







一、编码方式
说编码之前,先扯个淡!大家都知道计算机只能识别1和0,编码就是将不同的符号与1和0的组合进行一下映射,做到能够表示哪个组合能够对应那个字符,由于早期的不能预料到未来的情况,后续互联网扩张后又要做到兼容,就出现了五花八门的编码。还值得一说的是计算机的处理一般面向字节或者字,位的操作也应该是通过对字节处理来模拟的。编码的长度一般都以字节来算。
学习C语言的同学最刚开始接触到最早的应该是ASCII,它用七位来表示字符,把一些通用符号和英文字母做了编码,在纯英文的环境下够用了。在计算机中用一个字节(八位)进行表示,高位的一个零是多余的。(好像后来想办法利用了这个零,这个待查)
但是到了其它的文字体系,比如中文,日文,泰文之类的就没法正常表示了。于是便在它的基础上进行了扩充,编码使用一到四个字节。扩展出来的大家都有共通点,兼容前面的ASCII。大家都属于一个体系的,取个名字叫ANSI好了。像中文的gbk,big5都是属于这一个系列的。到了这里,细思极恐,要是有个编码 0x4545这样的,在不同的编码环境下有不同的编码格式,这样就没法做到兼容了啊有木有。比如计算机A采用是gbk编码的,计算机B采用Shift-JIS编码,A写了文档发给计算B,计算机B打开一看,懵逼了,乱码!!!虽然大家都ANSI标准的,但是编码的具体实现不一样,这就是不兼容了。
OK,乱七八糟的东西大家受够了,这个unicode标准闪亮登场,威武霸气的unicode叫万国码,目的是要二个字节表示世界上的所有字符(usc-2),这个时候所表示的就是常说的基本面0。理想是美好的,现实是残酷的,二个字节能表示2的16次方个字符,也就是65536个字符,这数量不够啊有木有。于是unicode进行拓展变成了四个字节(usc-4),这下总该够了。OK,确实是够了。(ucs 与unicode 有不同组织维护,后来兼容设计后,差不多了,不用知道这些些细节,理解是怎么回事就好)下面来看看具体的表示方式。
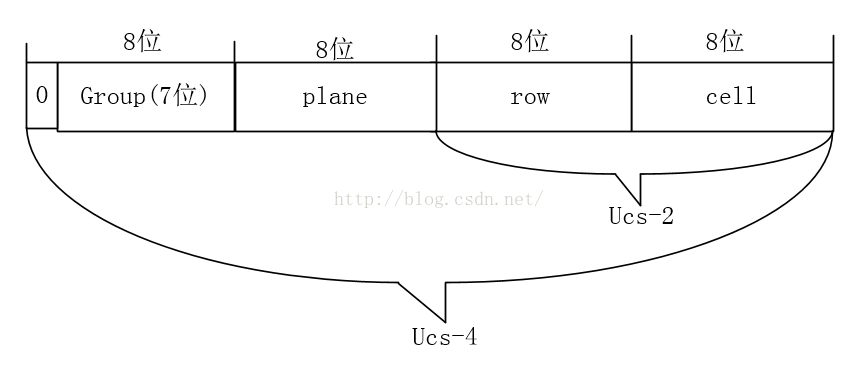
可以看到的是ucs-4这个东东才是真正意义可以表示所有字符的万国码
查看其格式的定义,第一个字节的首位固定为0,后面的7位表示128个组,每个组又有256个面,每个面可以表示65536个字符。
其总表示的范围为00000000 - 7FFFFFFF
0组0面的字符集合被称为BMP(Basic Multilingual Plane)
其中平面15和平面16上只是定义了两个各占65534个码位的专用区(Private Use Area),分别是0xF0000-0xFFFFD和0x100000-0x10FFFD。所 谓专用区,就是保留给大家放自定义字符的区域,可以简写为PUA
平面0也有一个专用区:0xE000-0xF8FF,有6400个码位。平面0的0xD800-0xDFFF,共2048个码位,是一个被称作代理区(Surrogate)的特殊区域。代理区的目的用两个UTF-16字符表示BMP以外的字符。
按照上面的编码方式,世界上所有的字符都有对应的码,万事大吉!这个时候有人不高兴了,尤其是英语为母语的国家。然后搞web开发的也表示不服气。为啥?因为太浪费了,纯英文的环境所需要表示的字符比较少,一个两个字节可以搞定的事情却都需要四个字节来表示,太不友好了,而且,如何是web程序开发中程序的编程多是英文,即使是要显示中文的网站,其中文字符也很少,80%以上的是英文字符,都采用四个字节对存储和传输都不方便。于是,在具体的实现过场并不直接使用编码表中的对应的值,产生了不同实现方式utf-8,utf-16,utf-32。
这里要先提及一个概念,每个真正的unicode符号所对应的是一个代码点,每种编码方式中最小的编码长度成为代码单元。如utf-8的代码单元长度为一个字节,utf-16的代码单元长度为二个字节。每个代码点由一个或者多个代码单元组成。
utf-8的实现unicode的字符集的对应关系。(图来自百度百科)

