







自定义排序1:
| object CustomSort1 {
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("CustomSort1").setMaster("local") val sc: SparkContext = new SparkContext(conf)
val users = Array("laoduan 30 99","kaozhao 29 9999","laoyang 28 99") //按照颜值从高到低,颜值相等时,年龄从小到大 val lines = sc.parallelize(users) val userRDD = lines.map(line => { val fields = line.split(" ") val name = fields(0) val age = fields(1).toInt val fv = fields(2).toInt (name, fv, age) }) val sorted = userRDD.sortBy(tp => new User(tp._1,tp._2,tp._3)) println(sorted.collect().toBuffer) sc.stop() } } class User(val name:String,val fv: Int,val age: Int)extends Ordered[User] with Serializable{ override def compare(that: User): Int = { if (this.fv==that.fv){ this.age-that.age }else{ -(this.fv-that.fv) } } } |
结果:
| ArrayBuffer((kaozhao,9999,29), (laoyang,99,28), (laoduan,99,30)) |
自定义排序2:
| (name, fv, age) val sorted = userRDD.sortBy(tp => (-tp._2,tp._3)) |
自定义排序3:
补充:
| val words =Array("spark","hadoop","hive") val wordsRDD=sc.parallelize(words) val r1=wordsRDD.keyBy(_.length) println(r1.collect().toBuffer) |
结果:ArrayBuffer((5,spark),(6,hadoop), (4,hive))
| (name, fv, age) implicit val rules=Ordering[(Int,Int)].on[(String,Int,Int)](o =>(-o._2,o._3)) val sorted = userRDD.sortBy(u => u) |
