







1、线性回归(linear regression):
a、
单变量线性回归univariate linear regression:
形式:
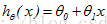
关键是怎么选择模型的参数
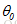 ,
,
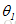 :
应该是使得
:
应该是使得 尽可能/无限 接近训练样本(x,y)中的y值,也就是最小化问题:
尽可能/无限 接近训练样本(x,y)中的y值,也就是最小化问题:
,
:
应该是使得尽可能/无限 接近训练样本(x,y)中的y值,也就是最小化问题:
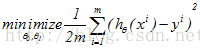 <——
线性回归的整体目标函数
<——
线性回归的整体目标函数
其中,i 表示第i个样本;m 表示训练样本数量。
令
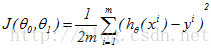 ,那么,我们要做的便是使得
,那么,我们要做的便是使得
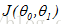 最小化:
最小化:
现在,我们的目标是
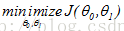 ,假设有一组训练集数据(1,1),(2,2),(3,3)那么,假设
,假设有一组训练集数据(1,1),(2,2),(3,3)那么,假设
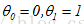 ,则有
,则有
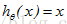 ,
,
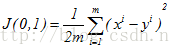 ,此时,不难算出
,此时,不难算出
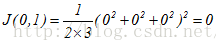 而,不断改变的
而,不断改变的
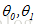 值则会得到不同的
J
值,当取到最小值或局部最小值
J
时的
,
参数则是我们要的。
值则会得到不同的
J
值,当取到最小值或局部最小值
J
时的
,
参数则是我们要的。
,
参数则是我们要的。
梯度下降算法(gradient descent algorithm)可以实现代价函数最小化:
这里讲述使用梯度下降算法解决
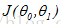 最小化(当然,梯度下降算法也可以解决
最小化(当然,梯度下降算法也可以解决
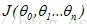 ):
):
主要步骤:
- star with some
- 不停的,一点点改变的
repeat until convergence {
}
###即反复更新
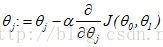 直到收敛。
直到收敛。
###注意:此
:=为赋值运算符;
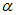 为learning rate,学习速率(在梯度算法中,其控制了更新值/更改值的每次变化的大小,
即以多大的幅度更新参数);
为learning rate,学习速率(在梯度算法中,其控制了更新值/更改值的每次变化的大小,
即以多大的幅度更新参数);
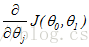 为微分项,
也就是曲线上点的斜率。
为微分项,
也就是曲线上点的斜率。
由上可知,梯度算法其实主要是不断更新
:=
-
![]() 某某;
:=
- 某某~:
某某;
:=
- 某某~:
:=
-
:=
- 某某~:
令temp0
:=
-
-
temp1
:=
-
-
:= temp0
:= temp1
接下来以
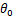 =0为例了解学习速率
∝ 和微分项(导数项,此处为偏导)
=0为例了解学习速率
∝ 和微分项(导数项,此处为偏导)

![]() J(
J(
 ):
):
当
=0时,
J(
) 即为
 ,那么,只要不断更新
temp1 :=
,那么,只要不断更新
temp1 := - ∝ J(), := temp1
- ∝ J(), := temp1
- ∝ J( := temp1
|
(x , y)
|
( |

|
|
(1 , 1)
|
0
|
2.33
|
|
(2 , 2)
|
0.5
|
0.583
|
|
(3 , 3)
|
1
|
0
|
|
…
|
2
|
2.33
|
|
(n , n)
|
…
|
…
|
此时,
J(
)的曲线应该是一条曲线,如下:
)的曲线应该是一条曲线,如下:

当
![]() = 4时,由图可以看出
= 4时,由图可以看出
![]() J(
J(
![]() )>0,因此要使得
temp1 := - ∝ J(
)>0,因此要使得
temp1 := - ∝ J(![]() )变小,应该往斜率更加趋向平缓的方向移动,也就是向左移动;
)变小,应该往斜率更加趋向平缓的方向移动,也就是向左移动;
= 4时,由图可以看出
- ∝ J(
当![]() = -4时,由图可以看出
J(
= -4时,由图可以看出
J(![]() )<0,
因此要使得
temp1 := - ∝ J(
)<0,
因此要使得
temp1 := - ∝ J(![]() )变小,应该向右移动。
)变小,应该向右移动。
J( J(
而
∝
则是控制移动的幅度大小:幅度过大可能会导致找不到最优解,而幅度过小则会加长计算的时间。
由上图可知,当导数项为0,![]()
![]() :=
:= ![]() -∝ * 0 得到最优解,此时的则应该是我们要找的参数了。
-∝ * 0 得到最优解,此时的则应该是我们要找的参数了。
:=
下面,简要讲一下微积分项也就是偏导计算:
repeat until convergence {
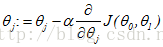 (for j = 0 and j = 1)
(for j = 0 and j = 1)
}
——>微分项计算过程为:
因此,梯度下降算法代码具体应为:
repeat until convergence {
小结:线性回归主要是找到拟合的
函数,其关键在于参数计算,此时利用cost function,例如
平方误差代价函数,可以很好地刻画出如何找到理想的参数(即代价函数图像的最低点或是局部最低点处的参数值),而使用
梯度下降算法则是可以很好地,有效率地实现cost function的计算过程(通过偏导,即斜率大小确定寻找方向和更新参数值直到收敛),进而找到想要的参数的值。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