图中需要注意的进制不一样,后面的x指定是未知数。实际的使用过场中,英语字母在utf-8中只占用一个字节,汉字占用二个以上的字节。这对英文来说绝对的有利,大大的减少了所占存储空间。这就是为什么用这个的比较多的原因了。其中到目前未知已经定义了字符所占的范围为00000000-001FFFFF,也就是说到目前为有意思的面只有16个面,utf-8出现的也最多会出现四个字节的编码。
utf-16的代码单元是二个字节。如果unicode编码的代码点的值小于0x10000。字符集中对应的值是多少那么其utf-16编码的值也是多少,这个时候表示是基本字符集。
如果utf-16需要表示超过了二个字节对应unicode编码,就需要四个字节了。这个多出来的字符集一般叫增补字符集。基本字符中的0xD800-0xDFFF这个区间的值没有用的,这个用来表示编码超出了基本字符集。每个超出了基本字符集的编码表示都是这样的形式表示:
高位替代+一个字节编码+低位替代+一个字节编码
其中高位替代和低位替代的范围为:

utf-32,,这都已经四个字节了,完全可以跟unicode中的每个字符都对应上了。unicode字符集中对应的值是多少,utf-32的值也是多少。
总结下:
编码字符集的标准有两个ANSI和Unicode,ANSI每个国家有自己的实现,其编码与使用区域挂钩。unicode为表示现在已知的任何符号,但是为了传输和存储方便,产生了不同的实现方式utf-8,utf-16,utf-32
二、编码方式的判断
在window的操作系统下,给你个.txt的文本,你去打开!不知道编码格式,对应错了就是一堆乱码。这个时候有了一个东西叫BOM,英文名是ByteOrderMark,用它来表示当前这个文本格式,其对应的关系如下(图来自于百度百科)。
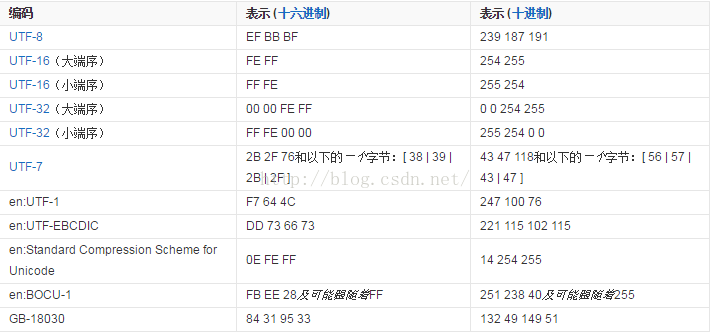
大端序号和小端序是只是当有两个字节的才有用。大端方式将高位存放在低地址,小端方式将高位存放在高地址。采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
通过notepad++随便写入一个汉字,然后设置编码格式为带BOM的utf-8。再用ultraedit以十六进制的方式打开文件,就可以看到文件的最前面有EFBBBF了。
网上有个用java写的判断代码
static String getFileEncodeStyle(){
BufferedInputStream bin = null;
int p = 0;
String code = null;
try {
bin = new BufferedInputStream(new FileInputStream("nio-data.txt"));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
bin = null;
}
if (bin != null) {
try {
p = (bin.read() << 8) + bin.read();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
switch (p) {
case 0xefbb:
code = "UTF-8";
break;
case 0xfffe:
code = "Unicode";
break;
case 0xfeff:
code = "UTF-16BE";
break;
default:
code = "GBK";
}
try {
bin.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("encode style : "+ code);
return code;
}其实这个代码是不完全正确的。它的不完善点在于所有没有BOM的就认为是gbk。其实不是的,在没有BOM标识来识别文件的时候,文件的编码应该是ANSI或者不带BOM utf-8。utf-8有明确的规则,可以通过提取部分字节来抽查的方式来试探,看看其是否都符合utf-8的规则,这种方法是有失败概率的,抽取的样本不好的情况可能就误认不是utf-8了。如果不是不带BOM的utf-8,那么应该认为其是系统window系统默认的ANSI的一种具体实现,这也是有失败的可能,因为文本的编码可能来自于其它的ANSI的编码方案。这就是为啥有时候字符处理要注意编码格式了,确实有够呛。
上面说的微软家的事默认的编码是ANSI的一种实现,比如操作系统的语言为中文简体,其对应的编码是就gbk了,命令行输入chcp可以看到活动页为936的结果。但是linux上默认是utf-8。头大...有问题的地方望指点。
===2017.1.5补充
网上有这样一个例子
String str = "学java";
byte[] bytes = str.getBytes();
System.out.println("bytes.length"+bytes.length);在eclipse下,window->Preferences->wokspace 下设置的Text file encoding 为gbk时,结果为6,选择为utf-8时结果7
追踪getByte是()方法,可以看到起这样的一句话String csn = Charset.defaultCharset().name();继续往下看,其默认的编码格式为系统绑定,现在看来为其编辑文本的格式。事实上getBytes()是可以带参数的,getByte("utf-8")或者getBytes("gbk")等。查看默认编码格式,也可以查看String csn2 = System.getProperty("file.encoding");
那str.lenght()本身是长度是什么呢?据API上描述,其表示是编码单元的数量,上面实际返回的结果是5。String本身是由字符数组来表示的,而java的char默认是二个字节编码的utf-16。所以返回5是合理的。














 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