| new User(name, fv, age) implicit val orderRules= new Ordering[User]{ override def compare(x: User, y: User): Int = { if(x.fv==y.fv){ x.age-y.age }else{ y.fv-x.fv } } } val sorted = userRDD.sortBy(u => u) class User(val name:String,val fv: Int,val age: Int)extends Serializable{ override def toString: String = s"name: $name fv: $fv age: $age" } 结果:ArrayBuffer(name: kaozhao fv: 9999 age: 29, name: laoyang fv: 99 age: 28, name: laoduan fv: 99 age: 30) |
全局排序和RangePartitioner
Spark任务总体过程总结
| 1、创建SparkContext 2、创建RDD 3、调用RDD和Transformation 4、调用Action 5、生成一个完整的DAG 6、DAG根据宽依赖切分Stage 7、提交Stage,先提交前面的Stage,一个Stage中可以有多个Task,task的数量取决于该阶段RDD的分区数量,前面的stage执行完,执行后面的stage |
RDD的总结
| RDD是spark中一个最基本的抽象(RDD不是一个真正的集合,里面不装真正的数据),它代表了一个弹性、可复原、分布式的数据集 RDD里面可以有多个分区,一个分区会生成一个Task,在一个Stage中,可以有多个Task,Task的业务逻辑都相同,只不过是处理的数据不同 你对RDD进行操作,其实就是对每个分区进行操作,而分区会被转换成Task,对输入切片进行操作(你操作RDD就像操作一个本地集合一样,不同关心底层的细节,可以将RDD认为是一个代理) |
线程池介绍:
| public class ThreadPoolDemo {
|
Spark任务整体执行过程
SparkSubmit:创建SparkContext时就已经跟Master建立链接了,然后Master让worker启动Executor
创建RDD,并调用RDD的方法,当调用RDD的Action时,会切分stage,生成多个Task,然后将TaskSet提交给TaskScheduer,然后再将Task序列化,通过网络发送给Executor第一个Stage有8个分区,会生成8个Task。
Task是在Driver端生成的,Driver会将生成的Task先序列化,然后通过网络将Task方法给属于该任务的Executor,Executor接收后,将Task反序列化,然后用一个实现了Runable接口的实现类将Task包装了一层,接下来将该包装类的实例放到线程池中。
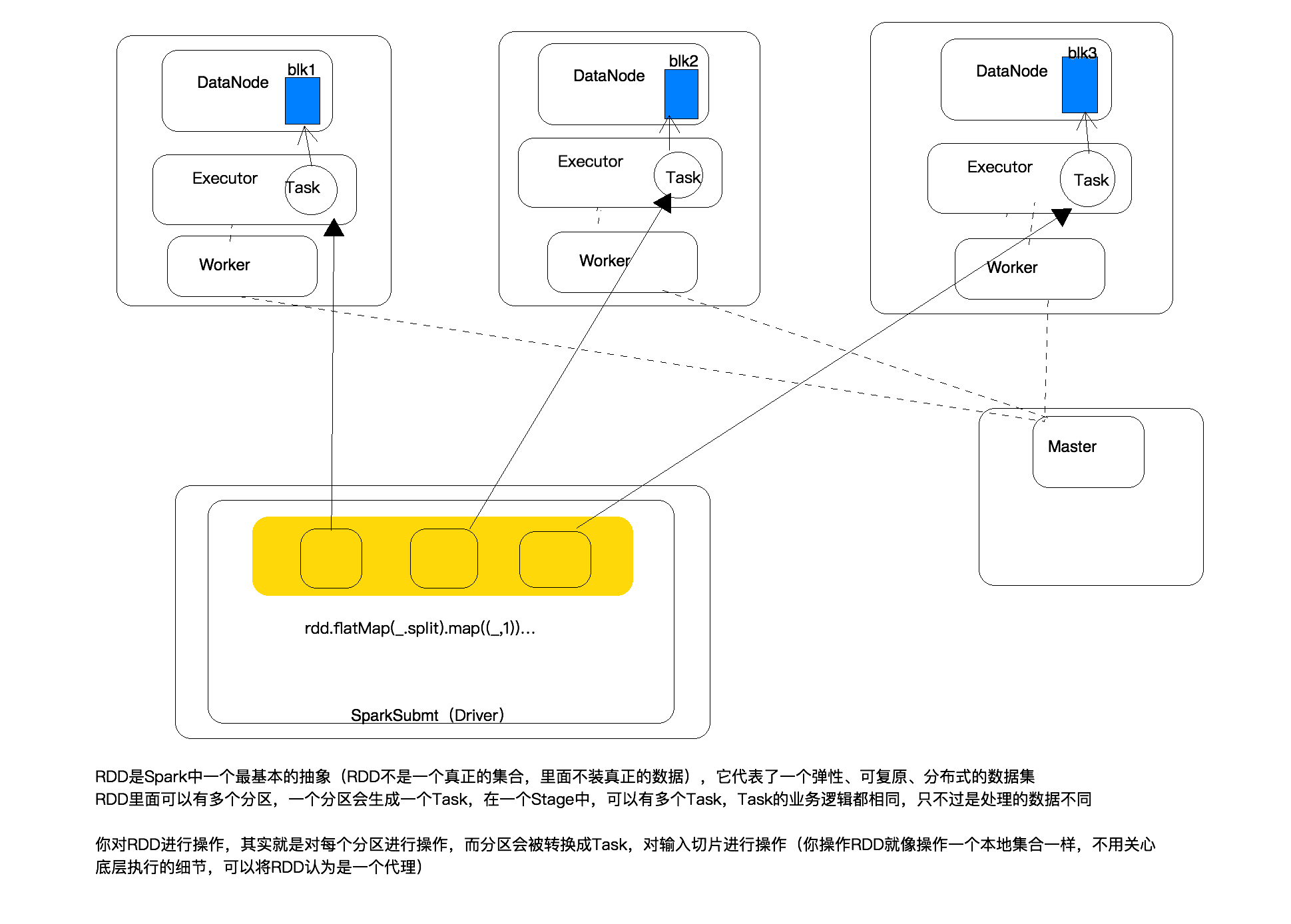

Spark各个组件初始化时机















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









