







刚开始学习tf时,我们从简单的地方开始。卷积神经网络(CNN)是由简单的神经网络(NN)发展而来的,因此,我们的第一个例子,就从神经网络开始。
神经网络没有卷积功能,只有简单的三层:输入层,隐藏层和输出层。
数据从输入层输入,在隐藏层进行加权变换,最后在输出层进行输出。输出的时候,我们可以使用softmax回归,输出属于每个类别的概率值。借用极客学院的图表示如下:

写成向量乘积的形式如下:
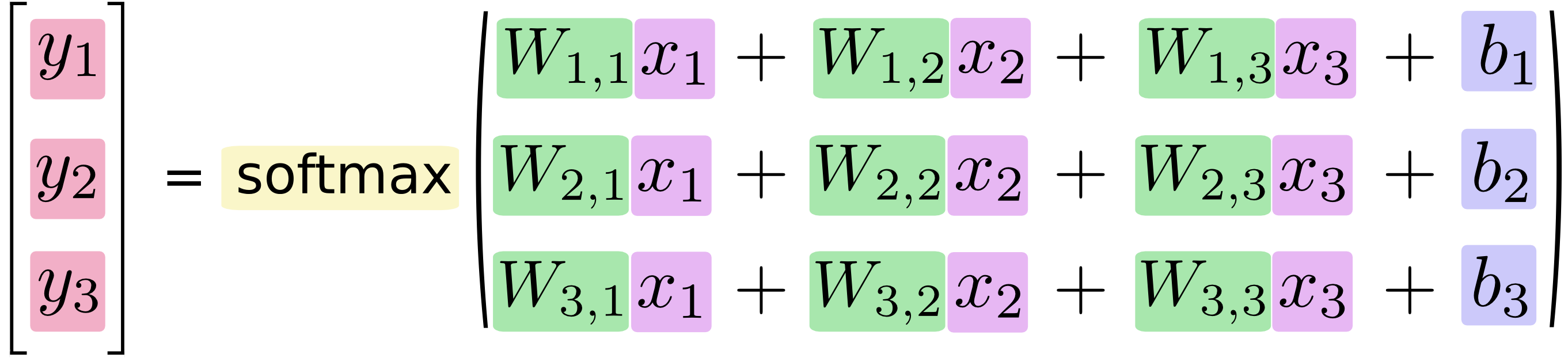
我们也可以把该过程矢量化,变成一个矩阵乘法和矩阵向量的加法。这有助于计算效率。
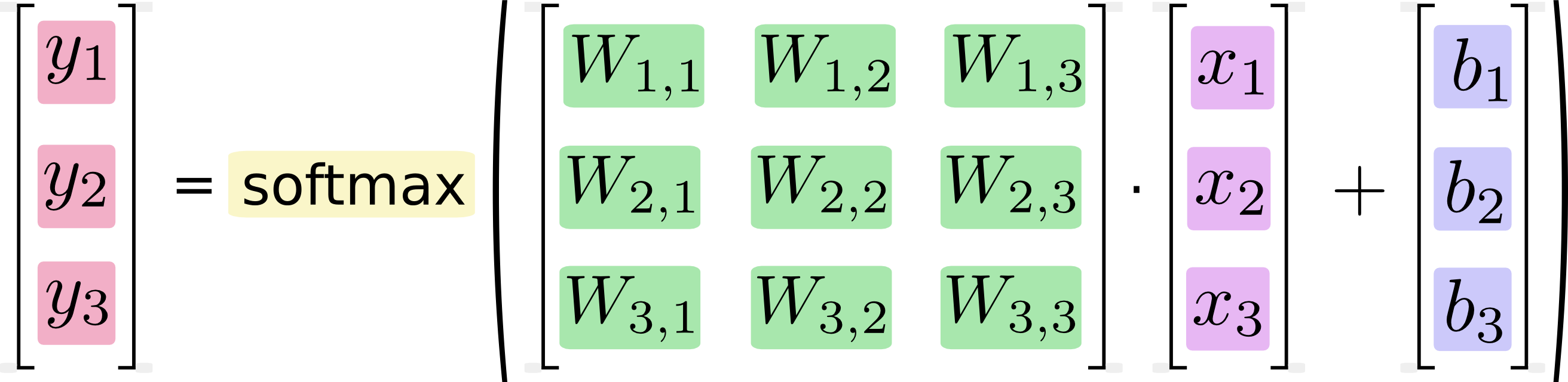
其中,x1,x2,x3为输入数据,经过运算后,得到三个数据属于某个类别的概率值y1,y2,y3. 用简单的公式表示如下:

在训练过程中,我们将真实的结果和预测的结果相比(交叉熵比较法),会得到一个残差。公式如下:

y 是我们预测的概率值, y' 是实际的值。这个残差越小越好,我们可以使用梯度下降法,不停地改变W和b的值,使得残差逐渐变小,最后收敛到最小值。这样训练就完成了,我们就得到了一个模型(W和b的最优化值)。
Implement the Regression
完整代码如下:

import tensorflow as tf
#导入input_data用于自动下载和安装MNIST数据集 import tensorflow.examples.tutorials.mnist.input_data as input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#放置占位符,用于在计算时接收输入值,每个为784维向量,下面的定义表示二维浮点数的一个张量,形状[无,784]这里没有一个维度可以任意长。 x = tf.placeholder(tf.float32, [None, 784])
#为了进行训练,需要把正确值一并传入网络 y_actual = tf.placeholder(tf.float32, shape=[None, 10])
#创建两个变量,分别用来存放权重值W和偏置值b,对于机器学习,一般模型的参数都是变量。 W = tf.Variable(tf.zeros([784,10])) #初始化权值W,这里的初始值为0 b = tf.Variable(tf.zeros([10])) #初始化偏置项b 初始值为0 y_predict = tf.nn.softmax(tf.matmul(x,W) + b) #加权变换并进行softmax回归,得到预测概率 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_actual*tf.log(y_predict),reduction_indies=1)) #求交叉熵
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) #用梯度下降法以0.01的学习率最小化交叉熵使得残差最小 correct_prediction = tf.equal(tf.argmax(y_predict,1), tf.argmax(y_actual,1)) #在测试阶段,测试准确度计算 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #多个批次的准确度均值 #初始化之前创建的变量的操作 init = tf.initialize_all_variables()
#启动初始化
with tf.Session() as sess:
sess.run(init)
#开始训练模型,循环1000次,每次都会随机抓取训练数据中的100条数据,然后作为参数替换之前的占位符来运行train_step for i in range(1000): #训练阶段,迭代1000次 batch_xs, batch_ys = mnist.train.next_batch(100) #按批次训练,每批100行数据 sess.run(train_step, feed_dict={x: batch_xs, y_actual: batch_ys}) #执行训练 if(i%100==0): #每训练100次,测试一次 print "accuracy:",sess.run(accuracy, feed_dict={x: mnist.test.images, y_actual: mnist.test.labels})
每训练100次,测试一次,随着训练次数的增加,测试精度也在增加。训练结束后,1W行数据测试的平均精度为91%左右,不是太高,肯定没有CNN高。
其中,本篇涉及到 交叉熵 的部分内容,具体详细内容可参考http://colah.github.io/posts/2015-09-Visual-Information/进行交叉熵的学习。(我还没有看)
另外,本篇其实实现了最基本的神经网络模型Softmax,其正确率大概有9502%,事实上相当糟糕,随着一些小的变化,我们的准确率可达到97%,欲了解更多信息,可以参考http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html该网址下的内容,其中总结了MNIST数据集上的多种模型及其相关论文。(PS:我也还没看!!)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









