
15
756
65223file2.txt
5956
22
650
92file3.txt
26
54
6我们需要将三个文件整合为一个文件并且排序,最终结果应如下:
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
2、思路解析
对输入数据进行排序,可以利用MapReduce框架中的默认排序,而不需要自己再实现具体的排序。首先需要了解MapReduce默认排序规则。它是按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String的Text类型,那么MapReduce按照字典顺序对字符串排序。
对本实例而言,在map中将读入的数据转化成IntWritable型,然后作为key值输出(value任意)。reduce拿到<key,value-list>之后,将输入的key作为value输出,并根据value-list中元素的个数决定输出的次数。输出的key(即代码中的linenum)是一个全局变量,它统计当前key的位次。需要注意的是这个程序中没有配置Combiner,也就是在MapReduce过程中不使用Combiner。这主要是因为使用map和reduce就已经能够完成任务了。
3、程序代码
package com.kang;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Sort {
// map将输入中的value化成IntWritable类型,作为输出的key
public static class Map extends Mapper<Object, Text, IntWritable, IntWritable> {
private static IntWritable data = new IntWritable();
// 实现map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
// reduce将输入中的key复制到输出数据的key上,
// 然后根据输入的value-list中元素的个数决定key的输出次数
// 用全局linenum来代表key的位次
public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private static IntWritable linenum = new IntWritable(1);
// 实现reduce函数
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
for (IntWritable val : values) {
context.write(linenum, key);
linenum = new IntWritable(linenum.get() + 1);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Sort");
job.setJarByClass(Sort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("hdfs://sparkproject1:9000/root/input/"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://sparkproject1:9000/root/output/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4、结果展示
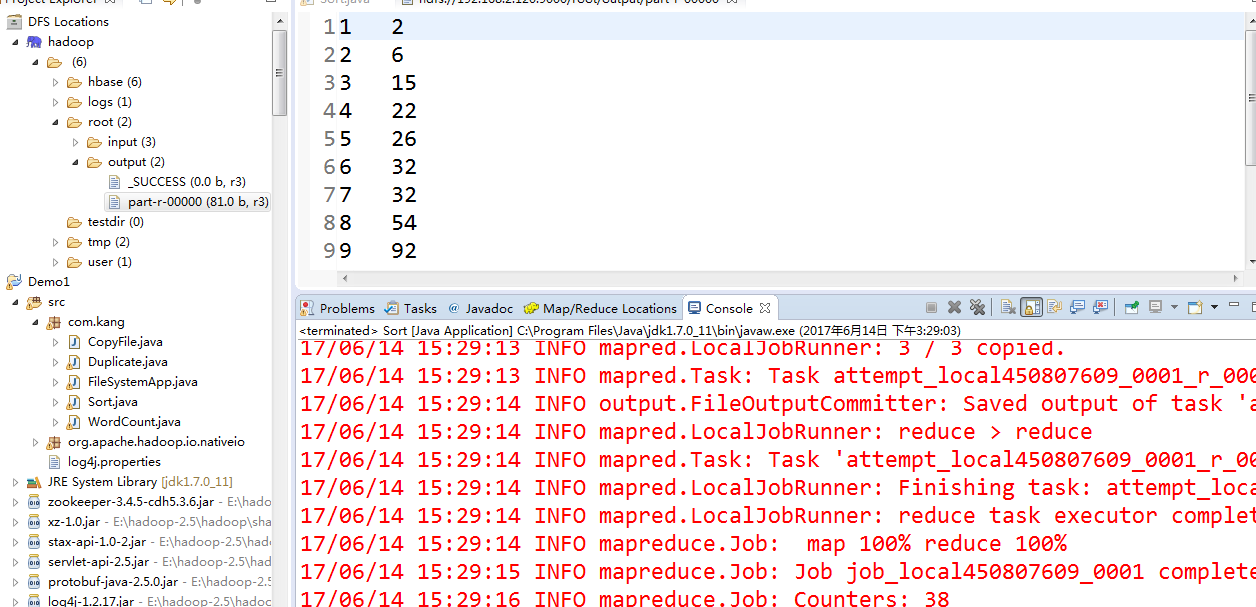
四、MapReduce应用之计算平均数
计算平均数在数据分析中是经常遇到的,这里来分析如何利用MapReduce实现。
1、情境要求
这里利用MapReduce来计算学生的平均成绩。 输入文件中的每行内容均为一个学生的姓名和他相应的成绩,如果有多门学科,则每门学科为一个文件。要求在输出中每行有两个数据,其中,第一个代表学生的姓名,第二个代表其平均成绩。
math.txt
张三 88
李四 99
王五 66
赵六 77china.txt
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









